sync code from commit ef184dd6b06bcbce8f9ec35a5811ce2a6254b43b
This commit is contained in:
parent
8948b02af6
commit
1bfb7568ea
|
|
@ -0,0 +1,28 @@
|
||||||
|
# Python
|
||||||
|
__pycache__/
|
||||||
|
*.pyc
|
||||||
|
*.pyo
|
||||||
|
*.pyd
|
||||||
|
*.pyi
|
||||||
|
*.pyw
|
||||||
|
*.egg-info/
|
||||||
|
dist/
|
||||||
|
build/
|
||||||
|
*.egg
|
||||||
|
*.eggs
|
||||||
|
*.whl
|
||||||
|
|
||||||
|
# Virtual Environment
|
||||||
|
venv/
|
||||||
|
env/
|
||||||
|
ENV/
|
||||||
|
|
||||||
|
# IDE
|
||||||
|
.vscode/
|
||||||
|
*.code-workspace
|
||||||
|
*.idea
|
||||||
|
|
||||||
|
# Miscellaneous
|
||||||
|
*.log
|
||||||
|
*.swp
|
||||||
|
.DS_Store
|
||||||
|
|
@ -0,0 +1,200 @@
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "{}"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright {yyyy} {name of copyright owner}
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
|
|
@ -1,20 +1,21 @@
|
||||||
## 什么是 JYCache for Model?
|
|
||||||
|
|
||||||
JYCache for Model (简称 "jycache-model") 目标成为一款“小而美”的工具,帮助用户能够方便地从模型仓库下载、管理、分享模型文件。
|
# 什么是 HuggingFace FS ?
|
||||||
|
|
||||||
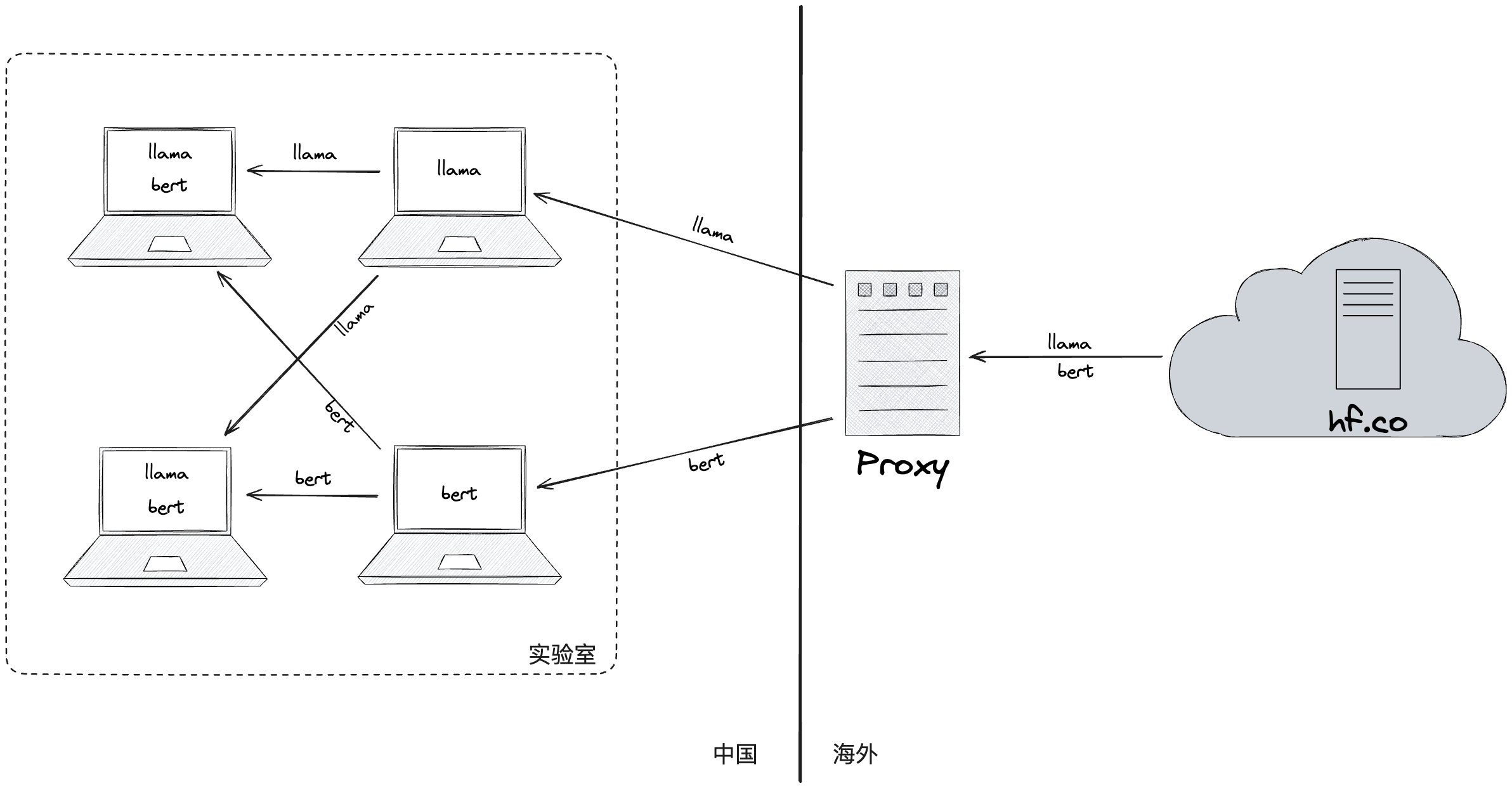
通常,模型文件很大,模型仓库的网络带宽不高而且不稳定,有些模型仓库需要设置代理或者使用镜像网站才能访问。因此,用户下载模型文件的时间往往很长。jycache-model 提供了 P2P 的模型共享方式,让用户能够以更快的速度获得所需要的模型。
|
HuggingFace FS (简称 "HFFS") 目标成为一款“小而美”的工具,帮助中国大陆用户在使用 [HuggingFace](huggingface.co) 的时候,能够方便地下载、管理、分享来自 HF 的模型。
|
||||||
|
|
||||||
|
中国大陆用户需要配置代理服务才能访问 HuggingFace 主站。大陆地区和 HuggingFace 主站之间的网络带宽较低而且不稳定,可靠的镜像网站很少,模型文件又很大。因此,下载 HuggingFace 上模型文件的时间往往很长。HFFS 在 hf.co 的基础上增加了 P2P 的模型共享方式,让大陆地区用户能够以更快的速度获得所需要的模型。
|
||||||
|
|
||||||
jycache-model 的典型使用场景有:
|

|
||||||
|
|
||||||
|
HFFS 的典型使用场景有:
|
||||||
|
|
||||||
- **同伴之间模型共享**:如果实验室或者开发部门的其他小伙伴已经下载了你需要的模型文件**,HFFS 的 P2P 共享方式能让你从他们那里得到模型,模型的下载速度不再是个头疼的问题。当然,如果目标模型还没有被其他人下载过,jycache-model 会自动从模型仓库下载模型,然后你可以通过 jycache-model 把模型分享给其他小伙伴。
|
- **同伴之间模型共享**:如果实验室或者开发部门的其他小伙伴已经下载了你需要的模型文件**,HFFS 的 P2P 共享方式能让你从他们那里得到模型,模型的下载速度不再是个头疼的问题。当然,如果目标模型还没有被其他人下载过,jycache-model 会自动从模型仓库下载模型,然后你可以通过 jycache-model 把模型分享给其他小伙伴。
|
||||||
- **机器之间模型传输**:有些小伙伴需要两台主机(Windows 和 Linux)完成模型的下载和使用:Windows 上的 VPN 很容易配置,所以它负责下载模型;Linux 的开发环境很方便,所以它负责模型的微调、推理等任务。通过 jycache-model 的 P2P 共享功能,两台主机之间的模型下载和拷贝就不再需要手动操作了。
|
- **机器之间模型传输**:有些小伙伴需要两台主机(Windows 和 Linux)完成模型的下载和使用:Windows 上的 VPN 很容易配置,所以它负责下载模型;Linux 的开发环境很方便,所以它负责模型的微调、推理等任务。通过 jycache-model 的 P2P 共享功能,两台主机之间的模型下载和拷贝就不再需要手动操作了。
|
||||||
- **多源断点续传**:浏览器默认不支持模型下载的断点续传,但是 jycache-model 支持该功能。无论模型文件从哪里下载(模型仓库或者其他同伴的机器),jycache-model 支持不同下载源之间的断点续传。
|
- **多源断点续传**:浏览器默认不支持模型下载的断点续传,但是 jycache-model 支持该功能。无论模型文件从哪里下载(模型仓库或者其他同伴的机器),jycache-model 支持不同下载源之间的断点续传。
|
||||||
|
|
||||||
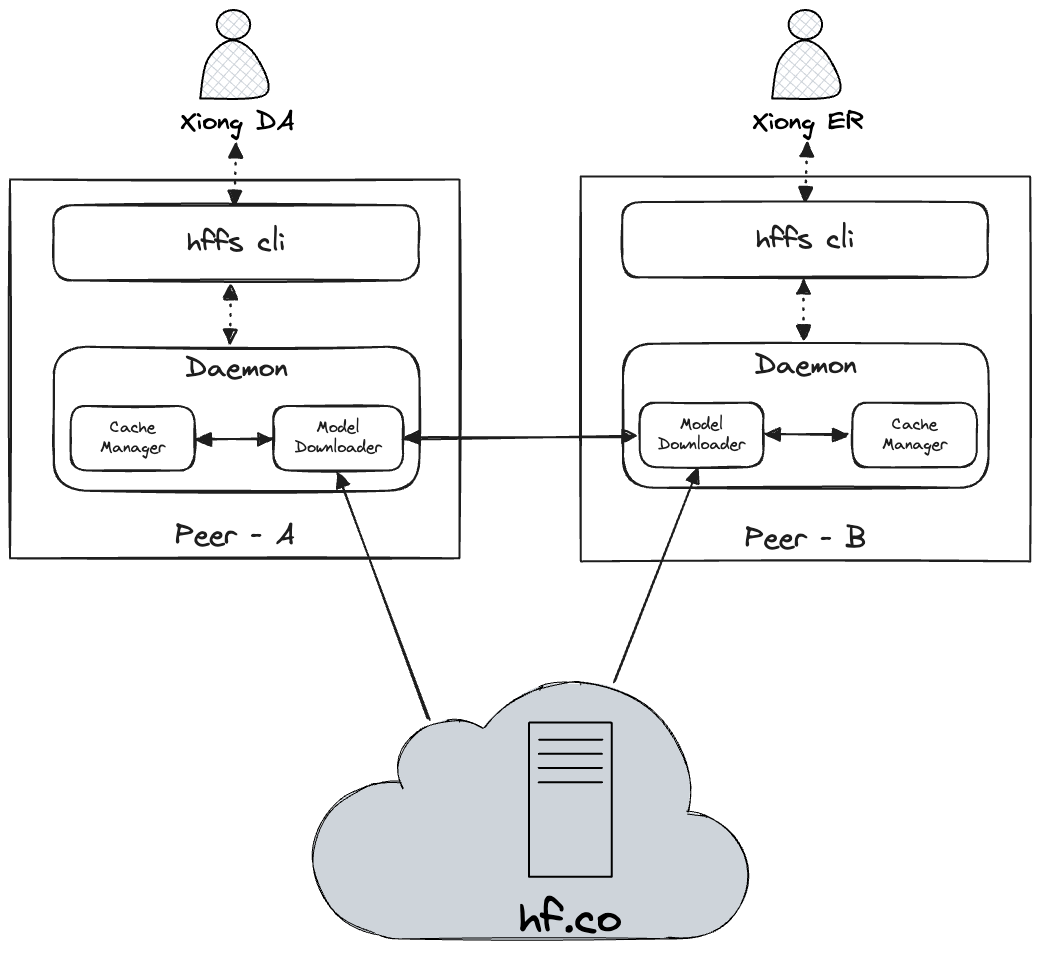
## jycache-model 如何工作
|
## HFFS 如何工作
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
1. 通过 `hffs daemon start` 命令启动 HFFS daemon 服务;
|
1. 通过 `hffs daemon start` 命令启动 HFFS daemon 服务;
|
||||||
2. 通过 `hffs peer add` 相关命令把局域网内其他机器作为 peer 和本机配对;
|
2. 通过 `hffs peer add` 相关命令把局域网内其他机器作为 peer 和本机配对;
|
||||||
|
|
@ -24,26 +25,25 @@ jycache-model 的典型使用场景有:
|
||||||
|
|
||||||
`hffs daemon`、`hffs peer`、`hffs model` 命令还包括其他的功能,请见下面的文档说明。
|
`hffs daemon`、`hffs peer`、`hffs model` 命令还包括其他的功能,请见下面的文档说明。
|
||||||
|
|
||||||
## 安装
|
## 安装 HFFS
|
||||||
|
|
||||||
> 注意:
|
> [!NOTE]
|
||||||
> 确保你安装了 Python 3.11+ 版本并且安装了 pip。
|
>
|
||||||
> 可以考虑使用 [Miniconda](https://docs.anaconda.com/miniconda/miniconda-install/) 安装和管理不同版本的 Python。
|
> - 确保你安装了 Python 3.11+ 版本并且安装了 pip。
|
||||||
> pip 的使用见 [这里](https://pip.pypa.io/en/stable/cli/pip_install/)。
|
> - 可以考虑使用 [Miniconda](https://docs.anaconda.com/miniconda/miniconda-install/) 安装和管理不同版本的 Python。
|
||||||
|
> - pip 的使用见 [这里](https://pip.pypa.io/en/stable/cli/pip_install/)。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
|
|
||||||
pip install -i https://test.pypi.org/simple/ hffs
|
pip install -i https://test.pypi.org/simple/ hffs
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
## 命令行
|
## HFFS 命令
|
||||||
|
|
||||||
### HFFS Daemon 服务管理
|
### HFFS Daemon 服务管理
|
||||||
|
|
||||||
#### 启动 HFFS Daemon
|
#### 启动 HFFS Daemon
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
hffs daemon start [--port PORT_NUM]
|
hffs daemon start [--port PORT_NUM]
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -52,15 +52,13 @@ hffs daemon start [--port PORT_NUM]
|
||||||
#### 关闭 HFFS
|
#### 关闭 HFFS
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
hffs daemon stop
|
hffs daemon stop
|
||||||
```
|
```
|
||||||
|
|
||||||
### Peer 管理
|
### Peer 管理
|
||||||
|
|
||||||
> 注意:
|
> [!NOTE]
|
||||||
> 关于自动 Peer 管理:为了提高易用性,HFFS 计划加入自动 Peer 管理功能(HFFS 自动发现、连接 Peer)。在该功能发布以前,用户可以通过下面的命令手动管理 Peer。
|
> 关于自动 Peer 管理:为了提高易用性,HFFS 计划加入自动 Peer 管理功能(HFFS 自动发现、连接 Peer)。在该功能发布以前,用户可以通过下面的命令手动管理 Peer。在 Unix-like 操作系统上,可以使用 [这里](https://www.51cto.com/article/720658.html) 介绍的 `ifconfig` 或者 `hostname` 命令行查找机器的 IP 地址。 在 Windows 操作系统上,可以使用 [这里](https://support.microsoft.com/zh-cn/windows/%E5%9C%A8-windows-%E4%B8%AD%E6%9F%A5%E6%89%BE-ip-%E5%9C%B0%E5%9D%80-f21a9bbc-c582-55cd-35e0-73431160a1b9) 介绍的方式找到机器的 IP 地址。
|
||||||
|
|
||||||
在 Unix-like 操作系统上,可以使用 [这里](https://www.51cto.com/article/720658.html) 介绍的 `ifconfig` 或者 `hostname` 命令行查找机器的 IP 地址。 在 Windows 操作系统上,可以使用 [这里](https://support.microsoft.com/zh-cn/windows/%E5%9C%A8-windows-%E4%B8%AD%E6%9F%A5%E6%89%BE-ip-%E5%9C%B0%E5%9D%80-f21a9bbc-c582-55cd-35e0-73431160a1b9) 介绍的方式找到机器的 IP 地址。
|
|
||||||
|
|
||||||
#### 添加 Peer
|
#### 添加 Peer
|
||||||
|
|
||||||
|
|
@ -83,7 +81,7 @@ hffs peer ls
|
||||||
|
|
||||||
在 Daemon 已经启动的情况下, Daemon 会定期查询其他 peer 是否在线。`hffs peer ls` 命令会把在线的 peer 标注为 "_active_"。
|
在 Daemon 已经启动的情况下, Daemon 会定期查询其他 peer 是否在线。`hffs peer ls` 命令会把在线的 peer 标注为 "_active_"。
|
||||||
|
|
||||||
> 注意:
|
> [!NOTE]
|
||||||
> 如果 peer 互通在 Windows 上出现问题,请检查:1. Daemon 是否已经启动,2. Windows 的防火墙是否打开(参见 [这里](https://support.microsoft.com/zh-cn/windows/%E5%85%81%E8%AE%B8%E5%BA%94%E7%94%A8%E9%80%9A%E8%BF%87-windows-defender-%E9%98%B2%E7%81%AB%E5%A2%99%E7%9A%84%E9%A3%8E%E9%99%A9-654559af-3f54-3dcf-349f-71ccd90bcc5c))
|
> 如果 peer 互通在 Windows 上出现问题,请检查:1. Daemon 是否已经启动,2. Windows 的防火墙是否打开(参见 [这里](https://support.microsoft.com/zh-cn/windows/%E5%85%81%E8%AE%B8%E5%BA%94%E7%94%A8%E9%80%9A%E8%BF%87-windows-defender-%E9%98%B2%E7%81%AB%E5%A2%99%E7%9A%84%E9%A3%8E%E9%99%A9-654559af-3f54-3dcf-349f-71ccd90bcc5c))
|
||||||
|
|
||||||
#### 删除 Peer
|
#### 删除 Peer
|
||||||
|
|
@ -96,67 +94,166 @@ hffs peer rm IP [--port PORT_NUM]
|
||||||
|
|
||||||
### 模型管理
|
### 模型管理
|
||||||
|
|
||||||
|
#### 添加模型
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs model add REPO_ID [--file FILE] [--revision REVISION]
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 HFFS 下载并管理指定的模型。
|
||||||
|
|
||||||
|
下载顺序为 peer $\rightarrow$ 镜像网站 $\rightarrow$ hf.co 原站;如果 peer 节点中并未找到目标模型,并且镜像网站(hf-mirror.com 等)和 hf.co 原站都无法访问(镜像网站关闭、原站由于代理设置不当而无法联通等原因),则下载失败。
|
||||||
|
|
||||||
|
参数说明
|
||||||
|
|
||||||
|
- `REPO_ID` 的 [相关文档](https://huggingface.co/docs/hub/en/api#get-apimodelsrepoid-or-apimodelsrepoidrevisionrevision)
|
||||||
|
- `FILE` 是模型文件相对 git root 目录的相对路径
|
||||||
|
- 该路径可以在 huggingface 的网页上查看
|
||||||
|
- 在执行添加、删除模型文件命令的时候,都需要使用该路径作为参数指定目标文件
|
||||||
|
- 例如,模型 [google/timesfm-1.0-200m](https://hf-mirror.com/google/timesfm-1.0-200m) 中 [checkpoint](https://hf-mirror.com/google/timesfm-1.0-200m/tree/main/checkpoints/checkpoint_1100000/state) 文件的路径为 `checkpoints/checkpoint_1100000/state`
|
||||||
|
- `REVISION` 的 [相关文档](https://huggingface.co/docs/hub/en/api#get-apimodelsrepoid-or-apimodelsrepoidrevisionrevision)
|
||||||
|
- revision 可以是 git 分支名称/ref(如 `main`, `master` 等),或是模型在 git 中提交时的 commit 哈希值
|
||||||
|
- 如果 revision 是 ref,HFFS 会把它映射成 commit 哈希值。
|
||||||
|
|
||||||
|
如果只提供了 `REPO_ID` 参数(没有制定 `FILE` 参数)
|
||||||
|
|
||||||
|
1. HFFS 会先从镜像网站(hf-mirror.com 等)或 hf.co 原站扫描 repo 中所有文件的文件列表;如果列表获取失败,则下载失败,HFFS 会在终端显示相关的失败原因
|
||||||
|
2. 成功获取文件列表后,HFFS 根据文件列表中的信息依次下载各个模型文件。
|
||||||
|
|
||||||
|
如果同时提供了 `REPO_ID` 参数和 `FILE` 参数,HFFS 和以 “peer $\rightarrow$ 镜像网站 $\rightarrow$ hf.co 原站”的顺序下载指定文件。
|
||||||
|
|
||||||
|
> [!NOTE] 什么时候需要使用 `FILE` 参数?
|
||||||
|
> 下列情况可以使用 `FILE` 参数
|
||||||
|
>
|
||||||
|
> 1. 只需要下载某些模型文件,而不是 repo 中所有文件
|
||||||
|
> 2. 用户自己编写脚本进行文件下载
|
||||||
|
> 3. 由于网络原因,终端无法访问 hf.co,但是浏览器可以访问 hf.co
|
||||||
|
|
||||||
#### 查看模型
|
#### 查看模型
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
hffs model ls [--repo_id REPO_ID] [--file FILE]
|
hffs model ls [--repo_id REPO_ID] [--file FILE]
|
||||||
```
|
```
|
||||||
|
|
||||||
扫描已经下载的模型。该命令返回如下信息:
|
扫描已经下载到 HFFS 中的模型。
|
||||||
|
|
||||||
- 如果没有指定 REPO_ID,返回 repo 列表
|
`REPO_ID` 和 `FILE` 参数的说明见 [[#添加模型]] 部分。
|
||||||
- `REPO_ID` 的 [相关文档](https://huggingface.co/docs/hub/en/api#get-apimodelsrepoid-or-apimodelsrepoidrevisionrevision)
|
|
||||||
- 如果制定了 REPO_ID,但是没有指定 FILE,返回 repo 中所有缓存的文件
|
该命令返回如下信息:
|
||||||
- `FILE` 是模型文件相对 git root 目录的相对路径,该路径可以在 huggingface 的网页上查看
|
|
||||||
- 在执行添加、删除模型文件命令的时候,都需要使用该路径作为参数指定目标文件;
|
- 如果没有指定 `REPO_ID`,返回 repo 列表
|
||||||
|
- 如果制定了 `REPO_ID`,但是没有指定 `FILE`,返回 repo 中所有缓存的文件
|
||||||
- 如果同时制定了 `REPO_ID` 和 `FILE`,返回指定文件在本机文件系统中的绝对路径
|
- 如果同时制定了 `REPO_ID` 和 `FILE`,返回指定文件在本机文件系统中的绝对路径
|
||||||
- 用户可以使用该绝对路径访问模型文件
|
- 用户可以使用该绝对路径访问模型文件
|
||||||
- 注意:在 Unix-like 的操作系统中,由于缓存内部使用了软连接的方式保存文件,目标模型文件的 git 路径以及文件系统中的路径别没有直接关系
|
- 注意:在 Unix-like 的操作系统中,由于缓存内部使用了软连接的方式保存文件,目标模型文件的 git 路径(即 `FILE` 值)和文件在本地的存放路径并没有直接关系
|
||||||
|
|
||||||
#### 搜索模型
|
|
||||||
|
|
||||||
```bash
|
|
||||||
hffs model search REPO_ID FILE [--revision REVISION]
|
|
||||||
```
|
|
||||||
|
|
||||||
搜索目标模型文件在哪些 peer 上已经存在。
|
|
||||||
|
|
||||||
- 如果模型还未下载到本地,从 peer 节点或者 hf.co 下载目标模型
|
|
||||||
- `REPO_ID` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `FILE` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `REVISION` 的 [相关文档](https://huggingface.co/docs/hub/en/api#get-apimodelsrepoid-or-apimodelsrepoidrevisionrevision)
|
|
||||||
|
|
||||||
#### 添加模型
|
|
||||||
|
|
||||||
```bash
|
|
||||||
hffs model add REPO_ID FILE [--revision REVISION]
|
|
||||||
```
|
|
||||||
|
|
||||||
下载指定的模型。
|
|
||||||
|
|
||||||
- 如果模型还未下载到本地,从 peer 节点或者 hf.co 下载目标模型
|
|
||||||
- `REPO_ID` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `FILE` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `REVISION` 参数说明见 `hffs model search` 命令
|
|
||||||
|
|
||||||
#### 删除模型
|
#### 删除模型
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
hffs model rm REPO_ID FILE [--revision REVISION]
|
hffs model rm REPO_ID [--file FILE] [--revision REVISION]
|
||||||
```
|
```
|
||||||
|
|
||||||
删除已经下载的模型数据。
|
删除 HFFS 下载的模型文件。
|
||||||
|
|
||||||
- 如果模型还未下载到本地,从 peer 节点或者 hf.co 下载目标模型
|
`REPO_ID`, `FILE`, 和 `REVISION` 参数的说明见 [[#添加模型]] 部分。
|
||||||
- `REPO_ID` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `FILE` 参数说明见 `hffs model ls` 命令
|
|
||||||
- `REVISION` 的 [相关文档](https://huggingface.co/docs/hub/en/api#get-apimodelsrepoid-or-apimodelsrepoidrevisionrevision)
|
|
||||||
|
|
||||||
### 卸载管理
|
工作原理:
|
||||||
|
|
||||||
#### 卸载软件
|
- 如果没有指定 `REVISION` 参数,默认删除 `main` 中的模型文件,否则删除 `REVISION` 指定版本的文件;如果本地找不到匹配的 `REVISION` 值,则不删除任何文件
|
||||||
|
- 如果制定了 `FILE` 参数,只删除目标文件;如果没有指定 `FILE` 参数,删除整个 repo;如果本地找不到匹配的 `FILE`,则不删除任何文件
|
||||||
|
|
||||||
> 警告:
|
#### 导入模型
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs model import SRC_PATH REPO_ID \
|
||||||
|
[--file FILE] \
|
||||||
|
[--revision REVISION] \
|
||||||
|
[--method IMPORT_METHOD]
|
||||||
|
```
|
||||||
|
|
||||||
|
将已经下载到本机的模型导入给 HFFS 管理。
|
||||||
|
|
||||||
|
交给 HFFS 管理模型的好处有:
|
||||||
|
|
||||||
|
1. 通过 [[#查看模型|hffs model ls 命令]] 查看本机模型文件的统计信息(文件数量、占用硬盘空间的大小等)
|
||||||
|
2. 通过 [[#删除模型|hffs model rm 命令]] 方便地删除模型文件、优化硬盘空间的使用率
|
||||||
|
3. 通过 HFFS 和其他 peer 节点分享模型文件
|
||||||
|
|
||||||
|
参数说明:
|
||||||
|
|
||||||
|
1. `REPO_ID`, `FILE`, 和 `REVISION` 参数的说明见 [[#添加模型]] 部分
|
||||||
|
2. `SRC_PATH` 指向待导入模型在本地的路径
|
||||||
|
3. `IMPORT_METHOD` 指定导入的方法,默认值是 `cp`(拷贝目标文件)
|
||||||
|
|
||||||
|
工作原理:
|
||||||
|
|
||||||
|
- HFFS 会把放在 `SRC_PATH` 中的模型导入到 HFFS 管理的 [[#工作目录管理|工作目录]] 中
|
||||||
|
- 如果 `SRC_PATH`
|
||||||
|
- 指向一个文件,则必须提供 `FILE` 参数,作为该文件在 repo 根目录下的相对路径
|
||||||
|
- 指向一个目录,则 `SRC_PATH` 会被看作 repo 的根目录,该目录下所有文件都会被导入 HFFS 的工作目录中,并保持原始目录结构;同时,`FILE` 参数的值会被忽略
|
||||||
|
- 如果 `REVISION`
|
||||||
|
- 没有指定,HFFS 内部会用 `0000000000000000000000000000000000000000` 作为文件的 revision 值,并创建 `main` ref 指向该 revision
|
||||||
|
- 是 40 位的 hash 值,HFFS 会使用该值作为文件的 revision 值,并创建 `main` ref 指向该 revision
|
||||||
|
- 是一个字符串,HFFS 会使用该值作为分支名称/ref,并将 revision 值设置为 `0000000000000000000000000000000000000000`,然后将 ref 指向这个 revision
|
||||||
|
- `IMPORT_METHOD` 有支持下列值
|
||||||
|
- `cp` (默认)- 拷贝目标文件
|
||||||
|
- `mv` - 拷贝目标文件,成功后删除原始文件
|
||||||
|
- `ln` - 在目标位置位原始文件创建连接(Windows 平台不支持)
|
||||||
|
|
||||||
|
#### 搜索模型
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs model search REPO_ID [--file FILE] [--revision REVISION]
|
||||||
|
```
|
||||||
|
|
||||||
|
搜索 peer 节点,查看目标模型文件在哪些 peer 上已经存在。
|
||||||
|
|
||||||
|
`REPO_ID`, `FILE`, 和 `REVISION` 参数的说明见 [[#添加模型]] 部分。
|
||||||
|
|
||||||
|
工作原理:
|
||||||
|
|
||||||
|
- 如果没有指定 `REVISION` 参数,默认搜索 `main` 中的模型文件,否则搜索 `REVISION` 指定版本的文件
|
||||||
|
- 如果制定了 `FILE` 参数,只搜索目标模型文件;如果没有指定 `FILE` 参数,搜索和 repo 相关的所有文件
|
||||||
|
- HFFS 在终端中打印的结果包含如下信息:`peer-id:port,repo-id,file`
|
||||||
|
|
||||||
|
### 配置管理
|
||||||
|
|
||||||
|
#### 工作目录管理
|
||||||
|
|
||||||
|
HFFS 的工作目录中包括
|
||||||
|
|
||||||
|
- HFFS 的配置文件
|
||||||
|
- HFFS 所下载和管理的模型文件,以及其他相关文件
|
||||||
|
|
||||||
|
##### 工作目录设置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs conf cache set HOME_PATH
|
||||||
|
```
|
||||||
|
|
||||||
|
设置服务的工作目录,包括配置存放目录和文件下载目录
|
||||||
|
|
||||||
|
- `HOME_PATH` 工作目录的路径,路径必须已存在
|
||||||
|
|
||||||
|
##### 工作目录获取
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs conf cache get
|
||||||
|
```
|
||||||
|
|
||||||
|
获取当前生效的工作目录。注意:此路径非 set 设置的路径,环境变量会覆盖 set 设置的路径。
|
||||||
|
|
||||||
|
##### 工作目录重置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hffs conf cache reset
|
||||||
|
```
|
||||||
|
|
||||||
|
恢复配置的工作目录路径为默认路径。注意:此操作无法重置环境变量的设置。
|
||||||
|
|
||||||
|
## 卸载 HFFS
|
||||||
|
|
||||||
|
> [!WARNING]
|
||||||
> 卸载软件将会清除所有添加的配置以及已下载的模型,无法恢复,请谨慎操作!
|
> 卸载软件将会清除所有添加的配置以及已下载的模型,无法恢复,请谨慎操作!
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
|
|
|
||||||
|
|
@ -1,10 +0,0 @@
|
||||||
[model]
|
|
||||||
download_dir="download"
|
|
||||||
|
|
||||||
[model.aria2]
|
|
||||||
exec_path=""
|
|
||||||
conf_path=""
|
|
||||||
|
|
||||||
[peer]
|
|
||||||
data_path="peers.json"
|
|
||||||
|
|
||||||
|
|
@ -1,83 +0,0 @@
|
||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding: utf-8 -*-
|
|
||||||
|
|
||||||
import psutil
|
|
||||||
import logging
|
|
||||||
import time
|
|
||||||
import shutil
|
|
||||||
import platform
|
|
||||||
import signal
|
|
||||||
import subprocess
|
|
||||||
import asyncio
|
|
||||||
|
|
||||||
from ..common.settings import HFFS_EXEC_NAME
|
|
||||||
from .http_client import get_service_status, post_stop_service
|
|
||||||
|
|
||||||
|
|
||||||
async def is_service_running():
|
|
||||||
try:
|
|
||||||
_ = await get_service_status()
|
|
||||||
return True
|
|
||||||
except ConnectionError:
|
|
||||||
return False
|
|
||||||
except Exception as e:
|
|
||||||
logging.info(f"If error not caused by service not start, may need check it! ERROR: {e}")
|
|
||||||
return False
|
|
||||||
|
|
||||||
|
|
||||||
async def stop_service():
|
|
||||||
try:
|
|
||||||
await post_stop_service()
|
|
||||||
logging.info("Service stopped success!")
|
|
||||||
except ConnectionError:
|
|
||||||
logging.info("Can not connect to service, may already stopped!")
|
|
||||||
except Exception as e:
|
|
||||||
raise SystemError(f"Failed to stop service! ERROR: {e}")
|
|
||||||
|
|
||||||
|
|
||||||
async def daemon_start(args):
|
|
||||||
if await is_service_running():
|
|
||||||
raise LookupError("Service already start!")
|
|
||||||
|
|
||||||
exec_path = shutil.which(HFFS_EXEC_NAME)
|
|
||||||
|
|
||||||
if not exec_path:
|
|
||||||
raise FileNotFoundError(HFFS_EXEC_NAME)
|
|
||||||
|
|
||||||
creation_flags = 0
|
|
||||||
|
|
||||||
if platform.system() in ["Linux"]:
|
|
||||||
# deal zombie process
|
|
||||||
signal.signal(signal.SIGCHLD, signal.SIG_IGN)
|
|
||||||
elif platform.system() in ["Windows"]:
|
|
||||||
creation_flags = subprocess.CREATE_NO_WINDOW
|
|
||||||
|
|
||||||
cmdline_daemon_false = "--daemon=false"
|
|
||||||
|
|
||||||
_ = subprocess.Popen([exec_path, "daemon", "start", "--port={}".format(args.port), cmdline_daemon_false],
|
|
||||||
stdin=subprocess.DEVNULL,
|
|
||||||
stdout=subprocess.DEVNULL,
|
|
||||||
stderr=subprocess.DEVNULL,
|
|
||||||
creationflags=creation_flags)
|
|
||||||
|
|
||||||
wait_start_time = 3
|
|
||||||
await asyncio.sleep(wait_start_time)
|
|
||||||
|
|
||||||
if await is_service_running():
|
|
||||||
logging.info("Daemon process started successfully")
|
|
||||||
else:
|
|
||||||
raise LookupError("Daemon start but not running, check service or retry!")
|
|
||||||
|
|
||||||
|
|
||||||
async def daemon_stop():
|
|
||||||
if not await is_service_running():
|
|
||||||
logging.info("Service not running, stop nothing!")
|
|
||||||
return
|
|
||||||
|
|
||||||
await stop_service()
|
|
||||||
|
|
||||||
wait_stop_time = 3
|
|
||||||
await asyncio.sleep(wait_stop_time)
|
|
||||||
|
|
||||||
if await is_service_running():
|
|
||||||
raise LookupError("Stopped service but still running, check service or retry!")
|
|
||||||
|
|
@ -1,188 +0,0 @@
|
||||||
import asyncio
|
|
||||||
import time
|
|
||||||
import os
|
|
||||||
|
|
||||||
import aiohttp
|
|
||||||
import aiohttp.client_exceptions
|
|
||||||
import logging
|
|
||||||
|
|
||||||
from ..common.peer import Peer
|
|
||||||
from huggingface_hub import hf_hub_url, get_hf_file_metadata
|
|
||||||
from ..common.settings import load_local_service_port, HFFS_API_PING, HFFS_API_PEER_CHANGE, HFFS_API_ALIVE_PEERS
|
|
||||||
from ..common.settings import HFFS_API_STATUS, HFFS_API_STOP
|
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
|
||||||
|
|
||||||
LOCAL_HOST = "127.0.0.1"
|
|
||||||
|
|
||||||
|
|
||||||
def timeout_sess(timeout=60):
|
|
||||||
return aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=timeout))
|
|
||||||
|
|
||||||
|
|
||||||
async def ping(peer, timeout=15):
|
|
||||||
alive = False
|
|
||||||
seq = os.urandom(4).hex()
|
|
||||||
url = f"http://{peer.ip}:{peer.port}" + HFFS_API_PING + f"?seq={seq}"
|
|
||||||
|
|
||||||
logger.debug(f"probing {peer.ip}:{peer.port}, seq = {seq}")
|
|
||||||
|
|
||||||
try:
|
|
||||||
async with timeout_sess(timeout) as session:
|
|
||||||
async with session.get(url) as response:
|
|
||||||
if response.status == 200:
|
|
||||||
alive = True
|
|
||||||
except TimeoutError:
|
|
||||||
pass
|
|
||||||
except Exception as e:
|
|
||||||
logger.warning(e)
|
|
||||||
|
|
||||||
peer.set_alive(alive)
|
|
||||||
peer.set_epoch(int(time.time()))
|
|
||||||
|
|
||||||
status_msg = "alive" if alive else "dead"
|
|
||||||
logger.debug(f"Peer {peer.ip}:{peer.port} (seq:{seq}) is {status_msg}")
|
|
||||||
return peer
|
|
||||||
|
|
||||||
|
|
||||||
async def alive_peers(timeout=2):
|
|
||||||
port = load_local_service_port()
|
|
||||||
url = f"http://{LOCAL_HOST}:{port}" + HFFS_API_ALIVE_PEERS
|
|
||||||
peers = []
|
|
||||||
|
|
||||||
try:
|
|
||||||
async with timeout_sess(timeout) as session:
|
|
||||||
async with session.get(url) as response:
|
|
||||||
if response.status == 200:
|
|
||||||
peer_list = await response.json()
|
|
||||||
peers = [Peer.from_dict(peer) for peer in peer_list]
|
|
||||||
else:
|
|
||||||
err = f"Failed to get alive peers, HTTP status: {response.status}"
|
|
||||||
logger.error(err)
|
|
||||||
except aiohttp.client_exceptions.ClientConnectionError:
|
|
||||||
logger.warning("Prompt: connect local service failed, may not start, "
|
|
||||||
"execute hffs daemon start to see which peers are active")
|
|
||||||
except TimeoutError:
|
|
||||||
logger.error("Prompt: connect local service timeout, may not start, "
|
|
||||||
"execute hffs daemon start to see which peers are active")
|
|
||||||
except Exception as e:
|
|
||||||
logger.warning(e)
|
|
||||||
logger.warning("Connect service error, please check it, usually caused by service not start!")
|
|
||||||
|
|
||||||
return peers
|
|
||||||
|
|
||||||
|
|
||||||
async def search_coro(peer, repo_id, revision, file_name):
|
|
||||||
"""Check if a certain file exists in a peer's model repository
|
|
||||||
|
|
||||||
Returns:
|
|
||||||
Peer or None: if the peer has the target file, return the peer, otherwise None
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
async with timeout_sess(10) as session:
|
|
||||||
async with session.head(f"http://{peer.ip}:{peer.port}/{repo_id}/resolve/{revision}/{file_name}") as response:
|
|
||||||
if response.status == 200:
|
|
||||||
return peer
|
|
||||||
except Exception:
|
|
||||||
return None
|
|
||||||
|
|
||||||
|
|
||||||
async def do_search(peers, repo_id, revision, file_name):
|
|
||||||
tasks = []
|
|
||||||
|
|
||||||
def all_finished(tasks):
|
|
||||||
return all([task.done() for task in tasks])
|
|
||||||
|
|
||||||
async with asyncio.TaskGroup() as g:
|
|
||||||
for peer in peers:
|
|
||||||
coro = search_coro(peer, repo_id, revision, file_name)
|
|
||||||
tasks.append(g.create_task(coro))
|
|
||||||
|
|
||||||
while not all_finished(tasks):
|
|
||||||
await asyncio.sleep(1)
|
|
||||||
print(".", end="")
|
|
||||||
|
|
||||||
# add new line after the dots
|
|
||||||
print("")
|
|
||||||
|
|
||||||
return [task.result() for task in tasks if task.result() is not None]
|
|
||||||
|
|
||||||
|
|
||||||
async def search_model(peers, repo_id, file_name, revision):
|
|
||||||
if not peers:
|
|
||||||
logger.info("No active peers to search")
|
|
||||||
return []
|
|
||||||
|
|
||||||
logger.info("Will check the following peers:")
|
|
||||||
logger.info(Peer.print_peers(peers))
|
|
||||||
|
|
||||||
avails = await do_search(peers, repo_id, revision, file_name)
|
|
||||||
|
|
||||||
logger.info("Peers who have the model:")
|
|
||||||
logger.info(Peer.print_peers(avails))
|
|
||||||
|
|
||||||
return avails
|
|
||||||
|
|
||||||
|
|
||||||
async def get_model_etag(endpoint, repo_id, filename, revision='main'):
|
|
||||||
url = hf_hub_url(
|
|
||||||
repo_id=repo_id,
|
|
||||||
filename=filename,
|
|
||||||
revision=revision,
|
|
||||||
endpoint=endpoint
|
|
||||||
)
|
|
||||||
|
|
||||||
metadata = get_hf_file_metadata(url)
|
|
||||||
return metadata.etag
|
|
||||||
|
|
||||||
|
|
||||||
async def notify_peer_change(timeout=2):
|
|
||||||
try:
|
|
||||||
port = load_local_service_port()
|
|
||||||
except LookupError:
|
|
||||||
return
|
|
||||||
|
|
||||||
url = f"http://{LOCAL_HOST}:{port}" + HFFS_API_PEER_CHANGE
|
|
||||||
|
|
||||||
try:
|
|
||||||
async with timeout_sess(timeout) as session:
|
|
||||||
async with session.get(url) as response:
|
|
||||||
if response.status != 200:
|
|
||||||
logger.debug(f"Peer change http status: {response.status}")
|
|
||||||
except TimeoutError:
|
|
||||||
pass # silently ignore timeout
|
|
||||||
except aiohttp.client_exceptions.ClientConnectionError:
|
|
||||||
logger.error("Connect local service failed, please check service!")
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"Peer change error: {e}")
|
|
||||||
logger.error("Please check the error, usually caused by local service not start!")
|
|
||||||
|
|
||||||
|
|
||||||
async def get_service_status():
|
|
||||||
port = load_local_service_port()
|
|
||||||
url = f"http://{LOCAL_HOST}:{port}" + HFFS_API_STATUS
|
|
||||||
timeout = 5
|
|
||||||
|
|
||||||
try:
|
|
||||||
async with timeout_sess(timeout) as session:
|
|
||||||
async with session.get(url) as response:
|
|
||||||
if response.status != 200:
|
|
||||||
raise ValueError(f"Server response not 200 OK! status: {response.status}")
|
|
||||||
else:
|
|
||||||
return await response.json()
|
|
||||||
except (TimeoutError, ConnectionError, aiohttp.client_exceptions.ClientConnectionError):
|
|
||||||
raise ConnectionError("Connect server failed or timeout")
|
|
||||||
|
|
||||||
|
|
||||||
async def post_stop_service():
|
|
||||||
port = load_local_service_port()
|
|
||||||
url = f"http://{LOCAL_HOST}:{port}" + HFFS_API_STOP
|
|
||||||
timeout = 5
|
|
||||||
|
|
||||||
try:
|
|
||||||
async with timeout_sess(timeout) as session:
|
|
||||||
async with session.post(url) as response:
|
|
||||||
if response.status != 200:
|
|
||||||
raise ValueError(f"Server response not 200 OK! status: {response.status}")
|
|
||||||
except (TimeoutError, ConnectionError, aiohttp.client_exceptions.ClientConnectionError):
|
|
||||||
raise ConnectionError("Connect server failed or timeout")
|
|
||||||
|
|
@ -0,0 +1,206 @@
|
||||||
|
"""Daemon client for connecting with (self or other) Daemons."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
import time
|
||||||
|
from contextlib import asynccontextmanager
|
||||||
|
from typing import AsyncContextManager, AsyncIterator, List
|
||||||
|
|
||||||
|
import aiohttp
|
||||||
|
from huggingface_hub import ( # type: ignore[import-untyped]
|
||||||
|
get_hf_file_metadata,
|
||||||
|
hf_hub_url,
|
||||||
|
)
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.api_settings import (
|
||||||
|
API_DAEMON_PEERS_ALIVE,
|
||||||
|
API_DAEMON_PEERS_CHANGE,
|
||||||
|
API_DAEMON_RUNNING,
|
||||||
|
API_DAEMON_STOP,
|
||||||
|
API_FETCH_FILE_CLIENT,
|
||||||
|
API_FETCH_REPO_FILE_LIST,
|
||||||
|
API_PEERS_PROBE,
|
||||||
|
TIMEOUT_DAEMON,
|
||||||
|
TIMEOUT_PEERS,
|
||||||
|
ApiType,
|
||||||
|
)
|
||||||
|
from hffs.common.peer import Peer
|
||||||
|
from hffs.common.repo_files import RepoFileList
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
HTTP_STATUS_OK = 200
|
||||||
|
|
||||||
|
|
||||||
|
def _http_session() -> aiohttp.ClientSession:
|
||||||
|
return aiohttp.ClientSession()
|
||||||
|
|
||||||
|
|
||||||
|
def _api_url(peer: Peer, api: ApiType) -> str:
|
||||||
|
return f"http://{peer.ip}:{peer.port}{api}"
|
||||||
|
|
||||||
|
|
||||||
|
@asynccontextmanager
|
||||||
|
async def _quiet_request(
|
||||||
|
sess: aiohttp.ClientSession,
|
||||||
|
req: AsyncContextManager,
|
||||||
|
) -> AsyncIterator[aiohttp.ClientResponse | None]:
|
||||||
|
try:
|
||||||
|
async with sess, req as resp:
|
||||||
|
yield resp
|
||||||
|
except (
|
||||||
|
aiohttp.ClientError,
|
||||||
|
asyncio.exceptions.TimeoutError,
|
||||||
|
TimeoutError,
|
||||||
|
ConnectionError,
|
||||||
|
RuntimeError,
|
||||||
|
) as e:
|
||||||
|
logger.debug("HTTP Error: %s", e)
|
||||||
|
yield None
|
||||||
|
|
||||||
|
|
||||||
|
@asynccontextmanager
|
||||||
|
async def _quiet_get(
|
||||||
|
url: str,
|
||||||
|
timeout: aiohttp.ClientTimeout,
|
||||||
|
) -> AsyncIterator[aiohttp.ClientResponse | None]:
|
||||||
|
sess = _http_session()
|
||||||
|
req = sess.get(url, timeout=timeout)
|
||||||
|
async with _quiet_request(sess, req) as resp:
|
||||||
|
try:
|
||||||
|
yield resp
|
||||||
|
except (OSError, ValueError, RuntimeError) as e:
|
||||||
|
logger.debug("Failed to get response: %s", e)
|
||||||
|
yield None
|
||||||
|
|
||||||
|
|
||||||
|
@asynccontextmanager
|
||||||
|
async def _quiet_head(
|
||||||
|
url: str,
|
||||||
|
timeout: aiohttp.ClientTimeout,
|
||||||
|
) -> AsyncIterator[aiohttp.ClientResponse | None]:
|
||||||
|
sess = _http_session()
|
||||||
|
req = sess.head(url, timeout=timeout)
|
||||||
|
async with _quiet_request(sess, req) as resp:
|
||||||
|
try:
|
||||||
|
yield resp
|
||||||
|
except (OSError, ValueError, RuntimeError) as e:
|
||||||
|
logger.debug("Failed to get response: %s", e)
|
||||||
|
yield None
|
||||||
|
|
||||||
|
|
||||||
|
async def ping(target: Peer) -> Peer:
|
||||||
|
"""Ping a peer to check if it is alive."""
|
||||||
|
url = _api_url(target, API_PEERS_PROBE)
|
||||||
|
async with _quiet_get(url, TIMEOUT_PEERS) as resp:
|
||||||
|
target.alive = resp is not None and resp.status == HTTP_STATUS_OK
|
||||||
|
target.epoch = int(time.time())
|
||||||
|
return target
|
||||||
|
|
||||||
|
|
||||||
|
async def stop_daemon() -> bool:
|
||||||
|
"""Stop a daemon service."""
|
||||||
|
url = _api_url(HffsContext.get_daemon(), API_DAEMON_STOP)
|
||||||
|
async with _quiet_get(url, TIMEOUT_DAEMON) as resp:
|
||||||
|
return resp is not None and resp.status == HTTP_STATUS_OK
|
||||||
|
|
||||||
|
|
||||||
|
async def is_daemon_running() -> bool:
|
||||||
|
"""Check if daemon is running."""
|
||||||
|
url = _api_url(HffsContext.get_daemon(), API_DAEMON_RUNNING)
|
||||||
|
async with _quiet_get(url, TIMEOUT_DAEMON) as resp:
|
||||||
|
return resp is not None and resp.status == HTTP_STATUS_OK
|
||||||
|
|
||||||
|
|
||||||
|
async def get_alive_peers() -> List[Peer]:
|
||||||
|
"""Get a list of alive peers."""
|
||||||
|
url = _api_url(HffsContext.get_daemon(), API_DAEMON_PEERS_ALIVE)
|
||||||
|
async with _quiet_get(url, TIMEOUT_DAEMON) as resp:
|
||||||
|
if not resp:
|
||||||
|
return []
|
||||||
|
return [Peer(**peer) for peer in await resp.json()]
|
||||||
|
|
||||||
|
|
||||||
|
async def notify_peers_change() -> bool:
|
||||||
|
"""Notify peers about a change in peer list."""
|
||||||
|
url = _api_url(HffsContext.get_daemon(), API_DAEMON_PEERS_CHANGE)
|
||||||
|
async with _quiet_get(url, TIMEOUT_DAEMON) as resp:
|
||||||
|
return resp is not None and resp.status == HTTP_STATUS_OK
|
||||||
|
|
||||||
|
|
||||||
|
async def check_file_exist(
|
||||||
|
peer: Peer,
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> tuple[Peer, bool]:
|
||||||
|
"""Check if the peer has target file."""
|
||||||
|
url = _api_url(
|
||||||
|
peer,
|
||||||
|
API_FETCH_FILE_CLIENT.format(
|
||||||
|
repo=repo_id,
|
||||||
|
revision=revision,
|
||||||
|
file_name=file_name,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
async with _quiet_head(url, TIMEOUT_PEERS) as resp:
|
||||||
|
return (peer, resp is not None and resp.status == HTTP_STATUS_OK)
|
||||||
|
|
||||||
|
|
||||||
|
async def get_file_etag(
|
||||||
|
endpoint: str,
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> str | None:
|
||||||
|
"""Get the ETag of a file."""
|
||||||
|
url = hf_hub_url(
|
||||||
|
repo_id=repo_id,
|
||||||
|
filename=file_name,
|
||||||
|
revision=revision,
|
||||||
|
endpoint=endpoint,
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
metadata = get_hf_file_metadata(url)
|
||||||
|
if metadata:
|
||||||
|
return metadata.etag
|
||||||
|
except (OSError, ValueError):
|
||||||
|
logger.debug(
|
||||||
|
"Failed to get ETag: %s, %s, %s, %s",
|
||||||
|
endpoint,
|
||||||
|
repo_id,
|
||||||
|
file_name,
|
||||||
|
revision,
|
||||||
|
)
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
async def check_repo_exist() -> tuple[Peer, bool]:
|
||||||
|
"""Check if the peer has target model."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
async def get_repo_file_list(
|
||||||
|
peer: Peer,
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> RepoFileList | None:
|
||||||
|
"""Load the target model from a peer."""
|
||||||
|
user, model = repo_id.strip().split("/")
|
||||||
|
url = _api_url(
|
||||||
|
peer,
|
||||||
|
API_FETCH_REPO_FILE_LIST.format(
|
||||||
|
user=user,
|
||||||
|
model=model,
|
||||||
|
revision=revision,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
async with _quiet_get(url, TIMEOUT_PEERS) as resp:
|
||||||
|
if not resp or resp.status != HTTP_STATUS_OK:
|
||||||
|
return None
|
||||||
|
return await resp.json()
|
||||||
|
|
@ -0,0 +1,162 @@
|
||||||
|
"""Model management related commands."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from typing import TYPE_CHECKING, List
|
||||||
|
|
||||||
|
from prettytable import PrettyTable
|
||||||
|
|
||||||
|
from hffs.client import model_controller
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.client.model_controller import FileInfo, RepoInfo
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _tablize(names: List[str], rows: List[List[str]]) -> None:
|
||||||
|
table = PrettyTable()
|
||||||
|
table.field_names = names
|
||||||
|
table.add_rows(rows)
|
||||||
|
logger.info(table)
|
||||||
|
|
||||||
|
|
||||||
|
def _tablize_files(files: List[FileInfo]) -> None:
|
||||||
|
if not files:
|
||||||
|
logger.info("No files found.")
|
||||||
|
else:
|
||||||
|
names = ["REFS", "COMMIT", "FILE", "SIZE", "PATH"]
|
||||||
|
rows = [
|
||||||
|
[
|
||||||
|
",".join(f.refs),
|
||||||
|
f.commit_8,
|
||||||
|
str(f.file_name),
|
||||||
|
str(f.size_on_disk_str),
|
||||||
|
str(f.file_path),
|
||||||
|
]
|
||||||
|
for f in files
|
||||||
|
]
|
||||||
|
_tablize(names, rows)
|
||||||
|
|
||||||
|
|
||||||
|
def _tablize_repos(repos: List[RepoInfo]) -> None:
|
||||||
|
if not repos:
|
||||||
|
logger.info("No repos found.")
|
||||||
|
else:
|
||||||
|
names = ["REPO ID", "SIZE", "NB FILES", "LOCAL PATH"]
|
||||||
|
rows = [
|
||||||
|
[
|
||||||
|
r.repo_id,
|
||||||
|
f"{r.size_str:>12}",
|
||||||
|
str(r.nb_files),
|
||||||
|
str(
|
||||||
|
r.repo_path,
|
||||||
|
),
|
||||||
|
]
|
||||||
|
for r in repos
|
||||||
|
]
|
||||||
|
_tablize(names, rows)
|
||||||
|
|
||||||
|
|
||||||
|
def _ls(args: Namespace) -> None:
|
||||||
|
if args.repo:
|
||||||
|
files = model_controller.file_list(args.repo)
|
||||||
|
_tablize_files(files)
|
||||||
|
else:
|
||||||
|
repos = model_controller.repo_list()
|
||||||
|
_tablize_repos(repos)
|
||||||
|
|
||||||
|
|
||||||
|
async def _add(args: Namespace) -> None:
|
||||||
|
if args.file is None and args.revision == "main":
|
||||||
|
msg = (
|
||||||
|
"In order to keep repo version integrity, when add a repo,"
|
||||||
|
"You must specify the commit hash (i.e. 8775f753) with -v option."
|
||||||
|
)
|
||||||
|
logger.info(msg)
|
||||||
|
return
|
||||||
|
|
||||||
|
if args.file:
|
||||||
|
target = f"File {args.repo}/{args.file}"
|
||||||
|
success = await model_controller.file_add(
|
||||||
|
args.repo,
|
||||||
|
args.file,
|
||||||
|
args.revision,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
target = f"Model {args.repo}"
|
||||||
|
success = await model_controller.repo_add(
|
||||||
|
args.repo,
|
||||||
|
args.revision,
|
||||||
|
)
|
||||||
|
|
||||||
|
if success:
|
||||||
|
logger.info("%s added.", target)
|
||||||
|
else:
|
||||||
|
logger.info("%s failed to add.", target)
|
||||||
|
|
||||||
|
|
||||||
|
def _rm(args: Namespace) -> None:
|
||||||
|
if args.file:
|
||||||
|
if not args.revision:
|
||||||
|
logger.info("Remove file failed, must specify the revision!")
|
||||||
|
return
|
||||||
|
|
||||||
|
target = "File"
|
||||||
|
success = model_controller.file_rm(
|
||||||
|
args.repo,
|
||||||
|
args.file,
|
||||||
|
args.revision,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
target = "Model"
|
||||||
|
success = model_controller.repo_rm(
|
||||||
|
args.repo,
|
||||||
|
args.revision,
|
||||||
|
)
|
||||||
|
|
||||||
|
if success:
|
||||||
|
logger.info("%s remove is done.", target)
|
||||||
|
else:
|
||||||
|
logger.info("%s failed to remove.", target)
|
||||||
|
|
||||||
|
|
||||||
|
async def _search(args: Namespace) -> None:
|
||||||
|
if args.file:
|
||||||
|
target = "file"
|
||||||
|
peers = await model_controller.file_search(
|
||||||
|
args.repo,
|
||||||
|
args.file,
|
||||||
|
args.revision,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
target = "model"
|
||||||
|
peers = await model_controller.repo_search()
|
||||||
|
|
||||||
|
if peers:
|
||||||
|
logger.info(
|
||||||
|
"Peers that have target %s:\n[%s]",
|
||||||
|
target,
|
||||||
|
",".join(
|
||||||
|
[f"{p.ip}:{p.port}" for p in peers],
|
||||||
|
),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
logger.info("NO peer has target %s.", target)
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.model_command == "ls":
|
||||||
|
_ls(args)
|
||||||
|
elif args.model_command == "add":
|
||||||
|
await _add(args)
|
||||||
|
elif args.model_command == "rm":
|
||||||
|
_rm(args)
|
||||||
|
elif args.model_command == "search":
|
||||||
|
await _search(args)
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -0,0 +1,389 @@
|
||||||
|
"""Manage models."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
from typing import TYPE_CHECKING, Any, Coroutine, List, TypeVar
|
||||||
|
|
||||||
|
from huggingface_hub import hf_hub_download # type: ignore[import-untyped]
|
||||||
|
from huggingface_hub.utils import GatedRepoError # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
from hffs.client import http_request as request
|
||||||
|
from hffs.common import hf_wrapper
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.etag import save_etag
|
||||||
|
from hffs.common.repo_files import RepoFileList, load_file_list, save_file_list
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
from hffs.common.peer import Peer
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
T = TypeVar("T")
|
||||||
|
|
||||||
|
|
||||||
|
async def _safe_gather(
|
||||||
|
tasks: List[Coroutine[Any, Any, T]],
|
||||||
|
) -> List[T]:
|
||||||
|
results = await asyncio.gather(*tasks, return_exceptions=True)
|
||||||
|
return [r for r in results if not isinstance(r, BaseException)]
|
||||||
|
|
||||||
|
|
||||||
|
async def file_search(
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> List[Peer]:
|
||||||
|
"""Check which peers have target file."""
|
||||||
|
alives = await request.get_alive_peers()
|
||||||
|
tasks = [
|
||||||
|
request.check_file_exist(alive, repo_id, file_name, revision)
|
||||||
|
for alive in alives
|
||||||
|
]
|
||||||
|
results = await _safe_gather(tasks)
|
||||||
|
exists = {s[0] for s in results if s[1]}
|
||||||
|
return [alive for alive in alives if alive in exists]
|
||||||
|
|
||||||
|
|
||||||
|
async def repo_search() -> List[Peer]:
|
||||||
|
"""Check which peers have target model."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
async def _download_file(
|
||||||
|
endpoint: str,
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> bool:
|
||||||
|
try:
|
||||||
|
# hf_hub_download will send request to the endpoint
|
||||||
|
# on /{user}/{model}/resolve/{revision}/{file_name:.*}
|
||||||
|
# daemon server can handle the request and return the file
|
||||||
|
_ = hf_hub_download(
|
||||||
|
endpoint=endpoint,
|
||||||
|
repo_id=repo_id,
|
||||||
|
revision=revision,
|
||||||
|
filename=file_name,
|
||||||
|
cache_dir=HffsContext.get_model_dir_str(),
|
||||||
|
)
|
||||||
|
|
||||||
|
etag = await request.get_file_etag(
|
||||||
|
endpoint,
|
||||||
|
repo_id,
|
||||||
|
file_name,
|
||||||
|
revision,
|
||||||
|
)
|
||||||
|
if not etag:
|
||||||
|
return False
|
||||||
|
|
||||||
|
save_etag(etag, repo_id, file_name, revision)
|
||||||
|
except GatedRepoError:
|
||||||
|
logger.info("Model is gated. Login with `hffs auth login` first.")
|
||||||
|
return False
|
||||||
|
except (OSError, ValueError) as e:
|
||||||
|
logger.info(f"Failed to download model. ERROR: {e}")
|
||||||
|
logger.debug("Download file error", exc_info=e)
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def _gen_endpoints(peers: List[Peer]) -> List[str]:
|
||||||
|
peer_ends = [f"http://{peer.ip}:{peer.port}" for peer in peers]
|
||||||
|
site_ends = ["https://hf-mirror.com", "https://huggingface.co"]
|
||||||
|
return peer_ends + site_ends
|
||||||
|
|
||||||
|
|
||||||
|
async def file_add(
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> bool:
|
||||||
|
"""Download and add model files to HFFS."""
|
||||||
|
if hf_wrapper.get_file_info(repo_id, revision, file_name) is not None:
|
||||||
|
# file is already downloaded
|
||||||
|
return True
|
||||||
|
|
||||||
|
peers = await file_search(repo_id, file_name, revision)
|
||||||
|
endpoints = _gen_endpoints(peers)
|
||||||
|
|
||||||
|
for endpoint in endpoints:
|
||||||
|
logger.info("Try to add file %s from %s", file_name, endpoint)
|
||||||
|
success = await _download_file(endpoint, repo_id, file_name, revision)
|
||||||
|
|
||||||
|
if success:
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
async def _wait_first(
|
||||||
|
tasks: List[Coroutine[Any, Any, T | None]],
|
||||||
|
) -> T | None:
|
||||||
|
done, _ = await asyncio.wait(tasks, return_when=asyncio.FIRST_COMPLETED)
|
||||||
|
if not done:
|
||||||
|
return None
|
||||||
|
for task in done:
|
||||||
|
result = task.result()
|
||||||
|
if result:
|
||||||
|
return result
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
async def _file_list_from_peers(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> RepoFileList | None:
|
||||||
|
alives = await request.get_alive_peers()
|
||||||
|
if not alives:
|
||||||
|
return None
|
||||||
|
tasks = [request.get_repo_file_list(alive, repo_id, revision) for alive in alives]
|
||||||
|
return await _wait_first(tasks)
|
||||||
|
|
||||||
|
|
||||||
|
async def _file_list_from_site(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> RepoFileList | None:
|
||||||
|
endopints = _gen_endpoints([])
|
||||||
|
for endpoint in endopints:
|
||||||
|
files = hf_wrapper.get_repo_file_list(endpoint, repo_id, revision)
|
||||||
|
if files:
|
||||||
|
return files
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
async def _get_repo_file_list(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> RepoFileList | None:
|
||||||
|
files = load_file_list(repo_id, revision)
|
||||||
|
if not files:
|
||||||
|
files = await _file_list_from_peers(repo_id, revision)
|
||||||
|
if not files:
|
||||||
|
files = await _file_list_from_site(repo_id, revision)
|
||||||
|
if files:
|
||||||
|
save_file_list(repo_id, revision, files)
|
||||||
|
return files
|
||||||
|
|
||||||
|
|
||||||
|
async def repo_add(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> bool:
|
||||||
|
"""Download and add all files in a repo to HFFS."""
|
||||||
|
normalized_rev = hf_wrapper.verify_revision(
|
||||||
|
repo_id,
|
||||||
|
revision,
|
||||||
|
_gen_endpoints([]),
|
||||||
|
)
|
||||||
|
if not normalized_rev:
|
||||||
|
logger.error("Failed to verify revision: %s", revision)
|
||||||
|
return False
|
||||||
|
|
||||||
|
files = await _get_repo_file_list(repo_id, normalized_rev)
|
||||||
|
if not files:
|
||||||
|
logger.error("Failed to get file list of %s", repo_id)
|
||||||
|
return False
|
||||||
|
|
||||||
|
for file_name in files:
|
||||||
|
success = await file_add(repo_id, file_name, normalized_rev)
|
||||||
|
if not success:
|
||||||
|
logger.error("Failed to add file: %s", file_name)
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class FileInfo:
|
||||||
|
"""Info of a model file."""
|
||||||
|
|
||||||
|
file_name: Path = field()
|
||||||
|
size_on_disk_str: str = field()
|
||||||
|
file_path: Path = field()
|
||||||
|
refs: set[str] = field()
|
||||||
|
commit_8: str = field()
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class RepoInfo:
|
||||||
|
"""Info of a repo."""
|
||||||
|
|
||||||
|
repo_id: str = field()
|
||||||
|
size_str: str = field()
|
||||||
|
nb_files: int = field()
|
||||||
|
repo_path: Path = field()
|
||||||
|
|
||||||
|
|
||||||
|
def file_list(repo_id: str) -> List[FileInfo]:
|
||||||
|
"""List files in target repo."""
|
||||||
|
files: List[FileInfo] = []
|
||||||
|
|
||||||
|
repo_info = hf_wrapper.get_repo_info(repo_id)
|
||||||
|
if not repo_info:
|
||||||
|
return files
|
||||||
|
|
||||||
|
for rev in repo_info.revisions:
|
||||||
|
for f in rev.files:
|
||||||
|
fi = FileInfo(
|
||||||
|
f.file_path.relative_to(rev.snapshot_path),
|
||||||
|
f.size_on_disk_str,
|
||||||
|
f.file_path,
|
||||||
|
set(rev.refs),
|
||||||
|
rev.commit_hash[:8],
|
||||||
|
)
|
||||||
|
files.extend([fi])
|
||||||
|
|
||||||
|
return files
|
||||||
|
|
||||||
|
|
||||||
|
def repo_list() -> List[RepoInfo]:
|
||||||
|
"""List repos in the cache."""
|
||||||
|
cache_info = hf_wrapper.get_cache_info()
|
||||||
|
return [
|
||||||
|
RepoInfo(
|
||||||
|
repo.repo_id,
|
||||||
|
f"{repo.size_on_disk_str:>12}",
|
||||||
|
repo.nb_files,
|
||||||
|
repo.repo_path,
|
||||||
|
)
|
||||||
|
for repo in cache_info.repos
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def _is_relative_to(child: Path, parent: Path) -> bool:
|
||||||
|
try:
|
||||||
|
_ = child.relative_to(parent)
|
||||||
|
except ValueError:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def _rm_file(fp: Path, root_path: Path) -> None:
|
||||||
|
if not fp.relative_to(root_path):
|
||||||
|
logger.debug(
|
||||||
|
"Cache structure error: path=%s, root=%s",
|
||||||
|
str(fp),
|
||||||
|
str(root_path),
|
||||||
|
)
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
# remove target file
|
||||||
|
if fp.exists() and fp.is_file():
|
||||||
|
fp.unlink()
|
||||||
|
|
||||||
|
# remove parent directories if empty up to root_path
|
||||||
|
parent_dir = fp.parent
|
||||||
|
while _is_relative_to(parent_dir, root_path):
|
||||||
|
if not any(parent_dir.iterdir()):
|
||||||
|
parent_dir.rmdir()
|
||||||
|
parent_dir = parent_dir.parent
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
|
||||||
|
def _can_delete_blob(
|
||||||
|
file_name: str,
|
||||||
|
snapshot_path: Path,
|
||||||
|
blob_path: Path,
|
||||||
|
) -> bool:
|
||||||
|
"""Delete blob only if there is NO symlink pointing to it."""
|
||||||
|
if not snapshot_path.exists():
|
||||||
|
# delete blob if snapshot path is not existing
|
||||||
|
return True
|
||||||
|
|
||||||
|
for snapshot_dir in snapshot_path.iterdir():
|
||||||
|
snapshot_file = snapshot_dir / file_name
|
||||||
|
if (
|
||||||
|
snapshot_file.exists()
|
||||||
|
and snapshot_file.is_symlink()
|
||||||
|
and (snapshot_file.resolve() == blob_path)
|
||||||
|
):
|
||||||
|
# there is still symlink pointing to the blob file
|
||||||
|
# don't delete the blob
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def file_rm(
|
||||||
|
repo_id: str,
|
||||||
|
file_name: str,
|
||||||
|
revision: str,
|
||||||
|
) -> bool:
|
||||||
|
"""Remove target model file."""
|
||||||
|
try:
|
||||||
|
repo = hf_wrapper.get_repo_info(repo_id)
|
||||||
|
rev = hf_wrapper.get_revision_info(repo_id, revision)
|
||||||
|
f = hf_wrapper.get_file_info(repo_id, revision, file_name)
|
||||||
|
|
||||||
|
if not repo or not rev or not f:
|
||||||
|
logger.info(
|
||||||
|
"Repo or file not found: repo=%s, file=%s, rev=%s",
|
||||||
|
repo_id,
|
||||||
|
file_name,
|
||||||
|
revision,
|
||||||
|
)
|
||||||
|
return False
|
||||||
|
|
||||||
|
# remove snapshot file
|
||||||
|
_rm_file(f.file_path, repo.repo_path / "snapshots")
|
||||||
|
|
||||||
|
# remove blob file
|
||||||
|
# blob path and file path are the same on windows
|
||||||
|
if f.blob_path != f.file_path and (
|
||||||
|
_can_delete_blob(
|
||||||
|
file_name,
|
||||||
|
repo.repo_path / "snapshots",
|
||||||
|
f.blob_path,
|
||||||
|
)
|
||||||
|
):
|
||||||
|
_rm_file(f.blob_path, repo.repo_path / "blobs")
|
||||||
|
|
||||||
|
# if the snapshot dir is not longer existing, it means that the
|
||||||
|
# revision is deleted entirely, hence all the refs pointing to
|
||||||
|
# the revision should be deleted
|
||||||
|
ref_dir = repo.repo_path / "refs"
|
||||||
|
if not rev.snapshot_path.exists() and ref_dir.exists():
|
||||||
|
ref_files = [ref_dir / ref for ref in rev.refs]
|
||||||
|
for ref in ref_files:
|
||||||
|
_rm_file(ref, ref_dir)
|
||||||
|
except (OSError, ValueError):
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def repo_rm(repo_id: str, revision: str | None) -> bool:
|
||||||
|
"""Remove target repo."""
|
||||||
|
try:
|
||||||
|
repo = hf_wrapper.get_repo_info(repo_id)
|
||||||
|
if not repo:
|
||||||
|
return True
|
||||||
|
|
||||||
|
for rev in repo.revisions:
|
||||||
|
if (
|
||||||
|
revision
|
||||||
|
and revision not in rev.refs
|
||||||
|
and not rev.commit_hash.startswith(revision)
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# remove snapshot files
|
||||||
|
for f in rev.files:
|
||||||
|
file_rm(
|
||||||
|
repo_id,
|
||||||
|
str(f.file_path.relative_to(rev.snapshot_path)),
|
||||||
|
rev.commit_hash,
|
||||||
|
)
|
||||||
|
|
||||||
|
except (OSError, ValueError):
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
@ -1,237 +0,0 @@
|
||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding: utf-8 -*-
|
|
||||||
|
|
||||||
import os
|
|
||||||
import logging
|
|
||||||
from pathlib import Path
|
|
||||||
|
|
||||||
from prettytable import PrettyTable
|
|
||||||
from huggingface_hub import scan_cache_dir, hf_hub_download, CachedRevisionInfo, CachedRepoInfo, HFCacheInfo
|
|
||||||
from . import http_client
|
|
||||||
from ..common.settings import HFFS_MODEL_DIR
|
|
||||||
from ..common.hf_adapter import save_etag
|
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
|
||||||
|
|
||||||
|
|
||||||
def _assume(pred, msg):
|
|
||||||
if not pred:
|
|
||||||
logger.info(msg)
|
|
||||||
raise ValueError()
|
|
||||||
|
|
||||||
|
|
||||||
def _is_parent(parent: Path, child: Path):
|
|
||||||
try:
|
|
||||||
child.absolute().relative_to(parent.absolute())
|
|
||||||
return True
|
|
||||||
except ValueError:
|
|
||||||
return False
|
|
||||||
|
|
||||||
|
|
||||||
def _rm_file(fp: Path, root_path: Path, msg: str):
|
|
||||||
# fp is NOT in root_path, raise error
|
|
||||||
_assume(_is_parent(root_path, fp), f"{fp} is not in {root_path}")
|
|
||||||
|
|
||||||
# remove target file
|
|
||||||
if fp.exists() and fp.is_file():
|
|
||||||
fp.unlink()
|
|
||||||
logger.debug(f"{msg}: {fp}")
|
|
||||||
|
|
||||||
# remove parent directories if empty up to root_path
|
|
||||||
parent_dir = fp.parent
|
|
||||||
while _is_parent(root_path, parent_dir):
|
|
||||||
if not any(parent_dir.iterdir()):
|
|
||||||
parent_dir.rmdir()
|
|
||||||
logger.debug(f"Remove {parent_dir}")
|
|
||||||
parent_dir = parent_dir.parent
|
|
||||||
else:
|
|
||||||
break
|
|
||||||
|
|
||||||
|
|
||||||
def _match_repo(cache_info: HFCacheInfo, repo_id):
|
|
||||||
for repo in cache_info.repos:
|
|
||||||
if repo.repo_id == repo_id:
|
|
||||||
return repo
|
|
||||||
return None
|
|
||||||
|
|
||||||
|
|
||||||
def _match_rev(repo_info: CachedRepoInfo, revision):
|
|
||||||
for rev in repo_info.revisions:
|
|
||||||
if revision in rev.refs or rev.commit_hash.startswith(revision):
|
|
||||||
return rev
|
|
||||||
return None
|
|
||||||
|
|
||||||
|
|
||||||
def _match_file(rev_info: CachedRevisionInfo, file_name: str):
|
|
||||||
file_path = rev_info.snapshot_path / file_name
|
|
||||||
for f in rev_info.files:
|
|
||||||
if f.file_path == file_path:
|
|
||||||
return f
|
|
||||||
return None
|
|
||||||
|
|
||||||
|
|
||||||
def _rm(repo_id, file_name, revision="main"):
|
|
||||||
# check necessary arguments
|
|
||||||
_assume(repo_id, "Missing repo_id")
|
|
||||||
_assume(file_name, "Missing file_name")
|
|
||||||
_assume(revision, "Missing revision")
|
|
||||||
|
|
||||||
if os.path.isabs(file_name):
|
|
||||||
raise LookupError("File path is path relative to repo, not the path in operating system!")
|
|
||||||
|
|
||||||
# match cached repo
|
|
||||||
cache_info = scan_cache_dir(HFFS_MODEL_DIR)
|
|
||||||
repo_info = _match_repo(cache_info, repo_id)
|
|
||||||
_assume(repo_info, "No matching repo")
|
|
||||||
|
|
||||||
# match cached revision
|
|
||||||
rev_info = _match_rev(repo_info, revision)
|
|
||||||
_assume(rev_info, "No matching revision")
|
|
||||||
|
|
||||||
# match cached file
|
|
||||||
file_info = _match_file(rev_info, file_name)
|
|
||||||
_assume(file_info, "No matching file")
|
|
||||||
|
|
||||||
# remove snapshot file
|
|
||||||
_rm_file(file_info.file_path,
|
|
||||||
repo_info.repo_path / "snapshots",
|
|
||||||
"Remove snapshot file")
|
|
||||||
|
|
||||||
# remove blob file, on platform not support symbol link, there are equal
|
|
||||||
if file_info.blob_path != file_info.file_path:
|
|
||||||
_rm_file(file_info.blob_path,
|
|
||||||
repo_info.repo_path / "blobs",
|
|
||||||
"Remove blob")
|
|
||||||
|
|
||||||
# if the snapshot dir is not longer existing, it means that the
|
|
||||||
# revision is deleted entirely, hence all the refs pointing to
|
|
||||||
# the revision should be deleted
|
|
||||||
ref_dir = repo_info.repo_path / "refs"
|
|
||||||
if not rev_info.snapshot_path.exists() and ref_dir.exists():
|
|
||||||
ref_files = [ref_dir / ref for ref in rev_info.refs]
|
|
||||||
for ref in ref_files:
|
|
||||||
_rm_file(ref, ref_dir, "Remove ref file")
|
|
||||||
|
|
||||||
|
|
||||||
def _ls_repos():
|
|
||||||
cache_info = scan_cache_dir(cache_dir=HFFS_MODEL_DIR)
|
|
||||||
|
|
||||||
table = PrettyTable()
|
|
||||||
table.field_names = [
|
|
||||||
"REPO ID",
|
|
||||||
"SIZE",
|
|
||||||
"NB FILES",
|
|
||||||
"LOCAL PATH",
|
|
||||||
]
|
|
||||||
|
|
||||||
table.add_rows([
|
|
||||||
repo.repo_id,
|
|
||||||
"{:>12}".format(repo.size_on_disk_str),
|
|
||||||
repo.nb_files,
|
|
||||||
str(repo.repo_path),
|
|
||||||
]
|
|
||||||
for repo in cache_info.repos
|
|
||||||
)
|
|
||||||
# Print the table to stdout
|
|
||||||
print(table)
|
|
||||||
|
|
||||||
|
|
||||||
def _ls_repo_files(repo_id):
|
|
||||||
cache_info = scan_cache_dir(HFFS_MODEL_DIR)
|
|
||||||
repo_info = _match_repo(cache_info, repo_id)
|
|
||||||
_assume(repo_info, "No matching repo")
|
|
||||||
|
|
||||||
files = []
|
|
||||||
for rev in repo_info.revisions:
|
|
||||||
for f in rev.files:
|
|
||||||
refs = ", ".join(rev.refs)
|
|
||||||
commit = rev.commit_hash[:8]
|
|
||||||
file_name = f.file_path.relative_to(rev.snapshot_path)
|
|
||||||
file_path = f.file_path
|
|
||||||
files.append((refs, commit, file_name, f.size_on_disk_str, file_path))
|
|
||||||
|
|
||||||
table = PrettyTable()
|
|
||||||
table.field_names = ["REFS", "COMMIT", "FILE", "SIZE", "PATH"]
|
|
||||||
table.add_rows(files)
|
|
||||||
print(table)
|
|
||||||
|
|
||||||
|
|
||||||
class ModelManager:
|
|
||||||
def init(self):
|
|
||||||
if not os.path.exists(HFFS_MODEL_DIR):
|
|
||||||
os.makedirs(HFFS_MODEL_DIR)
|
|
||||||
|
|
||||||
async def search_model(self, repo_id, file_name, revision="main"):
|
|
||||||
active_peers = await http_client.alive_peers()
|
|
||||||
avail_peers = await http_client.search_model(active_peers, repo_id, file_name, revision)
|
|
||||||
return (active_peers, avail_peers)
|
|
||||||
|
|
||||||
async def add(self, repo_id, file_name, revision="main"):
|
|
||||||
async def do_download(endpoint):
|
|
||||||
path = None
|
|
||||||
|
|
||||||
try:
|
|
||||||
path = hf_hub_download(repo_id,
|
|
||||||
revision=revision,
|
|
||||||
cache_dir=HFFS_MODEL_DIR,
|
|
||||||
filename=file_name,
|
|
||||||
endpoint=endpoint)
|
|
||||||
except Exception as e:
|
|
||||||
logger.info(
|
|
||||||
f"Failed to download model from {endpoint}. Reason: {e}")
|
|
||||||
return False, None
|
|
||||||
|
|
||||||
try:
|
|
||||||
etag = await http_client.get_model_etag(endpoint, repo_id, file_name, revision)
|
|
||||||
if not etag:
|
|
||||||
raise ValueError("ETag not found!")
|
|
||||||
save_etag(etag, repo_id, file_name, revision)
|
|
||||||
except Exception as e:
|
|
||||||
logger.info(
|
|
||||||
f"Failed to save etag from {endpoint} for {repo_id}/{file_name}@{revision}")
|
|
||||||
logger.debug(e)
|
|
||||||
return False, None
|
|
||||||
|
|
||||||
return True, path
|
|
||||||
|
|
||||||
if not file_name:
|
|
||||||
raise ValueError(
|
|
||||||
"Current not support download full repo, file name must be provided!")
|
|
||||||
|
|
||||||
_, avails = await self.search_model(repo_id, file_name, revision)
|
|
||||||
|
|
||||||
for peer in avails:
|
|
||||||
done, path = await do_download(f"http://{peer.ip}:{peer.port}")
|
|
||||||
if done:
|
|
||||||
logger.info(f"Download successfully: {path}")
|
|
||||||
return
|
|
||||||
|
|
||||||
logger.info("Cannot download from peers; try mirror sites")
|
|
||||||
|
|
||||||
done, path = await do_download("https://hf-mirror.com")
|
|
||||||
if done:
|
|
||||||
logger.info(f"Download successfully: {path}")
|
|
||||||
return
|
|
||||||
|
|
||||||
logger.info("Cannot download from mirror site; try hf.co")
|
|
||||||
|
|
||||||
done, path = await do_download("https://huggingface.co")
|
|
||||||
if done:
|
|
||||||
logger.info(f"Download successfully: {path}")
|
|
||||||
return
|
|
||||||
|
|
||||||
logger.info(
|
|
||||||
"Cannot find target model in hf.co; double check the model info")
|
|
||||||
|
|
||||||
def ls(self, repo_id):
|
|
||||||
if not repo_id:
|
|
||||||
_ls_repos()
|
|
||||||
else:
|
|
||||||
_ls_repo_files(repo_id)
|
|
||||||
|
|
||||||
def rm(self, repo_id, file_name, revision="main"):
|
|
||||||
try:
|
|
||||||
_rm(repo_id, file_name, revision)
|
|
||||||
logger.info("Success to delete file!")
|
|
||||||
except ValueError:
|
|
||||||
logger.info("Failed to remove model")
|
|
||||||
|
|
@ -0,0 +1,37 @@
|
||||||
|
"""Peer related commands."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from typing import TYPE_CHECKING, List
|
||||||
|
|
||||||
|
from hffs.client import peer_controller
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.config.hffs_config import Peer
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _print_peer_list(peers: List[tuple[Peer, bool]]) -> None:
|
||||||
|
"""Print peer list."""
|
||||||
|
for peer, alive in peers:
|
||||||
|
peer_name = f"{peer.ip}:{peer.port}"
|
||||||
|
peer_stat = "alive" if alive else ""
|
||||||
|
peer_str = f"{peer_name}\t{peer_stat}"
|
||||||
|
logger.info(peer_str)
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.peer_command == "add":
|
||||||
|
await peer_controller.add(args.ip, args.port)
|
||||||
|
elif args.peer_command == "rm":
|
||||||
|
await peer_controller.rm(args.ip, args.port)
|
||||||
|
elif args.peer_command == "ls":
|
||||||
|
peers = await peer_controller.get()
|
||||||
|
_print_peer_list(peers)
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
"""Manage peers."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
from hffs.client import http_request as request
|
||||||
|
from hffs.config import config_manager
|
||||||
|
from hffs.config.hffs_config import HffsConfigOption, Peer
|
||||||
|
|
||||||
|
|
||||||
|
def _uniq_peers(peers: List[Peer]) -> List[Peer]:
|
||||||
|
"""Remove duplicate peers."""
|
||||||
|
return list(set(peers))
|
||||||
|
|
||||||
|
|
||||||
|
async def add(ip: str, port: int) -> None:
|
||||||
|
"""Add a peer."""
|
||||||
|
peers = config_manager.get_config(HffsConfigOption.PEERS, List[Peer])
|
||||||
|
peers.append(Peer(ip=ip, port=port))
|
||||||
|
config_manager.set_config(
|
||||||
|
HffsConfigOption.PEERS,
|
||||||
|
_uniq_peers(peers),
|
||||||
|
List[Peer],
|
||||||
|
)
|
||||||
|
await request.notify_peers_change()
|
||||||
|
|
||||||
|
|
||||||
|
async def rm(ip: str, port: int) -> None:
|
||||||
|
"""Remove a peer."""
|
||||||
|
peers = config_manager.get_config(HffsConfigOption.PEERS, List[Peer])
|
||||||
|
peers = [peer for peer in peers if peer.ip != ip or peer.port != port]
|
||||||
|
config_manager.set_config(
|
||||||
|
HffsConfigOption.PEERS,
|
||||||
|
_uniq_peers(peers),
|
||||||
|
List[Peer],
|
||||||
|
)
|
||||||
|
await request.notify_peers_change()
|
||||||
|
|
||||||
|
|
||||||
|
async def get() -> List[tuple[Peer, bool]]:
|
||||||
|
"""Get all peers with liveness info."""
|
||||||
|
peers = config_manager.get_config(HffsConfigOption.PEERS, List[Peer])
|
||||||
|
|
||||||
|
# get_alive_peers uses Peer in HffsContext intead of Peer in HffsConfig
|
||||||
|
alives = {Peer(ip=p.ip, port=p.port) for p in await request.get_alive_peers()}
|
||||||
|
|
||||||
|
return [(peer, peer in alives) for peer in peers]
|
||||||
|
|
@ -1,60 +0,0 @@
|
||||||
import logging
|
|
||||||
import urllib3
|
|
||||||
|
|
||||||
from typing import List
|
|
||||||
from ..common.peer import Peer
|
|
||||||
from .http_client import notify_peer_change, alive_peers
|
|
||||||
|
|
||||||
|
|
||||||
def check_valid_ip_port(ip, port):
|
|
||||||
converted_url = "{}:{}".format(ip, port)
|
|
||||||
|
|
||||||
try:
|
|
||||||
parsed_url = urllib3.util.parse_url(converted_url)
|
|
||||||
|
|
||||||
if not parsed_url.host or not parsed_url.port:
|
|
||||||
raise ValueError("Should be not None!")
|
|
||||||
except Exception:
|
|
||||||
raise ValueError("Invalid IP or port format! IP: {}, port:{}".format(ip, port))
|
|
||||||
|
|
||||||
|
|
||||||
class PeerManager:
|
|
||||||
DEFAULT_PORT = 9009
|
|
||||||
|
|
||||||
def __init__(self, peer_store):
|
|
||||||
self._peer_store = peer_store
|
|
||||||
|
|
||||||
def add_peer(self, ip, port=None):
|
|
||||||
peer_port = port if port else self.DEFAULT_PORT
|
|
||||||
check_valid_ip_port(ip, port)
|
|
||||||
peer = Peer(ip, peer_port)
|
|
||||||
self._peer_store.add_peer(peer)
|
|
||||||
logging.info("Add success!")
|
|
||||||
|
|
||||||
def remove_peer(self, ip, port=None):
|
|
||||||
peer_port = port if port else self.DEFAULT_PORT
|
|
||||||
check_valid_ip_port(ip, port)
|
|
||||||
peer = Peer(ip, peer_port)
|
|
||||||
self._peer_store.remove_peer(peer)
|
|
||||||
logging.info("Remove success!")
|
|
||||||
|
|
||||||
def get_peers(self) -> List[Peer]:
|
|
||||||
return self._peer_store.get_peers()
|
|
||||||
|
|
||||||
async def list_peers(self):
|
|
||||||
alives = await alive_peers()
|
|
||||||
alives = set(alives)
|
|
||||||
|
|
||||||
peers = sorted(self.get_peers())
|
|
||||||
|
|
||||||
if len(peers) == 0:
|
|
||||||
print("No peer is configured.")
|
|
||||||
return
|
|
||||||
|
|
||||||
print("List of peers:")
|
|
||||||
for peer in peers:
|
|
||||||
alive = "alive" if peer in alives else ""
|
|
||||||
print(f"{peer.ip}\t{peer.port}\t{alive}")
|
|
||||||
|
|
||||||
async def notify_peer_change(self):
|
|
||||||
await notify_peer_change()
|
|
||||||
|
|
@ -0,0 +1,46 @@
|
||||||
|
"""Uninstall HFFS by removing related directories."""
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import shutil
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.config import config_manager
|
||||||
|
from hffs.config.hffs_config import CONFIG_DIR, HffsConfigOption
|
||||||
|
from hffs.daemon import manager as daemon_manager
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
async def _uninstall() -> None:
|
||||||
|
if await daemon_manager.daemon_is_running():
|
||||||
|
logger.info("Stop daemon first by executing 'hffs daemon stop'.")
|
||||||
|
return
|
||||||
|
|
||||||
|
warning = (
|
||||||
|
"WARNING: 'Uninstall' will delete all hffs data on disk, "
|
||||||
|
"and it's not recoverable!."
|
||||||
|
)
|
||||||
|
logging.info(warning)
|
||||||
|
|
||||||
|
confirm = input("Please enter 'Y/y' to confirm uninstall: ")
|
||||||
|
|
||||||
|
if confirm not in ["Y", "y"]:
|
||||||
|
logger.info("Cancel uninstall.")
|
||||||
|
return
|
||||||
|
|
||||||
|
cache_dir = config_manager.get_config(HffsConfigOption.CACHE, str)
|
||||||
|
home_dir = str(CONFIG_DIR)
|
||||||
|
to_rm = [cache_dir, home_dir]
|
||||||
|
|
||||||
|
for d in to_rm:
|
||||||
|
shutil.rmtree(d, ignore_errors=True)
|
||||||
|
|
||||||
|
logger.info("HFFS is uninstalled.")
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.command == "uninstall":
|
||||||
|
await _uninstall()
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -1,32 +0,0 @@
|
||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding: utf-8 -*-
|
|
||||||
|
|
||||||
import logging
|
|
||||||
import shutil
|
|
||||||
|
|
||||||
from ..common.settings import HFFS_HOME
|
|
||||||
from .daemon_manager import daemon_stop
|
|
||||||
|
|
||||||
|
|
||||||
async def uninstall_hffs():
|
|
||||||
logging.warning("WARNING: will delete all hffs data on disk, can't recovery it!")
|
|
||||||
|
|
||||||
logging.info("\n{}\n".format(HFFS_HOME))
|
|
||||||
|
|
||||||
first_confirm = input("UP directory will be delete! Enter y/Y to confirm:")
|
|
||||||
|
|
||||||
if first_confirm not in ["y", "Y"]:
|
|
||||||
logging.info("Canceled uninstall!")
|
|
||||||
return
|
|
||||||
|
|
||||||
second_confirm = input("\nPlease enter y/Y confirm it again, then start uninstall: ")
|
|
||||||
|
|
||||||
if second_confirm not in ["y", "Y"]:
|
|
||||||
logging.info("Canceled uninstall!")
|
|
||||||
return
|
|
||||||
|
|
||||||
await daemon_stop()
|
|
||||||
shutil.rmtree(HFFS_HOME, ignore_errors=True)
|
|
||||||
|
|
||||||
print("Uninstall success!")
|
|
||||||
|
|
||||||
|
|
@ -0,0 +1,30 @@
|
||||||
|
"""Settings for HFFS daemon service."""
|
||||||
|
|
||||||
|
from aiohttp import ClientTimeout
|
||||||
|
|
||||||
|
ApiType = str
|
||||||
|
|
||||||
|
API_PREFIX: ApiType = "/hffs_api/{service}"
|
||||||
|
|
||||||
|
API_PEERS_PROBE: ApiType = API_PREFIX.format(service="peers/ping")
|
||||||
|
|
||||||
|
API_DAEMON_RUNNING: ApiType = API_PREFIX.format(service="daemon/status")
|
||||||
|
API_DAEMON_STOP: ApiType = API_PREFIX.format(service="daemon/stop")
|
||||||
|
API_DAEMON_PEERS_ALIVE: ApiType = API_PREFIX.format(
|
||||||
|
service="daemon/peers_alive",
|
||||||
|
)
|
||||||
|
API_DAEMON_PEERS_CHANGE: ApiType = API_PREFIX.format(
|
||||||
|
service="daemon/peers_change",
|
||||||
|
)
|
||||||
|
|
||||||
|
API_FETCH_FILE_CLIENT: ApiType = "/{repo}/resolve/{revision}/{file_name}"
|
||||||
|
API_FETCH_FILE_DAEMON: ApiType = "/{user}/{model}/resolve/{revision}/{file_name:.*}"
|
||||||
|
API_FETCH_REPO_FILE_LIST: ApiType = API_PREFIX.format(
|
||||||
|
service="fetch/repo_file_list/{user}/{model}/{revision}"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# timeout in sec
|
||||||
|
TIMEOUT_PEERS = ClientTimeout(total=10)
|
||||||
|
TIMEOUT_DAEMON = ClientTimeout(total=2)
|
||||||
|
TIMEOUT_FETCH = ClientTimeout(total=30)
|
||||||
|
|
@ -0,0 +1,151 @@
|
||||||
|
"""Define HFFS context."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import TYPE_CHECKING, List
|
||||||
|
|
||||||
|
from hffs.common.peer import Peer
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from hffs.config.hffs_config import HffsConfig
|
||||||
|
from hffs.daemon.prober import PeerProber
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass()
|
||||||
|
class HffsContext:
|
||||||
|
"""HFFS context."""
|
||||||
|
|
||||||
|
# properties
|
||||||
|
port: int = field()
|
||||||
|
model_dir: Path = field()
|
||||||
|
etag_dir: Path = field()
|
||||||
|
log_dir: Path = field()
|
||||||
|
repo_files_dir: Path = field()
|
||||||
|
peers: List[Peer] = field()
|
||||||
|
peer_prober: PeerProber | None = field(
|
||||||
|
default=None,
|
||||||
|
init=False,
|
||||||
|
repr=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
# global context reference
|
||||||
|
_instance: HffsContext | None = field(
|
||||||
|
default=None,
|
||||||
|
init=False,
|
||||||
|
repr=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def init_with_config(cls, config: HffsConfig) -> HffsContext:
|
||||||
|
"""Create HFFS context from configuration."""
|
||||||
|
cls._instance = cls(
|
||||||
|
port=config.daemon_port,
|
||||||
|
model_dir=Path(config.cache_dir) / "models",
|
||||||
|
etag_dir=Path(config.cache_dir) / "etags",
|
||||||
|
log_dir=Path(config.cache_dir) / "logs",
|
||||||
|
repo_files_dir=Path(config.cache_dir) / "repo_files",
|
||||||
|
peers=[Peer(ip=p.ip, port=p.port) for p in config.peers],
|
||||||
|
)
|
||||||
|
if not cls.get_model_dir().exists():
|
||||||
|
cls.get_model_dir().mkdir(parents=True, exist_ok=True)
|
||||||
|
if not cls.get_etag_dir().exists():
|
||||||
|
cls.get_etag_dir().mkdir(parents=True, exist_ok=True)
|
||||||
|
if not cls.get_log_dir().exists():
|
||||||
|
cls.get_log_dir().mkdir(parents=True, exist_ok=True)
|
||||||
|
if not cls.get_repo_files_dir().exists():
|
||||||
|
cls.get_repo_files_dir().mkdir(parents=True, exist_ok=True)
|
||||||
|
return cls._instance
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_port(cls) -> int:
|
||||||
|
"""Get port."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.port
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_model_dir(cls) -> Path:
|
||||||
|
"""Get model dir."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.model_dir
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_model_dir_str(cls) -> str:
|
||||||
|
"""Get model dir in str."""
|
||||||
|
return str(cls.get_model_dir())
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_etag_dir(cls) -> Path:
|
||||||
|
"""Get etag dir."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.etag_dir
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_log_dir(cls) -> Path:
|
||||||
|
"""Get log dir."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.log_dir
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_repo_files_dir(cls) -> Path:
|
||||||
|
"""Get repo file list dir."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.repo_files_dir
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_peers(cls) -> List[Peer]:
|
||||||
|
"""Get peers."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.peers
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def update_peers(
|
||||||
|
cls,
|
||||||
|
conf: HffsConfig,
|
||||||
|
old_peers: List[Peer],
|
||||||
|
) -> List[Peer]:
|
||||||
|
"""Load peers from config and then update their states."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
new_peers = [Peer(ip=p.ip, port=p.port) for p in conf.peers]
|
||||||
|
peer_map = {p: p for p in new_peers}
|
||||||
|
|
||||||
|
for peer in old_peers:
|
||||||
|
if peer in peer_map: # peer match by ip and port
|
||||||
|
peer_map[peer].alive = peer.alive
|
||||||
|
peer_map[peer].epoch = peer.epoch
|
||||||
|
|
||||||
|
cls._instance.peers = list(peer_map.values())
|
||||||
|
|
||||||
|
return cls._instance.peers
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_daemon(cls) -> Peer:
|
||||||
|
"""Get local daemon."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
return Peer(ip="127.0.0.1", port=cls._instance.port)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def set_peer_prober(cls, peer_prober: PeerProber) -> None:
|
||||||
|
"""Set peer prober."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
cls._instance.peer_prober = peer_prober
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_peer_prober(cls) -> PeerProber:
|
||||||
|
"""Get peer prober."""
|
||||||
|
if not cls._instance:
|
||||||
|
raise ValueError
|
||||||
|
if not cls._instance.peer_prober:
|
||||||
|
raise ValueError
|
||||||
|
return cls._instance.peer_prober
|
||||||
|
|
@ -0,0 +1,68 @@
|
||||||
|
"""Manager etags for HFFS model files.
|
||||||
|
|
||||||
|
This module provides functions to manage etags for Hugging Face model files.
|
||||||
|
It is needed because huggingface_hub 0.23.0 does not save etags of model files
|
||||||
|
on Windows.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import huggingface_hub as hf # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_etag_path(repo_id: str, filename: str, revision: str) -> Path | None:
|
||||||
|
model_path = hf.try_to_load_from_cache(
|
||||||
|
repo_id=repo_id,
|
||||||
|
filename=filename,
|
||||||
|
revision=revision,
|
||||||
|
cache_dir=HffsContext.get_model_dir_str(),
|
||||||
|
)
|
||||||
|
|
||||||
|
# model_path type is (str | Any | None)
|
||||||
|
if model_path is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if not isinstance(model_path, str):
|
||||||
|
return None
|
||||||
|
|
||||||
|
rel_path = Path(model_path).relative_to(HffsContext.get_model_dir())
|
||||||
|
return HffsContext.get_etag_dir() / rel_path
|
||||||
|
|
||||||
|
|
||||||
|
def load_etag(repo_id: str, file_name: str, revision: str) -> str | None:
|
||||||
|
"""Load etag value from a etag cache file."""
|
||||||
|
etag_path = _get_etag_path(repo_id, file_name, revision)
|
||||||
|
|
||||||
|
if not etag_path or not etag_path.exists():
|
||||||
|
return None
|
||||||
|
|
||||||
|
return etag_path.read_text().strip()
|
||||||
|
|
||||||
|
|
||||||
|
def save_etag(etag: str, repo_id: str, file_name: str, revision: str) -> None:
|
||||||
|
"""Save etag value to a etag cache file."""
|
||||||
|
etag_path = _get_etag_path(repo_id, file_name, revision)
|
||||||
|
|
||||||
|
if not etag_path:
|
||||||
|
logger.debug(
|
||||||
|
"Failed to get etag path: repo_id=%s, file_name=%s, revision=%s",
|
||||||
|
repo_id,
|
||||||
|
file_name,
|
||||||
|
revision,
|
||||||
|
)
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
if not etag_path.parent.exists():
|
||||||
|
etag_path.parent.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
if not etag_path.exists():
|
||||||
|
etag_path.touch()
|
||||||
|
|
||||||
|
etag_path.write_text(etag)
|
||||||
|
|
@ -1,96 +0,0 @@
|
||||||
import os
|
|
||||||
import huggingface_hub as hf
|
|
||||||
from . import settings
|
|
||||||
|
|
||||||
|
|
||||||
def get_sym_path(repo_path, commit_hash, file_path):
|
|
||||||
return os.path.normpath(f"{repo_path}/snapshots/{commit_hash}/{file_path}")
|
|
||||||
|
|
||||||
|
|
||||||
def file_in_cache(repo_id, file_name, revision="main"):
|
|
||||||
# see https://huggingface.co/docs/huggingface_hub/v0.23.0/en/package_reference/cache
|
|
||||||
# for API about HFCacheInfo, CachedRepoInfo, CachedRevisionInfo, CachedFileInfo
|
|
||||||
|
|
||||||
cache_info = hf.scan_cache_dir(settings.HFFS_MODEL_DIR)
|
|
||||||
|
|
||||||
repo_info = None
|
|
||||||
repo_path = None
|
|
||||||
for repo in cache_info.repos:
|
|
||||||
if repo.repo_id == repo_id:
|
|
||||||
repo_info = repo
|
|
||||||
repo_path = repo.repo_path
|
|
||||||
break
|
|
||||||
|
|
||||||
if repo_info is None:
|
|
||||||
return None # no matching repo
|
|
||||||
|
|
||||||
commit_hash = None
|
|
||||||
rev_info = None
|
|
||||||
for rev in repo_info.revisions:
|
|
||||||
if rev.commit_hash.startswith(revision) or revision in rev.refs:
|
|
||||||
commit_hash = rev.commit_hash
|
|
||||||
rev_info = rev
|
|
||||||
break
|
|
||||||
|
|
||||||
if commit_hash is None:
|
|
||||||
return None # no matching revision
|
|
||||||
|
|
||||||
etag = None
|
|
||||||
size = None
|
|
||||||
file_path = None
|
|
||||||
sym_path = get_sym_path(repo_path, commit_hash, file_name)
|
|
||||||
|
|
||||||
for f in rev_info.files:
|
|
||||||
if sym_path == str(f.file_path):
|
|
||||||
size = f.size_on_disk
|
|
||||||
etag = try_to_load_etag(repo_id, file_name, revision)
|
|
||||||
file_path = f.file_path
|
|
||||||
break
|
|
||||||
|
|
||||||
if file_path is None:
|
|
||||||
return None # no matching file
|
|
||||||
|
|
||||||
return {
|
|
||||||
"etag": etag,
|
|
||||||
"commit_hash": commit_hash,
|
|
||||||
"size": size,
|
|
||||||
"file_path": file_path
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
def get_etag_path(repo_id, filename, revision="main"):
|
|
||||||
model_path = hf.try_to_load_from_cache(
|
|
||||||
repo_id=repo_id,
|
|
||||||
filename=filename,
|
|
||||||
cache_dir=settings.HFFS_MODEL_DIR,
|
|
||||||
revision=revision,
|
|
||||||
)
|
|
||||||
|
|
||||||
if model_path == hf._CACHED_NO_EXIST:
|
|
||||||
return None
|
|
||||||
|
|
||||||
file_path = os.path.relpath(model_path, settings.HFFS_MODEL_DIR)
|
|
||||||
return os.path.join(settings.HFFS_ETAG_DIR, file_path)
|
|
||||||
|
|
||||||
|
|
||||||
def try_to_load_etag(repo_id, filename, revision="main"):
|
|
||||||
etag_path = get_etag_path(repo_id, filename, revision)
|
|
||||||
|
|
||||||
if not etag_path or not os.path.exists(etag_path):
|
|
||||||
return None
|
|
||||||
|
|
||||||
with open(etag_path, "r") as f:
|
|
||||||
return f.read().strip()
|
|
||||||
|
|
||||||
|
|
||||||
def save_etag(etag, repo_id, filename, revision="main"):
|
|
||||||
etag_path = get_etag_path(repo_id, filename, revision)
|
|
||||||
|
|
||||||
if not etag_path:
|
|
||||||
raise ValueError(
|
|
||||||
f"Failed to get etag path for repo={repo_id}, file={filename}, revision={revision}")
|
|
||||||
|
|
||||||
os.makedirs(os.path.dirname(etag_path), exist_ok=True)
|
|
||||||
|
|
||||||
with open(etag_path, "w+") as f:
|
|
||||||
f.write(etag)
|
|
||||||
|
|
@ -0,0 +1,109 @@
|
||||||
|
"""A wrapper of huggingface_hub api."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
import logging
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
import huggingface_hub as hf # type: ignore[import-untyped]
|
||||||
|
from huggingface_hub.hf_api import HfApi # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.repo_files import RepoFileList
|
||||||
|
|
||||||
|
COMMIT_HASH_HEADER = hf.constants.HUGGINGFACE_HEADER_X_REPO_COMMIT
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def get_cache_info() -> hf.HFCacheInfo:
|
||||||
|
"""Get cache info."""
|
||||||
|
return hf.scan_cache_dir(HffsContext.get_model_dir_str())
|
||||||
|
|
||||||
|
|
||||||
|
def get_repo_info(repo_id: str) -> hf.CachedRepoInfo | None:
|
||||||
|
"""Get repo info by repo_id."""
|
||||||
|
cache_info = get_cache_info()
|
||||||
|
for repo in cache_info.repos:
|
||||||
|
if repo.repo_id == repo_id:
|
||||||
|
return repo
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def get_revision_info(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> hf.CachedRevisionInfo | None:
|
||||||
|
"""Get revision info by revision."""
|
||||||
|
repo_info = get_repo_info(repo_id)
|
||||||
|
|
||||||
|
if repo_info is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
for rev in repo_info.revisions:
|
||||||
|
if revision in rev.refs or rev.commit_hash.startswith(revision):
|
||||||
|
return rev
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def get_file_info(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
filename: str,
|
||||||
|
) -> hf.CachedFileInfo | None:
|
||||||
|
"""Get file info by filename."""
|
||||||
|
rev_info = get_revision_info(repo_id, revision)
|
||||||
|
|
||||||
|
if rev_info is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
for f in rev_info.files:
|
||||||
|
if rev_info.snapshot_path / filename == f.file_path:
|
||||||
|
return f
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def get_repo_file_list(
|
||||||
|
endpoint: str,
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> RepoFileList | None:
|
||||||
|
"""Load repo struct."""
|
||||||
|
fs = hf.HfFileSystem(endpoint=endpoint)
|
||||||
|
repo = f"{repo_id}@{revision}/"
|
||||||
|
path = f"hf://{repo}"
|
||||||
|
try:
|
||||||
|
beg = len(repo)
|
||||||
|
return [f[beg:] for f in fs.find(path)]
|
||||||
|
except (ValueError, OSError, IOError):
|
||||||
|
logger.debug(
|
||||||
|
"Cannot load repo file list for %s, %s, %s",
|
||||||
|
endpoint,
|
||||||
|
repo_id,
|
||||||
|
revision,
|
||||||
|
)
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def verify_revision(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
endpoints: List[str],
|
||||||
|
) -> str | None:
|
||||||
|
"""Verify if revision is valid."""
|
||||||
|
# verify with local cache
|
||||||
|
rev_info = get_revision_info(repo_id, revision)
|
||||||
|
if rev_info:
|
||||||
|
return rev_info.commit_hash
|
||||||
|
|
||||||
|
# verify with remote endpoints
|
||||||
|
for endpoint in endpoints:
|
||||||
|
api = HfApi(endpoint=endpoint)
|
||||||
|
try:
|
||||||
|
model = api.model_info(repo_id, revision=revision)
|
||||||
|
if model and model.sha:
|
||||||
|
return model.sha
|
||||||
|
except (OSError, IOError, ValueError):
|
||||||
|
continue
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
@ -1,61 +1,13 @@
|
||||||
|
"""Context Peer definition for HFFS."""
|
||||||
|
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass(order=True, unsafe_hash=True)
|
||||||
class Peer:
|
class Peer:
|
||||||
def __init__(self, ip, port) -> None:
|
"""Peer definition for HFFS."""
|
||||||
self._ip = ip
|
|
||||||
self._port = int(port)
|
|
||||||
self._alive = False
|
|
||||||
self._epoch = 0
|
|
||||||
|
|
||||||
@property
|
ip: str = field(hash=True)
|
||||||
def ip(self):
|
port: int = field(hash=True)
|
||||||
return self._ip
|
alive: bool = field(compare=False, default=False)
|
||||||
|
epoch: int = field(compare=False, default=0)
|
||||||
@property
|
|
||||||
def port(self):
|
|
||||||
return self._port
|
|
||||||
|
|
||||||
def is_alive(self):
|
|
||||||
return self._alive
|
|
||||||
|
|
||||||
def set_alive(self, alive):
|
|
||||||
self._alive = alive
|
|
||||||
|
|
||||||
def set_epoch(self, epoch):
|
|
||||||
self._epoch = epoch
|
|
||||||
|
|
||||||
def get_epoch(self):
|
|
||||||
return self._epoch
|
|
||||||
|
|
||||||
def __lt__(self, value):
|
|
||||||
if not isinstance(value, Peer):
|
|
||||||
raise TypeError()
|
|
||||||
if self.ip < value.ip:
|
|
||||||
return True
|
|
||||||
elif self.port < value.port:
|
|
||||||
return True
|
|
||||||
else:
|
|
||||||
return False
|
|
||||||
|
|
||||||
def __eq__(self, value: object) -> bool:
|
|
||||||
return isinstance(value, Peer) and self.ip == value.ip and self.port == value.port
|
|
||||||
|
|
||||||
def __hash__(self) -> int:
|
|
||||||
return hash((self.ip, self.port))
|
|
||||||
|
|
||||||
def __repr__(self) -> str:
|
|
||||||
return f"{self.ip}:{self.port}"
|
|
||||||
|
|
||||||
def to_dict(self):
|
|
||||||
return {
|
|
||||||
"ip": self.ip,
|
|
||||||
"port": self.port
|
|
||||||
}
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def from_dict(cls, data):
|
|
||||||
return cls(data["ip"], data["port"])
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def print_peers(cls, peers):
|
|
||||||
return [f"{p}" for p in peers]
|
|
||||||
|
|
|
||||||
|
|
@ -1,52 +0,0 @@
|
||||||
import os
|
|
||||||
from .peer import Peer
|
|
||||||
from .settings import HFFS_HOME, HFFS_PEER_CONF
|
|
||||||
import logging
|
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
|
||||||
|
|
||||||
|
|
||||||
def create_file():
|
|
||||||
os.makedirs(HFFS_HOME, exist_ok=True)
|
|
||||||
if not os.path.exists(HFFS_PEER_CONF):
|
|
||||||
with open(HFFS_PEER_CONF, "w", encoding="utf-8"):
|
|
||||||
logger.debug(f"Created {HFFS_PEER_CONF}")
|
|
||||||
|
|
||||||
|
|
||||||
class PeerStore:
|
|
||||||
def __init__(self):
|
|
||||||
self._peers = set()
|
|
||||||
|
|
||||||
def __enter__(self):
|
|
||||||
self.open()
|
|
||||||
return self
|
|
||||||
|
|
||||||
def __exit__(self, type, value, traceback):
|
|
||||||
if traceback:
|
|
||||||
logger.debug(f"PeerStore error, type=<{type}>, value=<{value}>")
|
|
||||||
self.close()
|
|
||||||
|
|
||||||
def _load_peers(self):
|
|
||||||
with open(HFFS_PEER_CONF, "r+", encoding="utf-8") as f:
|
|
||||||
for line in f:
|
|
||||||
ip, port = line.strip().split(":")
|
|
||||||
peer = Peer(ip, port)
|
|
||||||
self._peers.add(peer)
|
|
||||||
|
|
||||||
def open(self):
|
|
||||||
create_file()
|
|
||||||
self._load_peers()
|
|
||||||
|
|
||||||
def close(self):
|
|
||||||
with open(HFFS_PEER_CONF, "w", encoding="utf-8") as f:
|
|
||||||
for peer in self._peers:
|
|
||||||
f.write(f"{peer.ip}:{peer.port}\n")
|
|
||||||
|
|
||||||
def add_peer(self, peer):
|
|
||||||
self._peers.add(peer)
|
|
||||||
|
|
||||||
def remove_peer(self, peer):
|
|
||||||
self._peers.discard(peer)
|
|
||||||
|
|
||||||
def get_peers(self):
|
|
||||||
return self._peers
|
|
||||||
|
|
@ -0,0 +1,42 @@
|
||||||
|
"""Handling repo file list."""
|
||||||
|
|
||||||
|
import json
|
||||||
|
import logging
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import List, Optional
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
|
||||||
|
RepoFileList = List[str]
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _file_list_local_file(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> Path:
|
||||||
|
return HffsContext.get_repo_files_dir() / repo_id / revision / "files.json"
|
||||||
|
|
||||||
|
|
||||||
|
def load_file_list(
|
||||||
|
repo_id: str,
|
||||||
|
revision: str,
|
||||||
|
) -> Optional[RepoFileList]:
|
||||||
|
"""Load repo file list from local config."""
|
||||||
|
path = _file_list_local_file(repo_id, revision)
|
||||||
|
if not path.exists():
|
||||||
|
return None
|
||||||
|
return json.loads(path.read_text())
|
||||||
|
|
||||||
|
|
||||||
|
def save_file_list(repo_id: str, revision: str, files: RepoFileList) -> None:
|
||||||
|
"""Save repo file list to local config."""
|
||||||
|
path = _file_list_local_file(repo_id, revision)
|
||||||
|
try:
|
||||||
|
if not path.exists():
|
||||||
|
path.parent.mkdir(parents=True, exist_ok=True)
|
||||||
|
path.touch()
|
||||||
|
path.write_text(json.dumps(files))
|
||||||
|
except (ValueError, IOError, OSError) as e:
|
||||||
|
logger.debug("Error when saving file list.", exc_info=e)
|
||||||
|
|
@ -1,39 +0,0 @@
|
||||||
#!/usr/bin/env python3
|
|
||||||
# -*- coding: utf-8 -*-
|
|
||||||
|
|
||||||
import os
|
|
||||||
import configparser
|
|
||||||
|
|
||||||
HFFS_HOME_DEFAULT = os.path.join(os.path.expanduser("~"), ".cache/hffs")
|
|
||||||
HFFS_HOME = os.environ.get("HFFS_HOME", HFFS_HOME_DEFAULT)
|
|
||||||
HFFS_PEER_CONF = os.path.join(HFFS_HOME, "hffs_peers.conf")
|
|
||||||
HFFS_MODEL_DIR = os.path.join(HFFS_HOME, "models")
|
|
||||||
HFFS_ETAG_DIR = os.path.join(HFFS_HOME, "etags")
|
|
||||||
HFFS_CONF = os.path.join(HFFS_HOME, "hffs.conf")
|
|
||||||
HFFS_LOG_DIR = os.path.join(HFFS_HOME, "logs")
|
|
||||||
HFFS_EXEC_NAME = "hffs"
|
|
||||||
|
|
||||||
|
|
||||||
HFFS_API_PING = "/hffs_api/ping"
|
|
||||||
HFFS_API_ALIVE_PEERS = "/hffs_api/alive_peers"
|
|
||||||
HFFS_API_PEER_CHANGE = "/hffs_api/peer_change"
|
|
||||||
HFFS_API_STATUS = "/hffs_api/status"
|
|
||||||
HFFS_API_STOP = "/hffs_api/stop"
|
|
||||||
|
|
||||||
|
|
||||||
def save_local_service_port(port):
|
|
||||||
config = configparser.ConfigParser()
|
|
||||||
config["DEFAULT"] = {"SERVICE_PORT": str(port)}
|
|
||||||
|
|
||||||
with open(HFFS_CONF, "w") as f:
|
|
||||||
config.write(f)
|
|
||||||
|
|
||||||
|
|
||||||
def load_local_service_port():
|
|
||||||
config = configparser.ConfigParser()
|
|
||||||
|
|
||||||
if not os.path.exists(HFFS_CONF):
|
|
||||||
raise LookupError("Service port not found, have service start?")
|
|
||||||
|
|
||||||
config.read(HFFS_CONF)
|
|
||||||
return int(config["DEFAULT"]["SERVICE_PORT"])
|
|
||||||
|
|
@ -0,0 +1,58 @@
|
||||||
|
"""Configuration related commands."""
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.config import config_manager
|
||||||
|
from hffs.config.hffs_config import HffsConfigOption
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _configure_cache(args: Namespace) -> None:
|
||||||
|
if args.conf_cache_command == "set":
|
||||||
|
conf = config_manager.set_config(
|
||||||
|
HffsConfigOption.CACHE,
|
||||||
|
args.path,
|
||||||
|
str,
|
||||||
|
)
|
||||||
|
logger.info("Set HFFS cache path: %s", conf)
|
||||||
|
elif args.conf_cache_command == "get":
|
||||||
|
conf = config_manager.get_config(HffsConfigOption.CACHE, str)
|
||||||
|
logger.info("HFFS cache path: %s", conf)
|
||||||
|
elif args.conf_cache_command == "reset":
|
||||||
|
conf = config_manager.reset_config(HffsConfigOption.CACHE, str)
|
||||||
|
logger.info("Reset HFFS cache path: %s", conf)
|
||||||
|
|
||||||
|
|
||||||
|
def _configure_port(args: Namespace) -> None:
|
||||||
|
if args.conf_port_command == "set":
|
||||||
|
conf = config_manager.set_config(
|
||||||
|
HffsConfigOption.PORT,
|
||||||
|
args.port,
|
||||||
|
str,
|
||||||
|
)
|
||||||
|
logger.info("Set HFFS port: %s", conf)
|
||||||
|
elif args.conf_port_command == "get":
|
||||||
|
conf = config_manager.get_config(HffsConfigOption.PORT, str)
|
||||||
|
logger.info("HFFS port: %s", conf)
|
||||||
|
elif args.conf_port_command == "reset":
|
||||||
|
conf = config_manager.reset_config(HffsConfigOption.PORT, str)
|
||||||
|
logger.info("Reset HFFS port: %s", conf)
|
||||||
|
|
||||||
|
|
||||||
|
def _show_config() -> None:
|
||||||
|
content = config_manager.get_config_yaml()
|
||||||
|
logger.info(content)
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.conf_command == "cache":
|
||||||
|
_configure_cache(args)
|
||||||
|
elif args.conf_command == "port":
|
||||||
|
_configure_port(args)
|
||||||
|
elif args.conf_command == "show":
|
||||||
|
_show_config()
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -0,0 +1,75 @@
|
||||||
|
"""Initialize, load, and save configuration settings."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from typing import TypeVar, cast
|
||||||
|
|
||||||
|
from hffs.utils.yaml import yaml_dump, yaml_load
|
||||||
|
|
||||||
|
from .hffs_config import (
|
||||||
|
CONFIG_DIR,
|
||||||
|
CONFIG_FILE,
|
||||||
|
HffsConfig,
|
||||||
|
)
|
||||||
|
from .hffs_config import (
|
||||||
|
HffsConfigOption as ConfOpt,
|
||||||
|
)
|
||||||
|
|
||||||
|
DEFAULT_CONFIG = HffsConfig()
|
||||||
|
|
||||||
|
|
||||||
|
def init_config() -> None:
|
||||||
|
"""Initialize HFFS configuration."""
|
||||||
|
if not CONFIG_DIR.exists():
|
||||||
|
CONFIG_DIR.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
|
if not CONFIG_FILE.exists():
|
||||||
|
CONFIG_FILE.touch()
|
||||||
|
|
||||||
|
# create yaml files based on the configuration settings
|
||||||
|
CONFIG_FILE.write_text(yaml_dump(DEFAULT_CONFIG))
|
||||||
|
|
||||||
|
|
||||||
|
def load_config() -> HffsConfig:
|
||||||
|
"""Load HFFS configuration."""
|
||||||
|
if not CONFIG_FILE.exists():
|
||||||
|
init_config()
|
||||||
|
|
||||||
|
conf_dict = yaml_load(CONFIG_FILE)
|
||||||
|
return HffsConfig.model_validate(conf_dict)
|
||||||
|
|
||||||
|
|
||||||
|
def save_config(config: HffsConfig) -> None:
|
||||||
|
"""Save HFFS configuration."""
|
||||||
|
if not CONFIG_FILE.exists():
|
||||||
|
init_config()
|
||||||
|
|
||||||
|
CONFIG_FILE.write_text(yaml_dump(config))
|
||||||
|
|
||||||
|
|
||||||
|
def get_config_yaml() -> str:
|
||||||
|
"""Get HFFS configuration in yaml format."""
|
||||||
|
return CONFIG_FILE.read_text()
|
||||||
|
|
||||||
|
|
||||||
|
T = TypeVar("T")
|
||||||
|
|
||||||
|
|
||||||
|
def get_config(opt: ConfOpt, _: type[T]) -> T:
|
||||||
|
"""Get a specific configuration option."""
|
||||||
|
config = load_config()
|
||||||
|
return cast(T, getattr(config, opt.value))
|
||||||
|
|
||||||
|
|
||||||
|
def set_config(opt: ConfOpt, value: T, _: type[T]) -> T:
|
||||||
|
"""Set a specific configuration option."""
|
||||||
|
config = load_config()
|
||||||
|
setattr(config, opt.value, cast(T, value))
|
||||||
|
save_config(config)
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
|
def reset_config(opt: ConfOpt, conf_type: type[T]) -> T:
|
||||||
|
"""Reset a specific configuration option."""
|
||||||
|
value = cast(T, getattr(DEFAULT_CONFIG, opt.value))
|
||||||
|
return set_config(opt, value, conf_type)
|
||||||
|
|
@ -0,0 +1,67 @@
|
||||||
|
"""HFFS Configuration Class."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from enum import Enum
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
CONFIG_DIR = Path.home() / ".hffs"
|
||||||
|
CONFIG_FILE = CONFIG_DIR / "config.yaml"
|
||||||
|
|
||||||
|
DEFAULT_CACHE_DIR = Path.home() / ".cache" / "hffs"
|
||||||
|
DEFAULT_DAEMON_PORT = 9090
|
||||||
|
|
||||||
|
|
||||||
|
class Peer(BaseModel):
|
||||||
|
"""Peer definition for HFFS."""
|
||||||
|
|
||||||
|
ip: str = Field(exclude=False, frozen=True)
|
||||||
|
port: int = Field(exclude=False, frozen=True)
|
||||||
|
|
||||||
|
def __lt__(self, other: object) -> bool:
|
||||||
|
"""Return True if self is less than other."""
|
||||||
|
if isinstance(other, Peer):
|
||||||
|
return self.ip < other.ip or (
|
||||||
|
self.ip == other.ip and self.port < other.port
|
||||||
|
)
|
||||||
|
return NotImplemented
|
||||||
|
|
||||||
|
def __eq__(self, other: object) -> bool:
|
||||||
|
"""Return True if self is equal to other."""
|
||||||
|
if isinstance(other, Peer):
|
||||||
|
return self.ip == other.ip and self.port == other.port
|
||||||
|
return NotImplemented
|
||||||
|
|
||||||
|
def __hash__(self) -> int:
|
||||||
|
"""Return the hash value of the Peer."""
|
||||||
|
return hash((self.ip, self.port))
|
||||||
|
|
||||||
|
|
||||||
|
class HffsConfigOption(str, Enum):
|
||||||
|
"""HFFS configuration options."""
|
||||||
|
|
||||||
|
CACHE: str = "cache_dir"
|
||||||
|
PORT: str = "daemon_port"
|
||||||
|
PEERS: str = "peers"
|
||||||
|
|
||||||
|
|
||||||
|
class HffsConfig(BaseModel):
|
||||||
|
"""Data class for HFFS directory configuration."""
|
||||||
|
|
||||||
|
cache_dir: str = Field(
|
||||||
|
description="Directory for storing cache files",
|
||||||
|
default=str(DEFAULT_CACHE_DIR),
|
||||||
|
)
|
||||||
|
|
||||||
|
peers: List[Peer] = Field(
|
||||||
|
description="List of peers",
|
||||||
|
default_factory=list,
|
||||||
|
)
|
||||||
|
|
||||||
|
daemon_port: int = Field(
|
||||||
|
description="Port for the daemon",
|
||||||
|
default=DEFAULT_DAEMON_PORT,
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
"""Daemon related commands."""
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.daemon import manager as daemon_manager
|
||||||
|
from hffs.daemon import server
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
async def _daemon_start(args: Namespace) -> None:
|
||||||
|
if await daemon_manager.daemon_start(args):
|
||||||
|
logger.info("Daemon started.")
|
||||||
|
else:
|
||||||
|
logger.error("Daemon failed to start.")
|
||||||
|
|
||||||
|
|
||||||
|
async def _daemon_start_detached() -> None:
|
||||||
|
await server.start()
|
||||||
|
|
||||||
|
|
||||||
|
async def _daemon_stop() -> None:
|
||||||
|
if await daemon_manager.daemon_stop():
|
||||||
|
logger.info("Daemon stopped.")
|
||||||
|
else:
|
||||||
|
logger.error("Daemon failed to stop.")
|
||||||
|
|
||||||
|
|
||||||
|
async def _daemon_status() -> None:
|
||||||
|
if await daemon_manager.daemon_is_running():
|
||||||
|
logger.info("Daemon is running.")
|
||||||
|
else:
|
||||||
|
logger.info("Daemon is NOT running.")
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.daemon_command == "start" and args.detach:
|
||||||
|
await _daemon_start_detached()
|
||||||
|
elif args.daemon_command == "start":
|
||||||
|
await _daemon_start(args)
|
||||||
|
elif args.daemon_command == "stop":
|
||||||
|
await _daemon_stop()
|
||||||
|
elif args.daemon_command == "status":
|
||||||
|
await _daemon_status()
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -0,0 +1,39 @@
|
||||||
|
"""Handle requests to daemon."""
|
||||||
|
|
||||||
|
from dataclasses import asdict
|
||||||
|
|
||||||
|
from aiohttp import web
|
||||||
|
from aiohttp.web_runner import GracefulExit
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.config import config_manager
|
||||||
|
|
||||||
|
|
||||||
|
async def alive_peers(_: web.Request) -> web.Response:
|
||||||
|
"""Find alive peers."""
|
||||||
|
alives = HffsContext.get_peer_prober().get_alives()
|
||||||
|
return web.json_response([asdict(peer) for peer in alives])
|
||||||
|
|
||||||
|
|
||||||
|
async def peers_changed(_: web.Request) -> web.Response:
|
||||||
|
"""Update peers."""
|
||||||
|
config = config_manager.load_config()
|
||||||
|
new_peers = HffsContext.update_peers(config, HffsContext.get_peers())
|
||||||
|
HffsContext.get_peer_prober().update_peers(new_peers)
|
||||||
|
return web.Response()
|
||||||
|
|
||||||
|
|
||||||
|
async def stop_daemon(request: web.Request) -> None:
|
||||||
|
"""Stop the daemon."""
|
||||||
|
HffsContext.get_peer_prober().stop_probe()
|
||||||
|
|
||||||
|
resp = web.Response()
|
||||||
|
await resp.prepare(request)
|
||||||
|
await resp.write_eof()
|
||||||
|
|
||||||
|
raise GracefulExit
|
||||||
|
|
||||||
|
|
||||||
|
async def daemon_running(_: web.Request) -> web.Response:
|
||||||
|
"""Check if daemon is running."""
|
||||||
|
return web.Response()
|
||||||
|
|
@ -0,0 +1,160 @@
|
||||||
|
"""Handler model and file related requests."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import re
|
||||||
|
from typing import TYPE_CHECKING, Tuple
|
||||||
|
|
||||||
|
import aiofiles
|
||||||
|
from aiohttp import web
|
||||||
|
|
||||||
|
from hffs.common import hf_wrapper, repo_files
|
||||||
|
from hffs.common.etag import load_etag
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_file_info(request: web.Request) -> tuple[str, str, str]:
|
||||||
|
user = request.match_info["user"]
|
||||||
|
model = request.match_info["model"]
|
||||||
|
revision = request.match_info["revision"]
|
||||||
|
file_name = request.match_info["file_name"]
|
||||||
|
repo_id = f"{user}/{model}"
|
||||||
|
return repo_id, file_name, revision
|
||||||
|
|
||||||
|
|
||||||
|
async def download_model(_: web.Request) -> web.Response:
|
||||||
|
"""Download model."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
byte_range_re = re.compile(r"bytes=(\d+)-(\d+)?$")
|
||||||
|
|
||||||
|
|
||||||
|
def _get_byte_range(
|
||||||
|
request: web.Request,
|
||||||
|
) -> tuple[int | None, int | None] | None:
|
||||||
|
byte_range = request.headers.get("Range")
|
||||||
|
|
||||||
|
if not byte_range or byte_range.strip() == "":
|
||||||
|
return None, None
|
||||||
|
|
||||||
|
m = byte_range_re.match(byte_range)
|
||||||
|
err_msg = "Invalid byte range: Range=%s"
|
||||||
|
|
||||||
|
if not m:
|
||||||
|
logger.error(err_msg, byte_range)
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
first, last = [int(x) if x else None for x in m.groups()]
|
||||||
|
|
||||||
|
if first is not None and last is not None and last < first:
|
||||||
|
logger.error(err_msg, byte_range)
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
return first, last
|
||||||
|
|
||||||
|
|
||||||
|
async def _file_sender(
|
||||||
|
writer: web.StreamResponse,
|
||||||
|
file_path: Path,
|
||||||
|
file_start: int | None,
|
||||||
|
file_end: int | None,
|
||||||
|
) -> None:
|
||||||
|
async with aiofiles.open(file_path, "rb") as f:
|
||||||
|
if file_start is not None:
|
||||||
|
await f.seek(file_start)
|
||||||
|
|
||||||
|
buf_size = 2**18 # 256 KB buffer size
|
||||||
|
|
||||||
|
while True:
|
||||||
|
to_read = min(
|
||||||
|
buf_size,
|
||||||
|
file_end + 1 - await f.tell() if file_end else buf_size,
|
||||||
|
)
|
||||||
|
|
||||||
|
buf = await f.read(to_read)
|
||||||
|
|
||||||
|
if not buf:
|
||||||
|
break
|
||||||
|
|
||||||
|
await writer.write(buf)
|
||||||
|
|
||||||
|
await writer.write_eof()
|
||||||
|
|
||||||
|
|
||||||
|
async def download_file(
|
||||||
|
request: web.Request,
|
||||||
|
) -> web.StreamResponse:
|
||||||
|
"""Download file."""
|
||||||
|
br = _get_byte_range(request)
|
||||||
|
if br is None:
|
||||||
|
return web.Response(status=400)
|
||||||
|
|
||||||
|
file_start, file_end = br
|
||||||
|
repo_id, file_name, revision = _get_file_info(request)
|
||||||
|
|
||||||
|
file_info = hf_wrapper.get_file_info(repo_id, revision, file_name)
|
||||||
|
if not file_info:
|
||||||
|
return web.Response(status=404)
|
||||||
|
|
||||||
|
file_path = file_info.file_path
|
||||||
|
if not file_path.exists():
|
||||||
|
return web.Response(status=404)
|
||||||
|
|
||||||
|
headers = {"Content-disposition": f"attachment; filename={file_name}"}
|
||||||
|
response = web.StreamResponse(headers=headers)
|
||||||
|
await response.prepare(request)
|
||||||
|
await _file_sender(response, file_path, file_start, file_end)
|
||||||
|
return response
|
||||||
|
|
||||||
|
|
||||||
|
async def search_model(_: web.Request) -> web.Response:
|
||||||
|
"""Search model."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
async def search_file(
|
||||||
|
request: web.Request,
|
||||||
|
) -> web.Response:
|
||||||
|
"""Search file."""
|
||||||
|
repo_id, file_name, revision = _get_file_info(request)
|
||||||
|
|
||||||
|
rev_info = hf_wrapper.get_revision_info(repo_id, revision)
|
||||||
|
if not rev_info:
|
||||||
|
return web.Response(status=404)
|
||||||
|
|
||||||
|
file_info = hf_wrapper.get_file_info(repo_id, revision, file_name)
|
||||||
|
if not file_info:
|
||||||
|
return web.Response(status=404)
|
||||||
|
|
||||||
|
etag = load_etag(repo_id, file_name, revision)
|
||||||
|
return web.Response(
|
||||||
|
headers={
|
||||||
|
"ETag": etag or "",
|
||||||
|
hf_wrapper.COMMIT_HASH_HEADER: rev_info.commit_hash,
|
||||||
|
"Content-Length": str(file_info.size_on_disk),
|
||||||
|
"Location": str(request.url),
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_repo_info(request: web.Request) -> Tuple[str, str]:
|
||||||
|
user = request.match_info["user"]
|
||||||
|
model = request.match_info["model"]
|
||||||
|
revision = request.match_info["revision"]
|
||||||
|
repo_id = f"{user}/{model}"
|
||||||
|
return repo_id, revision
|
||||||
|
|
||||||
|
|
||||||
|
async def get_repo_file_list(request: web.Request) -> web.Response:
|
||||||
|
"""Get repo file list."""
|
||||||
|
repo_id, revision = _get_repo_info(request)
|
||||||
|
files = repo_files.load_file_list(repo_id, revision)
|
||||||
|
if not files:
|
||||||
|
return web.Response(status=404)
|
||||||
|
return web.json_response(files)
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
"""Handle requets related to peers."""
|
||||||
|
|
||||||
|
from aiohttp import web
|
||||||
|
|
||||||
|
|
||||||
|
async def pong(_: web.Request) -> web.Response:
|
||||||
|
"""Handle pings from peers."""
|
||||||
|
return web.Response()
|
||||||
|
|
@ -0,0 +1,85 @@
|
||||||
|
"""Manager of daemon service."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
import platform
|
||||||
|
import shutil
|
||||||
|
import signal
|
||||||
|
import subprocess
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import TYPE_CHECKING
|
||||||
|
|
||||||
|
from hffs.client import http_request
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
HFFS_EXEC_NAME_GLOBAL = "hffs"
|
||||||
|
HFFS_EXEC_NAME_LOCAL = "./main.py"
|
||||||
|
DELAY_SEC = 2
|
||||||
|
|
||||||
|
|
||||||
|
def _find_executable() -> str | None:
|
||||||
|
executable = shutil.which(HFFS_EXEC_NAME_GLOBAL)
|
||||||
|
if executable:
|
||||||
|
return executable
|
||||||
|
|
||||||
|
main_py = Path(HFFS_EXEC_NAME_LOCAL)
|
||||||
|
if main_py.exists() and main_py.is_file():
|
||||||
|
return "python " + HFFS_EXEC_NAME_LOCAL
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
async def daemon_is_running() -> bool:
|
||||||
|
"""Check if the HFFS Daemon is running."""
|
||||||
|
return await http_request.is_daemon_running()
|
||||||
|
|
||||||
|
|
||||||
|
async def daemon_start(args: Namespace) -> bool:
|
||||||
|
"""Start the HFFS Daemon in a detached background process."""
|
||||||
|
if await daemon_is_running():
|
||||||
|
return True
|
||||||
|
|
||||||
|
executable = _find_executable()
|
||||||
|
if not executable:
|
||||||
|
logger.error("Cannot find HFFS executable.")
|
||||||
|
return False
|
||||||
|
|
||||||
|
verbose = "--verbose" if args.verbose else ""
|
||||||
|
command = f"{executable} {verbose} daemon start --detach"
|
||||||
|
flags = (
|
||||||
|
subprocess.CREATE_NO_WINDOW # type: ignore[attr-defined]
|
||||||
|
if (platform.system() == "Windows")
|
||||||
|
else 0
|
||||||
|
)
|
||||||
|
|
||||||
|
if platform.system() == "Linux":
|
||||||
|
# deal with zombie processes on linux
|
||||||
|
signal.signal(signal.SIGCHLD, signal.SIG_IGN)
|
||||||
|
|
||||||
|
await asyncio.create_subprocess_shell(
|
||||||
|
command,
|
||||||
|
stdin=subprocess.DEVNULL,
|
||||||
|
stdout=subprocess.DEVNULL,
|
||||||
|
stderr=subprocess.DEVNULL,
|
||||||
|
creationflags=flags,
|
||||||
|
)
|
||||||
|
|
||||||
|
await asyncio.sleep(DELAY_SEC)
|
||||||
|
return await daemon_is_running()
|
||||||
|
|
||||||
|
|
||||||
|
async def daemon_stop() -> bool:
|
||||||
|
"""Stop the HFFS Daemon."""
|
||||||
|
if not await daemon_is_running():
|
||||||
|
return True
|
||||||
|
|
||||||
|
await http_request.stop_daemon()
|
||||||
|
|
||||||
|
await asyncio.sleep(DELAY_SEC)
|
||||||
|
return not await daemon_is_running()
|
||||||
|
|
@ -0,0 +1,116 @@
|
||||||
|
"""Probing the liveness of other peers."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import heapq
|
||||||
|
import logging
|
||||||
|
from typing import TYPE_CHECKING, List
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from hffs.common.peer import Peer
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
class PeerProber:
|
||||||
|
"""Prober for the liveness of other peers."""
|
||||||
|
|
||||||
|
_peers: List[Peer]
|
||||||
|
_actives: set
|
||||||
|
_updates: set | None
|
||||||
|
_probe_heap: List[tuple[int, Peer]]
|
||||||
|
_probing: bool
|
||||||
|
_probe_task: asyncio.Task[None] | None
|
||||||
|
|
||||||
|
INTERVAL_SEC = 3
|
||||||
|
|
||||||
|
def __init__(self, peers: List[Peer]) -> None:
|
||||||
|
"""Init PeerProber."""
|
||||||
|
self._peers = peers
|
||||||
|
self._actives = set()
|
||||||
|
self._updates = None
|
||||||
|
self._probe_heap = []
|
||||||
|
self._probing = False
|
||||||
|
self._probe_task = None
|
||||||
|
|
||||||
|
def get_alives(self) -> List[Peer]:
|
||||||
|
"""Get live peer list."""
|
||||||
|
return list(self._actives)
|
||||||
|
|
||||||
|
def update_peers(self, peers: List[Peer]) -> None:
|
||||||
|
"""Accept a new list of peers to probe."""
|
||||||
|
self._updates = set(peers)
|
||||||
|
|
||||||
|
def _reset_peer_heap(self) -> None:
|
||||||
|
self._probe_heap = []
|
||||||
|
for peer in self._peers:
|
||||||
|
heapq.heappush(self._probe_heap, (peer.epoch, peer))
|
||||||
|
|
||||||
|
def _do_update_peers(self) -> None:
|
||||||
|
if self._updates is not None:
|
||||||
|
peers_removed = set(self._peers) - self._updates
|
||||||
|
self._actives = self._actives - peers_removed
|
||||||
|
|
||||||
|
self._peers = list(self._updates)
|
||||||
|
self._updates = None
|
||||||
|
|
||||||
|
self._reset_peer_heap()
|
||||||
|
|
||||||
|
async def start_probe(self) -> None:
|
||||||
|
"""Start probing peers for liveness.
|
||||||
|
|
||||||
|
This function uses asyncio to probe peers for liveness.
|
||||||
|
It will wake up every {INTERVAL_SEC} seconds, pop a peer
|
||||||
|
from the heap, and then send a ping request to the peer.
|
||||||
|
The peer is taken out of the heap until we get a response from
|
||||||
|
the peer or the ping request times out.
|
||||||
|
After that, the peer is put back into the heap.
|
||||||
|
"""
|
||||||
|
# pylint: disable=import-outside-toplevel
|
||||||
|
from hffs.client.http_request import ping # resolve cyclic import
|
||||||
|
|
||||||
|
if self._probing:
|
||||||
|
return
|
||||||
|
|
||||||
|
self._probing = True
|
||||||
|
self._reset_peer_heap()
|
||||||
|
|
||||||
|
if not self._probe_heap:
|
||||||
|
logger.debug("No peers configured to probe")
|
||||||
|
|
||||||
|
def probe_cb(task: asyncio.Task[Peer]) -> None:
|
||||||
|
try:
|
||||||
|
peer = task.result()
|
||||||
|
|
||||||
|
if peer in self._peers:
|
||||||
|
heapq.heappush(self._probe_heap, (peer.epoch, peer))
|
||||||
|
|
||||||
|
if peer.alive and peer in self._peers:
|
||||||
|
self._actives.add(peer)
|
||||||
|
else:
|
||||||
|
self._actives.discard(peer)
|
||||||
|
except asyncio.exceptions.CancelledError:
|
||||||
|
logger.debug("probing is canceled")
|
||||||
|
|
||||||
|
while self._probing:
|
||||||
|
await asyncio.sleep(self.INTERVAL_SEC)
|
||||||
|
|
||||||
|
self._do_update_peers()
|
||||||
|
|
||||||
|
if self._probe_heap:
|
||||||
|
_, peer = heapq.heappop(self._probe_heap)
|
||||||
|
probe = asyncio.create_task(ping(peer))
|
||||||
|
probe.add_done_callback(probe_cb)
|
||||||
|
|
||||||
|
def set_probe_task(self, task: asyncio.Task[None]) -> None:
|
||||||
|
"""Save the coroutine task of probing to avoid gc."""
|
||||||
|
self._probe_task = task
|
||||||
|
|
||||||
|
def stop_probe(self) -> None:
|
||||||
|
"""Stop probing."""
|
||||||
|
# TODO: cancel running probe tasks # noqa: FIX002, TD002, TD003
|
||||||
|
self._probing = False
|
||||||
|
self._probe_heap = []
|
||||||
|
self._actives = set()
|
||||||
|
self._probe_task = None
|
||||||
|
|
@ -0,0 +1,84 @@
|
||||||
|
"""Daemon server."""
|
||||||
|
|
||||||
|
import asyncio
|
||||||
|
import logging
|
||||||
|
import sys
|
||||||
|
|
||||||
|
from aiohttp import web
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.api_settings import (
|
||||||
|
API_DAEMON_PEERS_ALIVE,
|
||||||
|
API_DAEMON_PEERS_CHANGE,
|
||||||
|
API_DAEMON_RUNNING,
|
||||||
|
API_DAEMON_STOP,
|
||||||
|
API_FETCH_FILE_DAEMON,
|
||||||
|
API_FETCH_REPO_FILE_LIST,
|
||||||
|
API_PEERS_PROBE,
|
||||||
|
)
|
||||||
|
from hffs.daemon.handlers.daemon_handler import (
|
||||||
|
alive_peers,
|
||||||
|
daemon_running,
|
||||||
|
peers_changed,
|
||||||
|
stop_daemon,
|
||||||
|
)
|
||||||
|
from hffs.daemon.handlers.fetch_handler import (
|
||||||
|
download_file,
|
||||||
|
get_repo_file_list,
|
||||||
|
search_file,
|
||||||
|
)
|
||||||
|
from hffs.daemon.handlers.peer_handler import pong
|
||||||
|
from hffs.daemon.prober import PeerProber
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def _setup_router(app: web.Application) -> None:
|
||||||
|
app.router.add_head(API_FETCH_FILE_DAEMON, search_file)
|
||||||
|
app.router.add_get(API_FETCH_FILE_DAEMON, download_file)
|
||||||
|
app.router.add_get(API_FETCH_REPO_FILE_LIST, get_repo_file_list)
|
||||||
|
|
||||||
|
app.router.add_get(API_PEERS_PROBE, pong)
|
||||||
|
|
||||||
|
app.router.add_get(API_DAEMON_PEERS_ALIVE, alive_peers)
|
||||||
|
app.router.add_get(API_DAEMON_STOP, stop_daemon)
|
||||||
|
app.router.add_get(API_DAEMON_RUNNING, daemon_running)
|
||||||
|
app.router.add_get(API_DAEMON_PEERS_CHANGE, peers_changed)
|
||||||
|
|
||||||
|
|
||||||
|
async def _start() -> None:
|
||||||
|
prober = PeerProber(HffsContext.get_peers())
|
||||||
|
HffsContext.set_peer_prober(prober)
|
||||||
|
task = asyncio.create_task(prober.start_probe()) # probe in background
|
||||||
|
prober.set_probe_task(task) # keep strong reference to task
|
||||||
|
|
||||||
|
app = web.Application()
|
||||||
|
_setup_router(app)
|
||||||
|
|
||||||
|
runner = web.AppRunner(app)
|
||||||
|
await runner.setup()
|
||||||
|
|
||||||
|
all_int_ip = "0.0.0.0" # noqa: S104
|
||||||
|
port = HffsContext.get_port()
|
||||||
|
site = web.TCPSite(runner=runner, host=all_int_ip, port=port)
|
||||||
|
await site.start()
|
||||||
|
|
||||||
|
await asyncio.sleep(sys.maxsize) # keep daemon running
|
||||||
|
|
||||||
|
|
||||||
|
PORT_OCCUPIED = 48
|
||||||
|
|
||||||
|
|
||||||
|
async def start() -> None:
|
||||||
|
"""Start the daemon server with errors surpressed."""
|
||||||
|
try:
|
||||||
|
await _start()
|
||||||
|
except OSError as e:
|
||||||
|
if e.errno == PORT_OCCUPIED:
|
||||||
|
port = HffsContext.get_port()
|
||||||
|
logger.info(
|
||||||
|
"Target port is already in use. ",
|
||||||
|
extra={"port": port},
|
||||||
|
)
|
||||||
|
except ValueError:
|
||||||
|
logger.exception("Daemon start error.")
|
||||||
|
|
@ -1,183 +1,55 @@
|
||||||
#!/usr/bin/python3
|
"""Entrypoint of HFFS."""
|
||||||
import argparse
|
|
||||||
import asyncio
|
|
||||||
import os
|
|
||||||
import logging.handlers
|
|
||||||
import logging
|
|
||||||
import sys
|
|
||||||
|
|
||||||
from .common.peer_store import PeerStore
|
import asyncio
|
||||||
from .client import http_client
|
import logging
|
||||||
from .client.model_manager import ModelManager
|
from argparse import Namespace
|
||||||
from .client.peer_manager import PeerManager
|
|
||||||
from .server import http_server
|
from hffs.client import model_cmd, peer_cmd, uninstall_cmd
|
||||||
from .common.settings import HFFS_LOG_DIR
|
from hffs.common.context import HffsContext
|
||||||
from .client.daemon_manager import daemon_start, daemon_stop
|
from hffs.config import conf_cmd, config_manager
|
||||||
from .client.uninstall_manager import uninstall_hffs
|
from hffs.daemon import daemon_cmd
|
||||||
|
from hffs.utils import auth_cmd, logging as logging_utils
|
||||||
|
from hffs.utils.args import arg_parser
|
||||||
|
|
||||||
logger = logging.getLogger(__name__)
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
async def peer_cmd(args):
|
async def _exec_cmd(args: Namespace) -> None:
|
||||||
with PeerStore() as store:
|
if args.command == "daemon":
|
||||||
peer_manager = PeerManager(store)
|
exec_cmd = daemon_cmd.exec_cmd
|
||||||
|
elif args.command == "peer":
|
||||||
if args.peer_command == "add":
|
exec_cmd = peer_cmd.exec_cmd
|
||||||
peer_manager.add_peer(args.IP, args.port)
|
elif args.command == "model":
|
||||||
elif args.peer_command == "rm":
|
exec_cmd = model_cmd.exec_cmd
|
||||||
peer_manager.remove_peer(args.IP, args.port)
|
elif args.command == "conf":
|
||||||
elif args.peer_command == "ls":
|
exec_cmd = conf_cmd.exec_cmd
|
||||||
await peer_manager.list_peers()
|
elif args.command == "auth":
|
||||||
else: # no matching subcmd
|
exec_cmd = auth_cmd.exec_cmd
|
||||||
raise ValueError("Invalid subcommand")
|
elif args.command == "uninstall":
|
||||||
|
exec_cmd = uninstall_cmd.exec_cmd
|
||||||
if args.peer_command in ("add", "rm"):
|
|
||||||
await peer_manager.notify_peer_change()
|
|
||||||
|
|
||||||
|
|
||||||
async def model_cmd(args):
|
|
||||||
model_manager = ModelManager()
|
|
||||||
model_manager.init()
|
|
||||||
|
|
||||||
if args.model_command == "search":
|
|
||||||
await model_manager.search_model(args.repo_id, args.file, args.revision)
|
|
||||||
elif args.model_command == "add":
|
|
||||||
await model_manager.add(args.repo_id, args.file, args.revision)
|
|
||||||
elif args.model_command == "ls":
|
|
||||||
model_manager.ls(args.repo_id)
|
|
||||||
elif args.model_command == "rm":
|
|
||||||
model_manager.rm(args.repo_id, revision=args.revision,
|
|
||||||
file_name=args.file)
|
|
||||||
else:
|
else:
|
||||||
raise ValueError("Invalid subcommand")
|
raise NotImplementedError
|
||||||
|
|
||||||
|
await exec_cmd(args)
|
||||||
|
|
||||||
|
|
||||||
async def daemon_cmd(args):
|
async def _async_main() -> None:
|
||||||
if args.daemon_command == "start":
|
config = config_manager.load_config()
|
||||||
if args.daemon == "true":
|
HffsContext.init_with_config(config)
|
||||||
await daemon_start(args)
|
|
||||||
else:
|
args = arg_parser()
|
||||||
await http_server.start_server(args.port)
|
logging_utils.setup_logging(args)
|
||||||
elif args.daemon_command == "stop":
|
|
||||||
await daemon_stop()
|
await _exec_cmd(args)
|
||||||
|
|
||||||
|
|
||||||
async def uninstall_cmd():
|
def main() -> None:
|
||||||
await uninstall_hffs()
|
"""Entrypoint of HFFS."""
|
||||||
|
|
||||||
|
|
||||||
async def exec_cmd(args, parser):
|
|
||||||
try:
|
try:
|
||||||
if args.command == "peer":
|
asyncio.run(_async_main())
|
||||||
await peer_cmd(args)
|
except (
|
||||||
elif args.command == "model":
|
KeyboardInterrupt,
|
||||||
await model_cmd(args)
|
asyncio.exceptions.CancelledError,
|
||||||
elif args.command == "daemon":
|
):
|
||||||
await daemon_cmd(args)
|
# ignore interrupt and cancel errors as they are handled by daemon
|
||||||
elif args.command == "uninstall":
|
logger.info("Shutting down HFFS.")
|
||||||
await uninstall_cmd()
|
|
||||||
else:
|
|
||||||
raise ValueError("Invalid command")
|
|
||||||
except ValueError as e:
|
|
||||||
print("{}".format(e))
|
|
||||||
parser.print_usage()
|
|
||||||
except Exception as e:
|
|
||||||
print(f"{e}")
|
|
||||||
|
|
||||||
|
|
||||||
def arg_parser():
|
|
||||||
parser = argparse.ArgumentParser(prog='hffs')
|
|
||||||
subparsers = parser.add_subparsers(dest='command')
|
|
||||||
|
|
||||||
# hffs daemon {start,stop} [--port port]
|
|
||||||
daemon_parser = subparsers.add_parser('daemon')
|
|
||||||
daemon_subparsers = daemon_parser.add_subparsers(dest='daemon_command')
|
|
||||||
daemon_start_parser = daemon_subparsers.add_parser('start')
|
|
||||||
daemon_start_parser.add_argument('--port', type=int, default=9009)
|
|
||||||
daemon_start_parser.add_argument("--daemon", type=str, default="true")
|
|
||||||
daemon_subparsers.add_parser('stop')
|
|
||||||
|
|
||||||
# hffs peer {add,rm,ls} IP [--port port]
|
|
||||||
peer_parser = subparsers.add_parser('peer')
|
|
||||||
peer_subparsers = peer_parser.add_subparsers(dest='peer_command')
|
|
||||||
peer_add_parser = peer_subparsers.add_parser('add')
|
|
||||||
peer_add_parser.add_argument('IP')
|
|
||||||
peer_add_parser.add_argument('--port', type=int, default=9009)
|
|
||||||
peer_rm_parser = peer_subparsers.add_parser('rm')
|
|
||||||
peer_rm_parser.add_argument('IP')
|
|
||||||
peer_rm_parser.add_argument('--port', type=int, default=9009)
|
|
||||||
peer_subparsers.add_parser('ls')
|
|
||||||
|
|
||||||
# hffs model {ls,add,rm,search} [--repo-id id] [--revision REVISION] [--file FILE]
|
|
||||||
model_parser = subparsers.add_parser('model')
|
|
||||||
model_subparsers = model_parser.add_subparsers(dest='model_command')
|
|
||||||
model_ls_parser = model_subparsers.add_parser('ls')
|
|
||||||
model_ls_parser.add_argument('--repo_id')
|
|
||||||
model_add_parser = model_subparsers.add_parser('add')
|
|
||||||
model_add_parser.add_argument('repo_id')
|
|
||||||
model_add_parser.add_argument('file')
|
|
||||||
model_add_parser.add_argument('--revision', type=str, default="main")
|
|
||||||
model_rm_parser = model_subparsers.add_parser('rm')
|
|
||||||
model_rm_parser.add_argument('repo_id')
|
|
||||||
model_rm_parser.add_argument('file')
|
|
||||||
model_rm_parser.add_argument('--revision', type=str, default="main")
|
|
||||||
model_search_parser = model_subparsers.add_parser('search')
|
|
||||||
model_search_parser.add_argument('repo_id')
|
|
||||||
model_search_parser.add_argument('file')
|
|
||||||
model_search_parser.add_argument('--revision', type=str, default="main")
|
|
||||||
|
|
||||||
# hffs uninstall
|
|
||||||
subparsers.add_parser('uninstall')
|
|
||||||
|
|
||||||
return parser.parse_args(), parser
|
|
||||||
|
|
||||||
|
|
||||||
def logging_level():
|
|
||||||
# Only use DEBUG or INFO level for logging
|
|
||||||
verbose = os.environ.get("HFFS_VERBOSE", None)
|
|
||||||
return logging.DEBUG if verbose else logging.INFO
|
|
||||||
|
|
||||||
|
|
||||||
def logging_handler(args):
|
|
||||||
# daemon's logs go to log files, others go to stdout
|
|
||||||
if args.command == "daemon" and args.daemon_command == "start":
|
|
||||||
os.makedirs(HFFS_LOG_DIR, exist_ok=True)
|
|
||||||
log_path = os.path.join(HFFS_LOG_DIR, "hffs.log")
|
|
||||||
handler = logging.handlers.RotatingFileHandler(log_path, maxBytes=2*1024*1024, backupCount=5)
|
|
||||||
log_format = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
|
||||||
handler.setFormatter(logging.Formatter(log_format))
|
|
||||||
else:
|
|
||||||
handler = logging.StreamHandler(stream=sys.stderr)
|
|
||||||
log_format = "%(message)s"
|
|
||||||
handler.setFormatter(logging.Formatter(log_format))
|
|
||||||
|
|
||||||
return handler
|
|
||||||
|
|
||||||
|
|
||||||
def setup_logging(args):
|
|
||||||
# configure root logger
|
|
||||||
handler = logging_handler(args)
|
|
||||||
|
|
||||||
level = logging_level()
|
|
||||||
handler.setLevel(level)
|
|
||||||
|
|
||||||
root_logger = logging.getLogger()
|
|
||||||
root_logger.addHandler(handler)
|
|
||||||
root_logger.setLevel(level)
|
|
||||||
|
|
||||||
# suppress lib's info log
|
|
||||||
logging.getLogger('asyncio').setLevel(logging.WARNING)
|
|
||||||
|
|
||||||
|
|
||||||
async def async_main():
|
|
||||||
args, parser = arg_parser()
|
|
||||||
setup_logging(args)
|
|
||||||
await exec_cmd(args, parser)
|
|
||||||
|
|
||||||
|
|
||||||
def main():
|
|
||||||
try:
|
|
||||||
asyncio.run(async_main())
|
|
||||||
except (KeyboardInterrupt, asyncio.exceptions.CancelledError):
|
|
||||||
# ignore error, async not run complete, error log may appear between async log
|
|
||||||
pass
|
|
||||||
|
|
|
||||||
|
|
@ -1,218 +0,0 @@
|
||||||
import asyncio
|
|
||||||
import json
|
|
||||||
import os
|
|
||||||
import logging
|
|
||||||
import re
|
|
||||||
|
|
||||||
from aiohttp import web
|
|
||||||
from aiohttp import streamer
|
|
||||||
from aiohttp.web_runner import GracefulExit
|
|
||||||
from contextvars import ContextVar
|
|
||||||
|
|
||||||
import huggingface_hub as hf
|
|
||||||
from .peer_prober import PeerProber
|
|
||||||
from ..common.peer_store import PeerStore
|
|
||||||
from ..common.hf_adapter import file_in_cache
|
|
||||||
from ..common.settings import save_local_service_port, HFFS_API_PING, HFFS_API_PEER_CHANGE, HFFS_API_ALIVE_PEERS
|
|
||||||
from ..common.settings import HFFS_API_STATUS, HFFS_API_STOP
|
|
||||||
|
|
||||||
ctx_var_peer_prober = ContextVar("PeerProber")
|
|
||||||
|
|
||||||
|
|
||||||
def extract_model_info(request):
|
|
||||||
user = request.match_info['user']
|
|
||||||
model = request.match_info['model']
|
|
||||||
revision = request.match_info['revision']
|
|
||||||
file_name = request.match_info['file_name']
|
|
||||||
repo_id = f"{user}/{model}"
|
|
||||||
return repo_id, file_name, revision
|
|
||||||
|
|
||||||
|
|
||||||
@streamer
|
|
||||||
async def file_sender(writer, file_path=None, file_range=()):
|
|
||||||
"""
|
|
||||||
This function will read large file chunk by chunk and send it through HTTP
|
|
||||||
without reading them into memory
|
|
||||||
"""
|
|
||||||
file_start, file_end = file_range
|
|
||||||
|
|
||||||
with open(file_path, 'rb') as f:
|
|
||||||
if file_start is not None:
|
|
||||||
f.seek(file_start)
|
|
||||||
|
|
||||||
buf_size = 2 ** 18
|
|
||||||
|
|
||||||
while True:
|
|
||||||
to_read = min(buf_size, file_end + 1 - f.tell()
|
|
||||||
if file_end else buf_size)
|
|
||||||
buf = f.read(to_read)
|
|
||||||
|
|
||||||
if not buf:
|
|
||||||
break
|
|
||||||
|
|
||||||
await writer.write(buf)
|
|
||||||
|
|
||||||
|
|
||||||
async def download_file(request):
|
|
||||||
|
|
||||||
def parse_byte_range(byte_range):
|
|
||||||
"""Returns the two numbers in 'bytes=123-456' or throws ValueError.
|
|
||||||
|
|
||||||
The last number or both numbers may be None.
|
|
||||||
"""
|
|
||||||
byte_range_re = re.compile(r'bytes=(\d+)-(\d+)?$')
|
|
||||||
|
|
||||||
if not byte_range or byte_range.strip() == '':
|
|
||||||
return None, None
|
|
||||||
|
|
||||||
m = byte_range_re.match(byte_range)
|
|
||||||
|
|
||||||
if not m:
|
|
||||||
raise ValueError('Invalid byte range %s' % byte_range)
|
|
||||||
|
|
||||||
first, last = [x and int(x) for x in m.groups()]
|
|
||||||
|
|
||||||
if last and last < first:
|
|
||||||
raise ValueError('Invalid byte range %s' % byte_range)
|
|
||||||
|
|
||||||
return first, last
|
|
||||||
|
|
||||||
try:
|
|
||||||
file_start, file_end = parse_byte_range(request.headers.get("Range"))
|
|
||||||
except Exception as e:
|
|
||||||
err_msg = "Invalid file range! ERROR: {}".format(e)
|
|
||||||
logging.warning(err_msg)
|
|
||||||
return web.Response(body=err_msg, status=400)
|
|
||||||
|
|
||||||
repo_id, file_name, revision = extract_model_info(request)
|
|
||||||
cached = file_in_cache(repo_id, file_name, revision)
|
|
||||||
|
|
||||||
if not cached:
|
|
||||||
logging.error("download 404 not cached")
|
|
||||||
return web.Response(
|
|
||||||
body=f'File <{file_name}> is not cached',
|
|
||||||
status=404)
|
|
||||||
|
|
||||||
headers = {"Content-disposition": f"attachment; filename={file_name}"}
|
|
||||||
|
|
||||||
file_path = cached["file_path"]
|
|
||||||
|
|
||||||
if not os.path.exists(file_path):
|
|
||||||
logging.error("download 404 not exist")
|
|
||||||
return web.Response(
|
|
||||||
body=f'File <{file_path}> does not exist',
|
|
||||||
status=404
|
|
||||||
)
|
|
||||||
|
|
||||||
logging.debug("download 200")
|
|
||||||
return web.Response(
|
|
||||||
body=file_sender(file_path=file_path,
|
|
||||||
file_range=(file_start, file_end)),
|
|
||||||
headers=headers
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
async def pong(_):
|
|
||||||
# logging.debug(f"[SERVER] seq={_.query['seq']}")
|
|
||||||
return web.Response(text='pong')
|
|
||||||
|
|
||||||
|
|
||||||
async def alive_peers(_):
|
|
||||||
peer_prober = ctx_var_peer_prober.get()
|
|
||||||
peers = peer_prober.get_actives()
|
|
||||||
return web.json_response([peer.to_dict() for peer in peers])
|
|
||||||
|
|
||||||
|
|
||||||
async def search_model(request):
|
|
||||||
repo_id, file_name, revision = extract_model_info(request)
|
|
||||||
cached = file_in_cache(repo_id, file_name, revision)
|
|
||||||
|
|
||||||
if not cached:
|
|
||||||
return web.Response(status=404)
|
|
||||||
else:
|
|
||||||
headers = {
|
|
||||||
hf.constants.HUGGINGFACE_HEADER_X_REPO_COMMIT: cached["commit_hash"],
|
|
||||||
"ETag": cached["etag"] if cached["etag"] else "",
|
|
||||||
"Content-Length": str(cached["size"]),
|
|
||||||
"Location": str(request.url),
|
|
||||||
}
|
|
||||||
logging.debug(f"search_model: {headers}")
|
|
||||||
return web.Response(status=200, headers=headers)
|
|
||||||
|
|
||||||
|
|
||||||
def get_peers():
|
|
||||||
peers = set()
|
|
||||||
with PeerStore() as peer_store:
|
|
||||||
peers = peer_store.get_peers()
|
|
||||||
return peers
|
|
||||||
|
|
||||||
|
|
||||||
async def on_peer_change(_):
|
|
||||||
peers = get_peers()
|
|
||||||
peer_prober: PeerProber = ctx_var_peer_prober.get()
|
|
||||||
peer_prober.update_peers(peers)
|
|
||||||
return web.Response(status=200)
|
|
||||||
|
|
||||||
|
|
||||||
async def get_service_status(_):
|
|
||||||
return web.json_response(data={})
|
|
||||||
|
|
||||||
|
|
||||||
async def post_stop_service(request):
|
|
||||||
resp = web.Response()
|
|
||||||
await resp.prepare(request)
|
|
||||||
await resp.write_eof()
|
|
||||||
logging.warning("Received exit request, exit server!")
|
|
||||||
raise GracefulExit()
|
|
||||||
|
|
||||||
|
|
||||||
async def start_server_safe(port):
|
|
||||||
# set up context before starting the server
|
|
||||||
peers = get_peers()
|
|
||||||
peer_prober = PeerProber(peers)
|
|
||||||
ctx_var_peer_prober.set(peer_prober)
|
|
||||||
|
|
||||||
# start peer prober to run in the background
|
|
||||||
asyncio.create_task(peer_prober.start_probe())
|
|
||||||
|
|
||||||
# start aiohttp server
|
|
||||||
app = web.Application()
|
|
||||||
|
|
||||||
# HEAD requests
|
|
||||||
app.router.add_head(
|
|
||||||
'/{user}/{model}/resolve/{revision}/{file_name:.*}', search_model)
|
|
||||||
|
|
||||||
# GET requests
|
|
||||||
app.router.add_get(HFFS_API_PING, pong)
|
|
||||||
app.router.add_get(HFFS_API_ALIVE_PEERS, alive_peers)
|
|
||||||
app.router.add_get(HFFS_API_PEER_CHANGE, on_peer_change)
|
|
||||||
app.router.add_get(
|
|
||||||
'/{user}/{model}/resolve/{revision}/{file_name:.*}', download_file)
|
|
||||||
|
|
||||||
app.router.add_get(HFFS_API_STATUS, get_service_status)
|
|
||||||
app.router.add_post(HFFS_API_STOP, post_stop_service)
|
|
||||||
|
|
||||||
# start web server
|
|
||||||
runner = web.AppRunner(app)
|
|
||||||
await runner.setup()
|
|
||||||
site = web.TCPSite(runner=runner, host='0.0.0.0', port=port)
|
|
||||||
await site.start()
|
|
||||||
|
|
||||||
save_local_service_port(port)
|
|
||||||
|
|
||||||
logging.info(f"HFFS daemon started at port {port}!")
|
|
||||||
|
|
||||||
# keep the server running
|
|
||||||
while True:
|
|
||||||
await asyncio.sleep(3600)
|
|
||||||
|
|
||||||
|
|
||||||
async def start_server(port):
|
|
||||||
try:
|
|
||||||
await start_server_safe(port)
|
|
||||||
except OSError as e:
|
|
||||||
if e.errno == 48:
|
|
||||||
print(f"Daemon is NOT started: port {port} is already in use")
|
|
||||||
except Exception as e:
|
|
||||||
logging.error("Failed to start HFFS daemon")
|
|
||||||
logging.error(e)
|
|
||||||
|
|
@ -1,80 +0,0 @@
|
||||||
|
|
||||||
import asyncio
|
|
||||||
import heapq
|
|
||||||
import logging
|
|
||||||
from ..common.peer import Peer
|
|
||||||
from ..client.http_client import ping
|
|
||||||
|
|
||||||
|
|
||||||
class PeerProber:
|
|
||||||
def __init__(self, peers):
|
|
||||||
self._peers = peers
|
|
||||||
self._actives = set()
|
|
||||||
self._updates = None
|
|
||||||
self._probe_heap = []
|
|
||||||
self._probing = False
|
|
||||||
|
|
||||||
def get_actives(self):
|
|
||||||
return list(self._actives)
|
|
||||||
|
|
||||||
def update_peers(self, peers):
|
|
||||||
self._updates = set(peers)
|
|
||||||
|
|
||||||
def _reset_peer_heap(self):
|
|
||||||
self._probe_heap = []
|
|
||||||
for peer in self._peers:
|
|
||||||
heapq.heappush(self._probe_heap, (peer.get_epoch(), peer))
|
|
||||||
|
|
||||||
def _do_update_peers(self):
|
|
||||||
if self._updates:
|
|
||||||
self._peers = self._updates
|
|
||||||
self._updates = None
|
|
||||||
self._reset_peer_heap()
|
|
||||||
|
|
||||||
async def start_probe(self):
|
|
||||||
"""Start probing peers for liveness.
|
|
||||||
|
|
||||||
This function uses asyncio to probe peers for liveness. It will wake up every 1 seconds, and
|
|
||||||
pop a peer from the heap. It will then send a ping request to the peer. The peer is taken out
|
|
||||||
of the haep until we get a response from the peer or the ping request times out. After that,
|
|
||||||
the peer is put back into the heap.
|
|
||||||
"""
|
|
||||||
if self._probing:
|
|
||||||
return
|
|
||||||
|
|
||||||
self._probing = True
|
|
||||||
|
|
||||||
# Initialize the heap with the peers, sorted by their epoch
|
|
||||||
self._reset_peer_heap()
|
|
||||||
|
|
||||||
if len(self._probe_heap) == 0:
|
|
||||||
logging.info("No peers configured to probe")
|
|
||||||
|
|
||||||
def probe_cb(task):
|
|
||||||
try:
|
|
||||||
peer = task.result()
|
|
||||||
if isinstance(peer, Peer):
|
|
||||||
heapq.heappush(self._probe_heap, (peer.get_epoch(), peer))
|
|
||||||
if peer.is_alive():
|
|
||||||
self._actives.add(peer)
|
|
||||||
else:
|
|
||||||
self._actives.discard(peer)
|
|
||||||
except asyncio.exceptions.CancelledError:
|
|
||||||
logging.debug("probing is canceled")
|
|
||||||
|
|
||||||
while self._probing:
|
|
||||||
await asyncio.sleep(3)
|
|
||||||
|
|
||||||
self._do_update_peers()
|
|
||||||
|
|
||||||
if len(self._probe_heap) == 0:
|
|
||||||
continue
|
|
||||||
|
|
||||||
_, peer = heapq.heappop(self._probe_heap)
|
|
||||||
probe = asyncio.create_task(ping(peer))
|
|
||||||
probe.add_done_callback(probe_cb)
|
|
||||||
|
|
||||||
async def stop_probe(self):
|
|
||||||
self._probing = False
|
|
||||||
self._probe_heap = []
|
|
||||||
self._actives = set()
|
|
||||||
|
|
@ -0,0 +1,132 @@
|
||||||
|
"""Utils for args parsing and usage."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import logging
|
||||||
|
from argparse import Namespace
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
|
||||||
|
|
||||||
|
def is_detached_daemon(args: Namespace) -> bool:
|
||||||
|
"""Check if HFFS is running as a detached daemon."""
|
||||||
|
return args.command == "daemon" and args.daemon_command == "start" and args.detach
|
||||||
|
|
||||||
|
|
||||||
|
def get_logging_level(args: Namespace) -> int:
|
||||||
|
"""Get logging level from args."""
|
||||||
|
if args.verbose:
|
||||||
|
return logging.DEBUG
|
||||||
|
return logging.INFO
|
||||||
|
|
||||||
|
|
||||||
|
# pylint: disable=too-many-locals,too-many-statements
|
||||||
|
def arg_parser() -> Namespace: # noqa: PLR0915
|
||||||
|
"""Parse args."""
|
||||||
|
df_port = HffsContext.get_port()
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser(prog="hffs")
|
||||||
|
parser.add_argument("-v", "--verbose", action="store_true")
|
||||||
|
subparsers = parser.add_subparsers(dest="command", required=True)
|
||||||
|
|
||||||
|
# hffs daemon ...
|
||||||
|
daemon_parser = subparsers.add_parser("daemon")
|
||||||
|
daemon_subparsers = daemon_parser.add_subparsers(
|
||||||
|
dest="daemon_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
# hffs daemon start ...
|
||||||
|
daemon_start_parser = daemon_subparsers.add_parser("start")
|
||||||
|
daemon_start_parser.add_argument("-d", "--detach", action="store_true")
|
||||||
|
# hffs daemon stop
|
||||||
|
daemon_subparsers.add_parser("stop")
|
||||||
|
# hffs daemon status
|
||||||
|
daemon_subparsers.add_parser("status")
|
||||||
|
|
||||||
|
# hffs peer ...
|
||||||
|
peer_parser = subparsers.add_parser("peer")
|
||||||
|
peer_subparsers = peer_parser.add_subparsers(
|
||||||
|
dest="peer_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
# hffs peer add ...
|
||||||
|
peer_add_parser = peer_subparsers.add_parser("add")
|
||||||
|
peer_add_parser.add_argument("ip")
|
||||||
|
peer_add_parser.add_argument("-p", "--port", type=int, default=df_port)
|
||||||
|
# hffs peer rm ...
|
||||||
|
peer_rm_parser = peer_subparsers.add_parser("rm")
|
||||||
|
peer_rm_parser.add_argument("ip")
|
||||||
|
peer_rm_parser.add_argument("-p", "--port", type=int, default=df_port)
|
||||||
|
# hffs peer ls ...
|
||||||
|
peer_subparsers.add_parser("ls")
|
||||||
|
|
||||||
|
# hffs model ...
|
||||||
|
model_parser = subparsers.add_parser("model")
|
||||||
|
model_subparsers = model_parser.add_subparsers(
|
||||||
|
dest="model_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
# hffs model ls ...
|
||||||
|
model_ls_parser = model_subparsers.add_parser("ls")
|
||||||
|
model_ls_parser.add_argument("-r", "--repo")
|
||||||
|
# hffs model add ...
|
||||||
|
model_add_parser = model_subparsers.add_parser("add")
|
||||||
|
model_add_parser.add_argument("-r", "--repo", required=True)
|
||||||
|
model_add_parser.add_argument("-f", "--file")
|
||||||
|
model_add_parser.add_argument("-v", "--revision", default="main")
|
||||||
|
# hffs model rm ...
|
||||||
|
model_rm_parser = model_subparsers.add_parser("rm")
|
||||||
|
model_rm_parser.add_argument("-r", "--repo", required=True)
|
||||||
|
model_rm_parser.add_argument("-f", "--file")
|
||||||
|
model_rm_parser.add_argument("-v", "--revision")
|
||||||
|
# hffs model search ...
|
||||||
|
model_search_parser = model_subparsers.add_parser("search")
|
||||||
|
model_search_parser.add_argument("-r", "--repo", required=True)
|
||||||
|
model_search_parser.add_argument("-f", "--file")
|
||||||
|
model_search_parser.add_argument("-v", "--revision", default="main")
|
||||||
|
|
||||||
|
# hffs conf ...
|
||||||
|
conf_parser = subparsers.add_parser("conf")
|
||||||
|
conf_subparsers = conf_parser.add_subparsers(
|
||||||
|
dest="conf_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
# hffs conf cache ...
|
||||||
|
conf_cache_parser = conf_subparsers.add_parser("cache")
|
||||||
|
conf_cache_subparsers = conf_cache_parser.add_subparsers(
|
||||||
|
dest="conf_cache_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
conf_cache_set_parser = conf_cache_subparsers.add_parser("set")
|
||||||
|
conf_cache_set_parser.add_argument("path")
|
||||||
|
conf_cache_subparsers.add_parser("get")
|
||||||
|
conf_cache_subparsers.add_parser("reset")
|
||||||
|
# hffs conf port ...
|
||||||
|
conf_port_parser = conf_subparsers.add_parser("port")
|
||||||
|
conf_port_subparsers = conf_port_parser.add_subparsers(
|
||||||
|
dest="conf_port_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
conf_port_set_subparser = conf_port_subparsers.add_parser("set")
|
||||||
|
conf_port_set_subparser.add_argument("port", type=int)
|
||||||
|
conf_port_subparsers.add_parser("get")
|
||||||
|
conf_port_subparsers.add_parser("reset")
|
||||||
|
# hffs conf show
|
||||||
|
conf_subparsers.add_parser("show")
|
||||||
|
|
||||||
|
# hffs auth ...
|
||||||
|
auth_parser = subparsers.add_parser("auth")
|
||||||
|
auth_subparsers = auth_parser.add_subparsers(
|
||||||
|
dest="auth_command",
|
||||||
|
required=True,
|
||||||
|
)
|
||||||
|
# hffs auth login
|
||||||
|
auth_subparsers.add_parser("login")
|
||||||
|
# hffs auth logout
|
||||||
|
auth_subparsers.add_parser("logout")
|
||||||
|
|
||||||
|
# hffs uninstall
|
||||||
|
subparsers.add_parser("uninstall")
|
||||||
|
|
||||||
|
return parser.parse_args()
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
"""Commands for authentication."""
|
||||||
|
|
||||||
|
from argparse import Namespace
|
||||||
|
from huggingface_hub import login, logout # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
|
||||||
|
async def exec_cmd(args: Namespace) -> None:
|
||||||
|
"""Execute command."""
|
||||||
|
if args.auth_command == "login":
|
||||||
|
login()
|
||||||
|
elif args.auth_command == "logout":
|
||||||
|
logout()
|
||||||
|
else:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
@ -0,0 +1,58 @@
|
||||||
|
"""Logging utils."""
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import logging
|
||||||
|
import logging.handlers
|
||||||
|
import sys
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.utils import args as arg_utils
|
||||||
|
|
||||||
|
|
||||||
|
def _create_stream_handler(level: int) -> logging.Handler:
|
||||||
|
"""Create a stream handler."""
|
||||||
|
handler = logging.StreamHandler(stream=sys.stderr)
|
||||||
|
handler.setFormatter(logging.Formatter("%(message)s"))
|
||||||
|
handler.setLevel(level)
|
||||||
|
return handler
|
||||||
|
|
||||||
|
|
||||||
|
def _create_file_handler(level: int) -> logging.Handler:
|
||||||
|
"""Create a file handler."""
|
||||||
|
log_dir = HffsContext.get_log_dir()
|
||||||
|
log_dir.mkdir(parents=True, exist_ok=True)
|
||||||
|
log_file = log_dir / "hffs.log"
|
||||||
|
|
||||||
|
handler = logging.handlers.RotatingFileHandler(
|
||||||
|
log_file,
|
||||||
|
maxBytes=10 * 1024 * 1024, # 10MB
|
||||||
|
backupCount=5,
|
||||||
|
)
|
||||||
|
|
||||||
|
log_format = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
|
||||||
|
handler.setFormatter(logging.Formatter(log_format))
|
||||||
|
handler.setLevel(level)
|
||||||
|
|
||||||
|
return handler
|
||||||
|
|
||||||
|
|
||||||
|
def setup_logging(args: argparse.Namespace) -> None:
|
||||||
|
"""Set up logging."""
|
||||||
|
# configure root logger
|
||||||
|
level = arg_utils.get_logging_level(args)
|
||||||
|
|
||||||
|
if arg_utils.is_detached_daemon(args):
|
||||||
|
handler = _create_file_handler(level)
|
||||||
|
else:
|
||||||
|
handler = _create_stream_handler(level)
|
||||||
|
|
||||||
|
root_logger = logging.getLogger()
|
||||||
|
root_logger.addHandler(handler)
|
||||||
|
root_logger.setLevel(level)
|
||||||
|
|
||||||
|
# suppress lib's info log
|
||||||
|
logging.getLogger("asyncio").setLevel(logging.WARNING)
|
||||||
|
logging.getLogger("aiohttp").setLevel(logging.WARNING)
|
||||||
|
logging.getLogger("urllib3").setLevel(logging.WARNING)
|
||||||
|
logging.getLogger("filelock").setLevel(logging.WARNING)
|
||||||
|
logging.getLogger("huggingface_hub").setLevel(logging.WARNING)
|
||||||
|
|
@ -0,0 +1,16 @@
|
||||||
|
"""Utils for yaml files."""
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import yaml
|
||||||
|
from pydantic import BaseModel
|
||||||
|
|
||||||
|
|
||||||
|
def yaml_load(file_path: Path) -> dict:
|
||||||
|
"""Load a yaml file."""
|
||||||
|
return yaml.safe_load(file_path.read_text())
|
||||||
|
|
||||||
|
|
||||||
|
def yaml_dump(model: BaseModel) -> str:
|
||||||
|
"""Dump a model to a yaml string."""
|
||||||
|
return yaml.dump(model.model_dump())
|
||||||
3
main.py
3
main.py
|
|
@ -1,5 +1,4 @@
|
||||||
#!/usr/bin/python3
|
"""HFFS main."""
|
||||||
#-*- encoding: UTF-8 -*-
|
|
||||||
|
|
||||||
from hffs.hffs import main
|
from hffs.hffs import main
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,81 @@
|
||||||
|
[build-system]
|
||||||
|
requires = ["hatchling>=1.8.0"]
|
||||||
|
build-backend = "hatchling.build"
|
||||||
|
|
||||||
|
[project]
|
||||||
|
name = "hffs"
|
||||||
|
version = "0.1.4"
|
||||||
|
description = "A tiny cache widget for accessing hugging face models easier and faster!"
|
||||||
|
requires-python = ">=3.8"
|
||||||
|
license = "Apache-2.0"
|
||||||
|
readme = "README.md"
|
||||||
|
authors = [{ name = "9#aisoft", email = "953175531@qq.com" }]
|
||||||
|
keywords = [
|
||||||
|
"huggingface",
|
||||||
|
"models",
|
||||||
|
"p2p",
|
||||||
|
"cache",
|
||||||
|
"9#aisoft",
|
||||||
|
]
|
||||||
|
classifiers = [
|
||||||
|
"Development Status :: 4 - Beta",
|
||||||
|
"Intended Audience :: Science/Research",
|
||||||
|
"License :: OSI Approved :: Apache Software License",
|
||||||
|
"Operating System :: OS Independent",
|
||||||
|
"Programming Language :: Python",
|
||||||
|
"Programming Language :: Python :: 3",
|
||||||
|
"Programming Language :: Python :: 3.8",
|
||||||
|
"Programming Language :: Python :: 3.9",
|
||||||
|
"Programming Language :: Python :: 3.10",
|
||||||
|
"Programming Language :: Python :: 3.11",
|
||||||
|
"Programming Language :: Python :: 3.12",
|
||||||
|
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||||
|
"Topic :: Utilities",
|
||||||
|
]
|
||||||
|
dependencies = [
|
||||||
|
"aiofiles",
|
||||||
|
"aiohttp",
|
||||||
|
"huggingface-hub == 0.23.0",
|
||||||
|
"prettytable",
|
||||||
|
"pydantic",
|
||||||
|
"requests",
|
||||||
|
"urllib3",
|
||||||
|
"psutil",
|
||||||
|
]
|
||||||
|
|
||||||
|
[project.urls]
|
||||||
|
"GitHub" = "https://github.com/madstorage-dev/hffs"
|
||||||
|
|
||||||
|
[project.scripts]
|
||||||
|
hffs = "hffs.hffs:main"
|
||||||
|
|
||||||
|
[tool.hatch.envs.default]
|
||||||
|
python = "3.8"
|
||||||
|
dependencies = [
|
||||||
|
"toml",
|
||||||
|
"ruff",
|
||||||
|
"mypy",
|
||||||
|
"pyupgrade",
|
||||||
|
"pylint",
|
||||||
|
]
|
||||||
|
|
||||||
|
[tool.hatch.envs.test]
|
||||||
|
extra-dependencies = [
|
||||||
|
"pytest",
|
||||||
|
"pytest-asyncio",
|
||||||
|
"types-PyYAML",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
[tool.hatch.envs.test.scripts]
|
||||||
|
unit = "pytest -s"
|
||||||
|
lint = "pylint -ry -j 0 {args:hffs}"
|
||||||
|
format = "ruff format {args:hffs}"
|
||||||
|
types = "mypy --install-types --non-interactive --cache-dir=.mypy_cache/ {args:hffs}"
|
||||||
|
|
||||||
|
[tool.ruff]
|
||||||
|
target-version = "py38"
|
||||||
|
ignore = [
|
||||||
|
"UP006",
|
||||||
|
"ANN401",
|
||||||
|
]
|
||||||
|
|
@ -1,23 +0,0 @@
|
||||||
aiohttp==3.9.5
|
|
||||||
aiosignal==1.3.1
|
|
||||||
attrs==23.2.0
|
|
||||||
certifi==2024.2.2
|
|
||||||
charset-normalizer==3.3.2
|
|
||||||
filelock==3.14.0
|
|
||||||
frozenlist==1.4.1
|
|
||||||
fsspec==2024.3.1
|
|
||||||
huggingface-hub==0.23.0
|
|
||||||
idna==3.7
|
|
||||||
ifaddr==0.2.0
|
|
||||||
multidict==6.0.5
|
|
||||||
packaging==24.0
|
|
||||||
prettytable==3.10.0
|
|
||||||
PyYAML==6.0.1
|
|
||||||
requests==2.31.0
|
|
||||||
tqdm==4.66.4
|
|
||||||
typing_extensions==4.11.0
|
|
||||||
urllib3==2.2.1
|
|
||||||
wcwidth==0.2.13
|
|
||||||
yarl==1.9.4
|
|
||||||
zeroconf==0.132.2
|
|
||||||
psutil==5.9.8
|
|
||||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 239 KiB After Width: | Height: | Size: 238 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 79 KiB After Width: | Height: | Size: 78 KiB |
46
setup.py
46
setup.py
|
|
@ -1,46 +0,0 @@
|
||||||
#!/usr/bin/python3
|
|
||||||
#-*- encoding: UTF-8 -*-
|
|
||||||
|
|
||||||
from setuptools import setup, find_packages
|
|
||||||
|
|
||||||
"""
|
|
||||||
打包的用的setup必须引入,
|
|
||||||
"""
|
|
||||||
|
|
||||||
VERSION = '0.1.1'
|
|
||||||
|
|
||||||
setup(name='hffs',
|
|
||||||
version=VERSION,
|
|
||||||
description="a tiny cli and server use p2p accelerate hugging face model download!",
|
|
||||||
long_description=open("README.md", "r").read(),
|
|
||||||
long_description_content_type="text/markdown",
|
|
||||||
classifiers=["Topic :: Software Development", "Development Status :: 3 - Alpha",
|
|
||||||
"Programming Language :: Python :: 3.11"],
|
|
||||||
# Get strings from http://pypi.python.org/pypi?%3Aaction=list_classifiers
|
|
||||||
keywords='hffs python hugging face download accelerate',
|
|
||||||
author='9#',
|
|
||||||
author_email='953175531@qq.com',
|
|
||||||
url='https://github.com/madstorage-dev/hffs',
|
|
||||||
license='',
|
|
||||||
packages=find_packages(),
|
|
||||||
include_package_data=True,
|
|
||||||
zip_safe=True,
|
|
||||||
install_requires=open('requirements.txt', 'r') .read().splitlines(),
|
|
||||||
python_requires=">=3.11",
|
|
||||||
entry_points={
|
|
||||||
'console_scripts': [
|
|
||||||
'hffs = hffs.hffs:main'
|
|
||||||
]
|
|
||||||
},
|
|
||||||
setup_requires=['setuptools', 'wheel']
|
|
||||||
)
|
|
||||||
|
|
||||||
# usage:
|
|
||||||
# requires:
|
|
||||||
# pip3 install twine
|
|
||||||
# clean:
|
|
||||||
# rm -rf build/ dist/ hffs.egg-info/
|
|
||||||
# build:
|
|
||||||
# python3 setup.py sdist bdist_wheel
|
|
||||||
# upload:
|
|
||||||
# twine upload dist/hffs*
|
|
||||||
|
|
@ -0,0 +1,88 @@
|
||||||
|
"""Test the config_manager module."""
|
||||||
|
|
||||||
|
from typing import cast
|
||||||
|
|
||||||
|
import hffs.config.config_manager as manager
|
||||||
|
from hffs.config.hffs_config import (
|
||||||
|
CONFIG_FILE,
|
||||||
|
DEFAULT_CACHE_DIR,
|
||||||
|
DEFAULT_DAEMON_PORT,
|
||||||
|
HffsConfig,
|
||||||
|
Peer,
|
||||||
|
)
|
||||||
|
from hffs.utils.yaml import yaml_load
|
||||||
|
|
||||||
|
|
||||||
|
def test_init() -> None:
|
||||||
|
"""Test default initialization."""
|
||||||
|
if CONFIG_FILE.exists():
|
||||||
|
CONFIG_FILE.unlink()
|
||||||
|
|
||||||
|
manager.init_config()
|
||||||
|
|
||||||
|
conf = cast(dict, yaml_load(CONFIG_FILE))
|
||||||
|
|
||||||
|
assert conf == {
|
||||||
|
"cache_dir": str(DEFAULT_CACHE_DIR),
|
||||||
|
"peers": [],
|
||||||
|
"daemon_port": DEFAULT_DAEMON_PORT,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def test_save_and_load() -> None:
|
||||||
|
"""Test saving and loading configuration."""
|
||||||
|
custom = {
|
||||||
|
"cache_dir": "custom_cache_dir",
|
||||||
|
"peers": [{"ip": "127.0.0.1", "port": 8080}],
|
||||||
|
"daemon_port": 8080,
|
||||||
|
}
|
||||||
|
|
||||||
|
peers = [Peer(ip=p["ip"], port=p["port"]) for p in custom["peers"]]
|
||||||
|
cache_dir = custom["cache_dir"]
|
||||||
|
daemon_port = custom["daemon_port"]
|
||||||
|
|
||||||
|
conf = HffsConfig(
|
||||||
|
cache_dir=cache_dir,
|
||||||
|
peers=peers,
|
||||||
|
daemon_port=daemon_port,
|
||||||
|
)
|
||||||
|
|
||||||
|
manager.save_config(conf)
|
||||||
|
saved = cast(dict, yaml_load(CONFIG_FILE))
|
||||||
|
assert saved == custom
|
||||||
|
|
||||||
|
loaded = manager.load_config()
|
||||||
|
assert loaded == conf
|
||||||
|
|
||||||
|
|
||||||
|
def test_change_config() -> None:
|
||||||
|
"""Test set, reset, and get configs."""
|
||||||
|
port_1 = 1234
|
||||||
|
port_2 = 4321
|
||||||
|
|
||||||
|
ip = "192.168.0.1"
|
||||||
|
cache_dir = "new_cache_dir"
|
||||||
|
|
||||||
|
manager.set_config(manager.ConfOpt.CACHE, cache_dir, str)
|
||||||
|
manager.set_config(manager.ConfOpt.PORT, port_1, int)
|
||||||
|
manager.set_config(
|
||||||
|
manager.ConfOpt.PEERS,
|
||||||
|
[Peer(ip=ip, port=4321)],
|
||||||
|
list,
|
||||||
|
)
|
||||||
|
|
||||||
|
assert manager.get_config(manager.ConfOpt.CACHE, str) == cache_dir
|
||||||
|
assert manager.get_config(manager.ConfOpt.PORT, int) == port_1
|
||||||
|
assert manager.get_config(manager.ConfOpt.PEERS, list) == [
|
||||||
|
Peer(ip=ip, port=port_2),
|
||||||
|
]
|
||||||
|
|
||||||
|
manager.reset_config(manager.ConfOpt.CACHE, str)
|
||||||
|
manager.reset_config(manager.ConfOpt.PORT, int)
|
||||||
|
manager.reset_config(manager.ConfOpt.PEERS, list)
|
||||||
|
|
||||||
|
assert manager.get_config(manager.ConfOpt.CACHE, str) == str(
|
||||||
|
DEFAULT_CACHE_DIR,
|
||||||
|
)
|
||||||
|
assert manager.get_config(manager.ConfOpt.PORT, int) == DEFAULT_DAEMON_PORT
|
||||||
|
assert manager.get_config(manager.ConfOpt.PEERS, list) == []
|
||||||
|
|
@ -0,0 +1,86 @@
|
||||||
|
"""Test HffsContext."""
|
||||||
|
|
||||||
|
from pytest import fixture
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.peer import Peer as ContextPeer
|
||||||
|
from hffs.config.hffs_config import HffsConfig, Peer
|
||||||
|
|
||||||
|
|
||||||
|
@fixture()
|
||||||
|
def test_config() -> HffsConfig:
|
||||||
|
"""Return a test HffsConfig."""
|
||||||
|
return HffsConfig(
|
||||||
|
cache_dir="test_cache_dir",
|
||||||
|
peers=[Peer(ip="127.0.0.1", port=8081)],
|
||||||
|
daemon_port=8088,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def test_port(test_config: HffsConfig) -> None:
|
||||||
|
"""Test get port."""
|
||||||
|
context = HffsContext.init_with_config(test_config)
|
||||||
|
assert context.port == test_config.daemon_port
|
||||||
|
|
||||||
|
|
||||||
|
def test_model_dir(test_config: HffsConfig) -> None:
|
||||||
|
"""Test get model dir."""
|
||||||
|
context = HffsContext.init_with_config(test_config)
|
||||||
|
assert str(context.model_dir) == "test_cache_dir/models"
|
||||||
|
|
||||||
|
|
||||||
|
def test_etag_dir(test_config: HffsConfig) -> None:
|
||||||
|
"""Test get etag dir."""
|
||||||
|
context = HffsContext.init_with_config(test_config)
|
||||||
|
assert str(context.etag_dir) == "test_cache_dir/etags"
|
||||||
|
|
||||||
|
|
||||||
|
def test_log_dir(test_config: HffsConfig) -> None:
|
||||||
|
"""Test log dir."""
|
||||||
|
context = HffsContext.init_with_config(test_config)
|
||||||
|
assert str(context.log_dir) == "test_cache_dir/logs"
|
||||||
|
|
||||||
|
|
||||||
|
def test_get_peers(test_config: HffsConfig) -> None:
|
||||||
|
"""Test get peers."""
|
||||||
|
context = HffsContext.init_with_config(test_config)
|
||||||
|
assert len(context.peers) == 1
|
||||||
|
|
||||||
|
act_peer = context.peers[0]
|
||||||
|
exp_peer = test_config.peers[0]
|
||||||
|
assert act_peer.ip == exp_peer.ip
|
||||||
|
assert act_peer.port == exp_peer.port
|
||||||
|
assert act_peer.alive is False
|
||||||
|
assert act_peer.epoch == 0
|
||||||
|
|
||||||
|
|
||||||
|
def test_update_peers() -> None:
|
||||||
|
"""Test update peers."""
|
||||||
|
num_peers = 2
|
||||||
|
ip_1, ip_2, ip_3 = "127.0.0.1", "127.0.0.2", "127.0.0.3"
|
||||||
|
port_1, port_2, port_3 = 8081, 8082, 8083
|
||||||
|
|
||||||
|
old_conf = HffsConfig(
|
||||||
|
peers=[
|
||||||
|
Peer(ip=ip_1, port=port_1),
|
||||||
|
Peer(ip=ip_2, port=port_2),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
old_context = HffsContext.init_with_config(old_conf)
|
||||||
|
assert len(old_context.peers) == num_peers
|
||||||
|
|
||||||
|
old_context.peers[0].alive = True
|
||||||
|
old_context.peers[0].epoch = 42
|
||||||
|
|
||||||
|
new_conf = HffsConfig(
|
||||||
|
peers=[
|
||||||
|
Peer(ip=ip_1, port=port_1),
|
||||||
|
Peer(ip=ip_3, port=port_3),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
|
||||||
|
new_peers = HffsContext.update_peers(new_conf, old_context.peers)
|
||||||
|
|
||||||
|
assert len(new_peers) == num_peers
|
||||||
|
assert ContextPeer(ip=ip_1, port=port_1, alive=True, epoch=42) in new_peers
|
||||||
|
assert ContextPeer(ip=ip_3, port=port_3, alive=False, epoch=0) in new_peers
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
"""Test cases for the daemon client."""
|
||||||
|
|
||||||
|
import pytest
|
||||||
|
|
||||||
|
from hffs.client.http_request import ping
|
||||||
|
from hffs.common.peer import Peer
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.asyncio()
|
||||||
|
async def test_peers_probe() -> None:
|
||||||
|
"""Test probe a live peer."""
|
||||||
|
peer = Peer("127.0.0.2", 8080)
|
||||||
|
await ping(peer)
|
||||||
|
|
@ -0,0 +1,45 @@
|
||||||
|
"""Test save and load etag."""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from typing import TYPE_CHECKING, Any, List
|
||||||
|
|
||||||
|
import huggingface_hub as hf
|
||||||
|
|
||||||
|
from hffs.common.context import HffsContext
|
||||||
|
from hffs.common.etag import load_etag, save_etag
|
||||||
|
from hffs.config.hffs_config import HffsConfig
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
import py
|
||||||
|
import pytest
|
||||||
|
|
||||||
|
ETAG = "1234"
|
||||||
|
REPO = "test_repo"
|
||||||
|
FILE = "test_file"
|
||||||
|
REV = "test_rev"
|
||||||
|
|
||||||
|
|
||||||
|
def test_save_and_load(
|
||||||
|
monkeypatch: pytest.MonkeyPatch,
|
||||||
|
tmpdir: py.path.local,
|
||||||
|
) -> None:
|
||||||
|
"""Test save etag."""
|
||||||
|
|
||||||
|
def mock_module_path(*_: List[Any], **__: dict[str, Any]) -> str:
|
||||||
|
return str(HffsContext.get_model_dir() / REPO / REV / FILE)
|
||||||
|
|
||||||
|
monkeypatch.setattr(
|
||||||
|
hf,
|
||||||
|
"try_to_load_from_cache",
|
||||||
|
mock_module_path,
|
||||||
|
)
|
||||||
|
|
||||||
|
conf = HffsConfig(cache_dir=str(tmpdir))
|
||||||
|
|
||||||
|
HffsContext.init_with_config(conf)
|
||||||
|
|
||||||
|
save_etag(ETAG, REPO, FILE, REV)
|
||||||
|
etag = load_etag(REPO, FILE, REV)
|
||||||
|
|
||||||
|
assert etag == ETAG
|
||||||
Loading…
Reference in New Issue