first commit
This commit is contained in:
parent
863dc72da6
commit
ed5b16ab15
|
|
@ -1,355 +1,27 @@
|
||||||
# ---> VisualStudio
|
.idea/
|
||||||
## Ignore Visual Studio temporary files, build results, and
|
|
||||||
## files generated by popular Visual Studio add-ons.
|
|
||||||
##
|
|
||||||
## Get latest from https://github.com/github/gitignore/blob/master/VisualStudio.gitignore
|
|
||||||
|
|
||||||
# User-specific files
|
.markdown/
|
||||||
*.rsuser
|
|
||||||
*.suo
|
|
||||||
*.user
|
|
||||||
*.userosscache
|
|
||||||
*.sln.docstates
|
|
||||||
|
|
||||||
# User-specific files (MonoDevelop/Xamarin Studio)
|
outputs/*.csv
|
||||||
*.userprefs
|
|
||||||
|
|
||||||
# Mono auto generated files
|
outputs/predict_plot/*.jpg
|
||||||
mono_crash.*
|
|
||||||
|
|
||||||
# Build results
|
outputs/predict_plot/*.png
|
||||||
[Dd]ebug/
|
|
||||||
[Dd]ebugPublic/
|
|
||||||
[Rr]elease/
|
|
||||||
[Rr]eleases/
|
|
||||||
x64/
|
|
||||||
x86/
|
|
||||||
[Aa][Rr][Mm]/
|
|
||||||
[Aa][Rr][Mm]64/
|
|
||||||
bld/
|
|
||||||
[Bb]in/
|
|
||||||
[Oo]bj/
|
|
||||||
[Ll]og/
|
|
||||||
[Ll]ogs/
|
|
||||||
|
|
||||||
# Visual Studio 2015/2017 cache/options directory
|
outputs/predict_plot/*.tif
|
||||||
.vs/
|
|
||||||
# Uncomment if you have tasks that create the project's static files in wwwroot
|
|
||||||
#wwwroot/
|
|
||||||
|
|
||||||
# Visual Studio 2017 auto generated files
|
lightning_logs/
|
||||||
Generated\ Files/
|
|
||||||
|
|
||||||
# MSTest test Results
|
src/__pycache__/
|
||||||
[Tt]est[Rr]esult*/
|
|
||||||
[Bb]uild[Ll]og.*
|
|
||||||
|
|
||||||
# NUnit
|
.history
|
||||||
*.VisualState.xml
|
|
||||||
TestResult.xml
|
|
||||||
nunit-*.xml
|
|
||||||
|
|
||||||
# Build Results of an ATL Project
|
src/data/__pycache__/
|
||||||
[Dd]ebugPS/
|
|
||||||
[Rr]eleasePS/
|
|
||||||
dlldata.c
|
|
||||||
|
|
||||||
# Benchmark Results
|
src/metric/__pycache__/
|
||||||
BenchmarkDotNet.Artifacts/
|
|
||||||
|
|
||||||
# .NET Core
|
src/models/__pycache__/
|
||||||
project.lock.json
|
|
||||||
project.fragment.lock.json
|
|
||||||
artifacts/
|
|
||||||
|
|
||||||
# StyleCop
|
src/models/backbone/__pycache__/
|
||||||
StyleCopReport.xml
|
|
||||||
|
|
||||||
# Files built by Visual Studio
|
|
||||||
*_i.c
|
|
||||||
*_p.c
|
|
||||||
*_h.h
|
|
||||||
*.ilk
|
|
||||||
*.meta
|
|
||||||
*.obj
|
|
||||||
*.iobj
|
|
||||||
*.pch
|
|
||||||
*.pdb
|
|
||||||
*.ipdb
|
|
||||||
*.pgc
|
|
||||||
*.pgd
|
|
||||||
*.rsp
|
|
||||||
*.sbr
|
|
||||||
*.tlb
|
|
||||||
*.tli
|
|
||||||
*.tlh
|
|
||||||
*.tmp
|
|
||||||
*.tmp_proj
|
|
||||||
*_wpftmp.csproj
|
|
||||||
*.log
|
|
||||||
*.vspscc
|
|
||||||
*.vssscc
|
|
||||||
.builds
|
|
||||||
*.pidb
|
|
||||||
*.svclog
|
|
||||||
*.scc
|
|
||||||
|
|
||||||
# Chutzpah Test files
|
|
||||||
_Chutzpah*
|
|
||||||
|
|
||||||
# Visual C++ cache files
|
|
||||||
ipch/
|
|
||||||
*.aps
|
|
||||||
*.ncb
|
|
||||||
*.opendb
|
|
||||||
*.opensdf
|
|
||||||
*.sdf
|
|
||||||
*.cachefile
|
|
||||||
*.VC.db
|
|
||||||
*.VC.VC.opendb
|
|
||||||
|
|
||||||
# Visual Studio profiler
|
|
||||||
*.psess
|
|
||||||
*.vsp
|
|
||||||
*.vspx
|
|
||||||
*.sap
|
|
||||||
|
|
||||||
# Visual Studio Trace Files
|
|
||||||
*.e2e
|
|
||||||
|
|
||||||
# TFS 2012 Local Workspace
|
|
||||||
$tf/
|
|
||||||
|
|
||||||
# Guidance Automation Toolkit
|
|
||||||
*.gpState
|
|
||||||
|
|
||||||
# ReSharper is a .NET coding add-in
|
|
||||||
_ReSharper*/
|
|
||||||
*.[Rr]e[Ss]harper
|
|
||||||
*.DotSettings.user
|
|
||||||
|
|
||||||
# TeamCity is a build add-in
|
|
||||||
_TeamCity*
|
|
||||||
|
|
||||||
# DotCover is a Code Coverage Tool
|
|
||||||
*.dotCover
|
|
||||||
|
|
||||||
# AxoCover is a Code Coverage Tool
|
|
||||||
.axoCover/*
|
|
||||||
!.axoCover/settings.json
|
|
||||||
|
|
||||||
# Coverlet is a free, cross platform Code Coverage Tool
|
|
||||||
coverage*[.json, .xml, .info]
|
|
||||||
|
|
||||||
# Visual Studio code coverage results
|
|
||||||
*.coverage
|
|
||||||
*.coveragexml
|
|
||||||
|
|
||||||
# NCrunch
|
|
||||||
_NCrunch_*
|
|
||||||
.*crunch*.local.xml
|
|
||||||
nCrunchTemp_*
|
|
||||||
|
|
||||||
# MightyMoose
|
|
||||||
*.mm.*
|
|
||||||
AutoTest.Net/
|
|
||||||
|
|
||||||
# Web workbench (sass)
|
|
||||||
.sass-cache/
|
|
||||||
|
|
||||||
# Installshield output folder
|
|
||||||
[Ee]xpress/
|
|
||||||
|
|
||||||
# DocProject is a documentation generator add-in
|
|
||||||
DocProject/buildhelp/
|
|
||||||
DocProject/Help/*.HxT
|
|
||||||
DocProject/Help/*.HxC
|
|
||||||
DocProject/Help/*.hhc
|
|
||||||
DocProject/Help/*.hhk
|
|
||||||
DocProject/Help/*.hhp
|
|
||||||
DocProject/Help/Html2
|
|
||||||
DocProject/Help/html
|
|
||||||
|
|
||||||
# Click-Once directory
|
|
||||||
publish/
|
|
||||||
|
|
||||||
# Publish Web Output
|
|
||||||
*.[Pp]ublish.xml
|
|
||||||
*.azurePubxml
|
|
||||||
# Note: Comment the next line if you want to checkin your web deploy settings,
|
|
||||||
# but database connection strings (with potential passwords) will be unencrypted
|
|
||||||
*.pubxml
|
|
||||||
*.publishproj
|
|
||||||
|
|
||||||
# Microsoft Azure Web App publish settings. Comment the next line if you want to
|
|
||||||
# checkin your Azure Web App publish settings, but sensitive information contained
|
|
||||||
# in these scripts will be unencrypted
|
|
||||||
PublishScripts/
|
|
||||||
|
|
||||||
# NuGet Packages
|
|
||||||
*.nupkg
|
|
||||||
# NuGet Symbol Packages
|
|
||||||
*.snupkg
|
|
||||||
# The packages folder can be ignored because of Package Restore
|
|
||||||
**/[Pp]ackages/*
|
|
||||||
# except build/, which is used as an MSBuild target.
|
|
||||||
!**/[Pp]ackages/build/
|
|
||||||
# Uncomment if necessary however generally it will be regenerated when needed
|
|
||||||
#!**/[Pp]ackages/repositories.config
|
|
||||||
# NuGet v3's project.json files produces more ignorable files
|
|
||||||
*.nuget.props
|
|
||||||
*.nuget.targets
|
|
||||||
|
|
||||||
# Microsoft Azure Build Output
|
|
||||||
csx/
|
|
||||||
*.build.csdef
|
|
||||||
|
|
||||||
# Microsoft Azure Emulator
|
|
||||||
ecf/
|
|
||||||
rcf/
|
|
||||||
|
|
||||||
# Windows Store app package directories and files
|
|
||||||
AppPackages/
|
|
||||||
BundleArtifacts/
|
|
||||||
Package.StoreAssociation.xml
|
|
||||||
_pkginfo.txt
|
|
||||||
*.appx
|
|
||||||
*.appxbundle
|
|
||||||
*.appxupload
|
|
||||||
|
|
||||||
# Visual Studio cache files
|
|
||||||
# files ending in .cache can be ignored
|
|
||||||
*.[Cc]ache
|
|
||||||
# but keep track of directories ending in .cache
|
|
||||||
!?*.[Cc]ache/
|
|
||||||
|
|
||||||
# Others
|
|
||||||
ClientBin/
|
|
||||||
~$*
|
|
||||||
*~
|
|
||||||
*.dbmdl
|
|
||||||
*.dbproj.schemaview
|
|
||||||
*.jfm
|
|
||||||
*.pfx
|
|
||||||
*.publishsettings
|
|
||||||
orleans.codegen.cs
|
|
||||||
|
|
||||||
# Including strong name files can present a security risk
|
|
||||||
# (https://github.com/github/gitignore/pull/2483#issue-259490424)
|
|
||||||
#*.snk
|
|
||||||
|
|
||||||
# Since there are multiple workflows, uncomment next line to ignore bower_components
|
|
||||||
# (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
|
|
||||||
#bower_components/
|
|
||||||
|
|
||||||
# RIA/Silverlight projects
|
|
||||||
Generated_Code/
|
|
||||||
|
|
||||||
# Backup & report files from converting an old project file
|
|
||||||
# to a newer Visual Studio version. Backup files are not needed,
|
|
||||||
# because we have git ;-)
|
|
||||||
_UpgradeReport_Files/
|
|
||||||
Backup*/
|
|
||||||
UpgradeLog*.XML
|
|
||||||
UpgradeLog*.htm
|
|
||||||
ServiceFabricBackup/
|
|
||||||
*.rptproj.bak
|
|
||||||
|
|
||||||
# SQL Server files
|
|
||||||
*.mdf
|
|
||||||
*.ldf
|
|
||||||
*.ndf
|
|
||||||
|
|
||||||
# Business Intelligence projects
|
|
||||||
*.rdl.data
|
|
||||||
*.bim.layout
|
|
||||||
*.bim_*.settings
|
|
||||||
*.rptproj.rsuser
|
|
||||||
*- [Bb]ackup.rdl
|
|
||||||
*- [Bb]ackup ([0-9]).rdl
|
|
||||||
*- [Bb]ackup ([0-9][0-9]).rdl
|
|
||||||
|
|
||||||
# Microsoft Fakes
|
|
||||||
FakesAssemblies/
|
|
||||||
|
|
||||||
# GhostDoc plugin setting file
|
|
||||||
*.GhostDoc.xml
|
|
||||||
|
|
||||||
# Node.js Tools for Visual Studio
|
|
||||||
.ntvs_analysis.dat
|
|
||||||
node_modules/
|
|
||||||
|
|
||||||
# Visual Studio 6 build log
|
|
||||||
*.plg
|
|
||||||
|
|
||||||
# Visual Studio 6 workspace options file
|
|
||||||
*.opt
|
|
||||||
|
|
||||||
# Visual Studio 6 auto-generated workspace file (contains which files were open etc.)
|
|
||||||
*.vbw
|
|
||||||
|
|
||||||
# Visual Studio LightSwitch build output
|
|
||||||
**/*.HTMLClient/GeneratedArtifacts
|
|
||||||
**/*.DesktopClient/GeneratedArtifacts
|
|
||||||
**/*.DesktopClient/ModelManifest.xml
|
|
||||||
**/*.Server/GeneratedArtifacts
|
|
||||||
**/*.Server/ModelManifest.xml
|
|
||||||
_Pvt_Extensions
|
|
||||||
|
|
||||||
# Paket dependency manager
|
|
||||||
.paket/paket.exe
|
|
||||||
paket-files/
|
|
||||||
|
|
||||||
# FAKE - F# Make
|
|
||||||
.fake/
|
|
||||||
|
|
||||||
# CodeRush personal settings
|
|
||||||
.cr/personal
|
|
||||||
|
|
||||||
# Python Tools for Visual Studio (PTVS)
|
|
||||||
__pycache__/
|
|
||||||
*.pyc
|
|
||||||
|
|
||||||
# Cake - Uncomment if you are using it
|
|
||||||
# tools/**
|
|
||||||
# !tools/packages.config
|
|
||||||
|
|
||||||
# Tabs Studio
|
|
||||||
*.tss
|
|
||||||
|
|
||||||
# Telerik's JustMock configuration file
|
|
||||||
*.jmconfig
|
|
||||||
|
|
||||||
# BizTalk build output
|
|
||||||
*.btp.cs
|
|
||||||
*.btm.cs
|
|
||||||
*.odx.cs
|
|
||||||
*.xsd.cs
|
|
||||||
|
|
||||||
# OpenCover UI analysis results
|
|
||||||
OpenCover/
|
|
||||||
|
|
||||||
# Azure Stream Analytics local run output
|
|
||||||
ASALocalRun/
|
|
||||||
|
|
||||||
# MSBuild Binary and Structured Log
|
|
||||||
*.binlog
|
|
||||||
|
|
||||||
# NVidia Nsight GPU debugger configuration file
|
|
||||||
*.nvuser
|
|
||||||
|
|
||||||
# MFractors (Xamarin productivity tool) working folder
|
|
||||||
.mfractor/
|
|
||||||
|
|
||||||
# Local History for Visual Studio
|
|
||||||
.localhistory/
|
|
||||||
|
|
||||||
# BeatPulse healthcheck temp database
|
|
||||||
healthchecksdb
|
|
||||||
|
|
||||||
# Backup folder for Package Reference Convert tool in Visual Studio 2017
|
|
||||||
MigrationBackup/
|
|
||||||
|
|
||||||
# Ionide (cross platform F# VS Code tools) working folder
|
|
||||||
.ionide/
|
|
||||||
|
|
||||||
|
src/utils/__pycache__/
|
||||||
|
|
@ -0,0 +1,21 @@
|
||||||
|
default:
|
||||||
|
tags:
|
||||||
|
- docker
|
||||||
|
image:
|
||||||
|
name: ufoym/deepo:all-jupyter
|
||||||
|
entrypoint: [""]
|
||||||
|
|
||||||
|
before_script:
|
||||||
|
- pip install -U .
|
||||||
|
- pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
|
||||||
|
- pip install -r requirements.txt
|
||||||
|
|
||||||
|
stages:
|
||||||
|
- test
|
||||||
|
|
||||||
|
pytest:
|
||||||
|
stage: test
|
||||||
|
script:
|
||||||
|
- pip install -U .[dev]
|
||||||
|
- pytest --cov=./
|
||||||
|
coverage: '/^TOTAL.*\s+(\d+\%)$/'
|
||||||
32
LICENSE
32
LICENSE
|
|
@ -1,17 +1,19 @@
|
||||||
<copyright notice> By obtaining, using, and/or copying this software and/or
|
Copyright (c) [2021] [The Supervised Layout Benchmark]
|
||||||
its associated documentation, you agree that you have read, understood, and
|
|
||||||
will comply with the following terms and conditions:
|
|
||||||
|
|
||||||
Permission to use, copy, modify, and distribute this software and its associated
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
documentation for any purpose and without fee is hereby granted, provided
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
that the above copyright notice appears in all copies, and that both that
|
in the Software without restriction, including without limitation the rights
|
||||||
copyright notice and this permission notice appear in supporting documentation,
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
and that the name of the copyright holder not be used in advertising or publicity
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
pertaining to distribution of the software without specific, written permission.
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
THE COPYRIGHT HOLDER DISCLAIM ALL WARRANTIES WITH REGARD TO THIS SOFTWARE,
|
The above copyright notice and this permission notice shall be included in all
|
||||||
INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT
|
copies or substantial portions of the Software.
|
||||||
SHALL THE COPYRIGHT HOLDER BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL
|
|
||||||
DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM THE LOSS OF USE, DATA OR
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION,
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
93
README.md
93
README.md
|
|
@ -1,20 +1,87 @@
|
||||||
#### 从命令行创建一个新的仓库
|
# supervised_layout_benchmark
|
||||||
|
|
||||||
```bash
|
## Introduction
|
||||||
touch README.md
|
|
||||||
git init
|
|
||||||
git add README.md
|
|
||||||
git commit -m "first commit"
|
|
||||||
git remote add origin https://git.osredm.com/p57201394/supervised_layout_benchmark.git
|
|
||||||
git push -u origin master
|
|
||||||
|
|
||||||
|
This project aims to establish a deep neural network (DNN) surrogate modeling benchmark for the temperature field prediction of heat source layout (HSL-TFP) task, providing a set of representative DNN surrogates as baselines as well as the original code files for easy start and comparison.
|
||||||
|
|
||||||
|
## Running Requirements
|
||||||
|
|
||||||
|
- ### Software
|
||||||
|
|
||||||
|
- python:
|
||||||
|
- cuda:
|
||||||
|
- pytorch:
|
||||||
|
|
||||||
|
- ### Hardware
|
||||||
|
|
||||||
|
- A single GPU with at least 4GB.
|
||||||
|
|
||||||
|
|
||||||
|
## Environment construction
|
||||||
|
|
||||||
|
- ``` pip install -r requirements.txt ```
|
||||||
|
|
||||||
|
## A quick start
|
||||||
|
|
||||||
|
The training, test and visualization can be accessed by running `main.py` file.
|
||||||
|
|
||||||
|
- The data is available at the server address: `\\192.168.2.1\mnt/share1/layout_data/v1.0/data/`(refer to [Readme for samples](https://git.idrl.site/gongzhiqiang/supervised_layout_benchmark/blob/master/samples/README.md)). Remember to modify variable `data_root` in the configuration file `config/config_complex_net.yml` to the right server address.
|
||||||
|
|
||||||
|
- Training
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m train
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 从命令行推送已经创建的仓库
|
or
|
||||||
|
|
||||||
```bash
|
|
||||||
git remote add origin https://git.osredm.com/p57201394/supervised_layout_benchmark.git
|
|
||||||
git push -u origin master
|
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py --mode=train
|
||||||
```
|
```
|
||||||
|
|
||||||
|
- Test
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m test --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py --mode=test --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
where variable `test_check_num` is the number of the saved model for test.
|
||||||
|
|
||||||
|
- Prediction visualization
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m plot --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
```python
|
||||||
|
python main.py --mode=plot --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
where variable `test_check_num` is the number of the saved model for plotting.
|
||||||
|
|
||||||
|
## Project architecture
|
||||||
|
|
||||||
|
- `config`: the configuration file
|
||||||
|
- `notebook`: the test file for `notebook`
|
||||||
|
- `outputs`: the output results by `test` and `plot` module. The test results is saved at `outputs/*.csv` and the plotting figures is saved at `outputs/predict_plot/`.
|
||||||
|
- `src`: including surrogate model, training and testing files.
|
||||||
|
- `test.py`: testing files.
|
||||||
|
- `train.py`: training files.
|
||||||
|
- `plot.py`: prediction visualization files.
|
||||||
|
- `data`: data preprocessing and data loading files.
|
||||||
|
- `metric`: evaluation metric file. (For details, see [Readme for metric](https://git.idrl.site/gongzhiqiang/supervised_layout_benchmark/blob/master/src/metric/README.md))
|
||||||
|
- `models`: DNN surrogate models for the HSL-TFP task.
|
||||||
|
- `utils`: useful tool function files.
|
||||||
|
|
||||||
|
## One tiny example
|
||||||
|
|
||||||
|
One tiny example for training and testing can be accessed based on the following instruction.
|
||||||
|
* Some training and testing data are available at `samples/data`.
|
||||||
|
* Based on the original configuration file, run `python main.py` directly for a quick experience of this tiny example.
|
||||||
|
|
@ -0,0 +1,71 @@
|
||||||
|
# supervised_layout_benchmark
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
> 该项目主要用于实现卫星组件热布局不同深度代理模型训练、测试以及热布局预测作图.
|
||||||
|
|
||||||
|
## 环境要求
|
||||||
|
|
||||||
|
- ### 软件要求
|
||||||
|
|
||||||
|
- python:
|
||||||
|
- cuda:
|
||||||
|
- pytorch:
|
||||||
|
|
||||||
|
- ### 硬件要求
|
||||||
|
|
||||||
|
- 大约4GB显存的GPU
|
||||||
|
|
||||||
|
|
||||||
|
## 构建环境
|
||||||
|
|
||||||
|
- ``` pip install -r requirements.txt ```
|
||||||
|
|
||||||
|
## 快速开始
|
||||||
|
|
||||||
|
> 运行训练、测试以及热布局作图统一通过main.py入口.
|
||||||
|
|
||||||
|
- 数据放在服务器`\\192.168.2.1\mnt/share1/layout_data/v1.0/data/`(详见[Readme](https://git.idrl.site/gongzhiqiang/supervised_layout_benchmark/blob/master/samples/README.md)),运行时请修改程序配置文件`config/config_complex_net.yml`中`data_root`输入变量为挂载服务器上数据地址.
|
||||||
|
|
||||||
|
- 训练和测试
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m train 或者 python main.py --mode=train
|
||||||
|
```
|
||||||
|
|
||||||
|
- 测试
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m test --test_check_num=21 或者 python main.py --mode=test --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
其中`test_check_num`是测试输入模型存储的编号.
|
||||||
|
|
||||||
|
- 热布局预测作图
|
||||||
|
|
||||||
|
```python
|
||||||
|
python main.py -m plot --test_check_num=21 或者 python main.py --mode=plot --test_check_num=21
|
||||||
|
```
|
||||||
|
|
||||||
|
其中`test_check_num`是作图输入模型存储的编号.
|
||||||
|
|
||||||
|
## 项目结构
|
||||||
|
|
||||||
|
- `benchmark`目录存放运行所需所有程序
|
||||||
|
- `config`存放运行配置文件
|
||||||
|
- `notebook`存放`notebook`测试文件
|
||||||
|
- `outputs`用于存放`test`和`plot`作图输出结果,测试的输出结果保存在`outputs/*.csv`,`plot`结果保存在`outputs/predict_plot/`
|
||||||
|
- `src`用于存放模型文件和测试训练文件
|
||||||
|
- `test.py`测试程序
|
||||||
|
- `train.py`训练程序
|
||||||
|
- `plot.py`预测可视化程序
|
||||||
|
- `data`文件夹存放数据预处理和读取程序
|
||||||
|
- `metrics`文件夹存放热布局度量函数,详见[Readme](https://git.idrl.site/gongzhiqiang/supervised_layout_benchmark/blob/master/src/metric/README.md)
|
||||||
|
- `models`热布局深度代理模型所用深度模型
|
||||||
|
- `utils`工具类文件
|
||||||
|
|
||||||
|
## 其他
|
||||||
|
|
||||||
|
* 训练测试examples
|
||||||
|
* 训练样本测试样本存放于`samples/data`中
|
||||||
|
* 原始文件配置环境后,直接运行`python main.py`,即运行example
|
||||||
|
|
@ -0,0 +1,46 @@
|
||||||
|
# config
|
||||||
|
|
||||||
|
# model
|
||||||
|
## support SegNet_AlexNet, SegNet_VGG, SegNet_ResNet18, SegNet_ResNet34, SegNet_ResNet50, SegNet_ResNet101, SegNet_ResNet152
|
||||||
|
## FPN_ResNet18, FPN_ResNet50, FPN_ResNet101, FPN_ResNet34, FPN_ResNet152
|
||||||
|
## FCN_AlexNet, FCN_VGG, FCN_ResNet18, FCN_ResNet50, FCN_ResNet101, FCN_ResNet34, FCN_ResNet152
|
||||||
|
## UNet_VGG
|
||||||
|
model_name: FCN # choose from FPN, FCN, SegNet, UNet
|
||||||
|
backbone: AlexNet # choose from AlexNet, VGG, ResNet18, ResNet50, ResNet101
|
||||||
|
|
||||||
|
# dataset path
|
||||||
|
data_root: samples/data/
|
||||||
|
boundary: one_point # choose from rm_wall, one_point, all_walls
|
||||||
|
|
||||||
|
# train/val set
|
||||||
|
train_list: train/train_val.txt
|
||||||
|
|
||||||
|
# test set
|
||||||
|
## choose the test set: test_0.txt, test_1.txt, test_2.txt, test_3.txt,test_4.txt,test_5.txt,test_6.txt
|
||||||
|
test_list: test/test_0.txt
|
||||||
|
|
||||||
|
# metric for testing
|
||||||
|
## choose from "mae_global", "mae_boundary", "mae_component",
|
||||||
|
## "value_and_pos_error_of_maximum_temperature", "max_tem_spearmanr", "global_image_spearmanr"
|
||||||
|
metric: mae_boundary
|
||||||
|
|
||||||
|
# dataset format: mat or h5
|
||||||
|
data_format: mat
|
||||||
|
batch_size: 2
|
||||||
|
max_epochs: 50
|
||||||
|
lr: 0.001
|
||||||
|
|
||||||
|
# number of gpus to use
|
||||||
|
gpus: 1
|
||||||
|
val_check_interval: 1.0
|
||||||
|
|
||||||
|
# num_workers in dataloader
|
||||||
|
num_workers: 4
|
||||||
|
|
||||||
|
# preprocessing of data
|
||||||
|
## input
|
||||||
|
mean_layout: 0
|
||||||
|
std_layout: 1000
|
||||||
|
## output
|
||||||
|
mean_heat: 298
|
||||||
|
std_heat: 50
|
||||||
|
|
@ -0,0 +1,46 @@
|
||||||
|
# data config for computation of metrics
|
||||||
|
|
||||||
|
## SIZE OF COMPONENTS
|
||||||
|
units:
|
||||||
|
- - 0.016
|
||||||
|
- 0.012
|
||||||
|
- - 0.012
|
||||||
|
- 0.006
|
||||||
|
- - 0.018
|
||||||
|
- 0.009
|
||||||
|
- - 0.018
|
||||||
|
- 0.012
|
||||||
|
- - 0.018
|
||||||
|
- 0.018
|
||||||
|
- - 0.012
|
||||||
|
- 0.012
|
||||||
|
- - 0.018
|
||||||
|
- 0.006
|
||||||
|
- - 0.009
|
||||||
|
- 0.009
|
||||||
|
- - 0.006
|
||||||
|
- 0.024
|
||||||
|
- - 0.006
|
||||||
|
- 0.012
|
||||||
|
- - 0.012
|
||||||
|
- 0.024
|
||||||
|
- - 0.024
|
||||||
|
- 0.024
|
||||||
|
|
||||||
|
## POWERS OF THE COMPONENTS
|
||||||
|
powers:
|
||||||
|
- 4000
|
||||||
|
- 16000
|
||||||
|
- 6000
|
||||||
|
- 8000
|
||||||
|
- 10000
|
||||||
|
- 14000
|
||||||
|
- 16000
|
||||||
|
- 20000
|
||||||
|
- 8000
|
||||||
|
- 16000
|
||||||
|
- 10000
|
||||||
|
- 20000
|
||||||
|
|
||||||
|
## LENGTH OF LAYOUT BOARD
|
||||||
|
length: 0.1
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
FROM ufoym/deepo:pytorch
|
||||||
|
LABEL maintainer="gongzhiqiang@alumni.sjtu.edu.cn"
|
||||||
|
|
||||||
|
WORKDIR /tmp
|
||||||
|
COPY requirements.txt ./
|
||||||
|
RUN pip install -r requirements.txt
|
||||||
|
|
@ -0,0 +1,65 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
"""
|
||||||
|
This function denotes the main function to train/test/plot
|
||||||
|
Usage:
|
||||||
|
python main.py [FLAGS]
|
||||||
|
|
||||||
|
@author: gongzhiqiang
|
||||||
|
@contact: gongzhiqiang@alumni.sjtu.edu.cn
|
||||||
|
|
||||||
|
@version: 1.0
|
||||||
|
@file: main.py
|
||||||
|
@time: 2020-12-22
|
||||||
|
|
||||||
|
"""
|
||||||
|
from pathlib import Path
|
||||||
|
import configargparse
|
||||||
|
|
||||||
|
from src.LayoutDeepRegression import Model
|
||||||
|
from src import train, test, plot
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
# default configuration file
|
||||||
|
config_path = Path(__file__).absolute().parent / "config/config.yml"
|
||||||
|
parser = configargparse.ArgParser(default_config_files=[str(config_path)], description="Hyper-parameters.")
|
||||||
|
|
||||||
|
# configuration file
|
||||||
|
parser.add_argument("--config", is_config_file=True, default=False, help="config file path")
|
||||||
|
|
||||||
|
# mode
|
||||||
|
parser.add_argument("-m", "--mode", type=str, default="train", help="model: train or test or plot")
|
||||||
|
|
||||||
|
# args for training
|
||||||
|
parser.add_argument("--gpus", type=int, default=0, help="how many gpus")
|
||||||
|
parser.add_argument("--batch_size", default=16, type=int)
|
||||||
|
parser.add_argument("--max_epochs", default=20, type=int)
|
||||||
|
parser.add_argument("--lr", default="0.01", type=float)
|
||||||
|
parser.add_argument("--resume_from_checkpoint", type=str, help="resume from checkpoint")
|
||||||
|
parser.add_argument("--num_workers", default=2, type=int, help="num_workers in DataLoader")
|
||||||
|
parser.add_argument("--seed", type=int, default=1, help="seed")
|
||||||
|
parser.add_argument("--use_16bit", type=bool, default=False, help="use 16bit precision")
|
||||||
|
parser.add_argument("--profiler", action="store_true", help="use profiler")
|
||||||
|
|
||||||
|
# args for validation
|
||||||
|
parser.add_argument("--val_check_interval", type=float, default=1,
|
||||||
|
help="how often within one training epoch to check the validation set")
|
||||||
|
|
||||||
|
# args for testing
|
||||||
|
parser.add_argument("--test_check_num", default='0', type=str, help="checkpoint for test")
|
||||||
|
parser.add_argument("--test_args", action="store_true", help="print args")
|
||||||
|
|
||||||
|
# args from Model
|
||||||
|
parser = Model.add_model_specific_args(parser)
|
||||||
|
hparams = parser.parse_args()
|
||||||
|
|
||||||
|
# running
|
||||||
|
assert hparams.mode in ["train", "test", "plot"]
|
||||||
|
if hparams.test_args:
|
||||||
|
print(hparams)
|
||||||
|
else:
|
||||||
|
getattr(eval(hparams.mode), "main")(hparams)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
tqdm==4.42.1
|
||||||
|
scipy==1.4.1
|
||||||
|
pytest==5.3.5
|
||||||
|
numpy==1.18.1
|
||||||
|
matplotlib==3.1.3
|
||||||
|
ConfigArgParse==1.2.3
|
||||||
|
pytorch_lightning==1.1.2
|
||||||
|
PyYAML==5.3.1
|
||||||
|
scikit_learn==0.23.2
|
||||||
|
torch>=1.5.0
|
||||||
|
torchvision==0.8.1
|
||||||
|
|
@ -0,0 +1,131 @@
|
||||||
|
# Datasets for benchmark
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
> 该数据库用于支持热布局温度场预测任务,数据地址:/192.168.2.1/mnt/share1/layout_data/v1.0/data/
|
||||||
|
>
|
||||||
|
> samples中提供数据库的样例
|
||||||
|
|
||||||
|
## 数据库结构
|
||||||
|
|
||||||
|
> 数据库提供三种不同边界:小孔散热、单边散热和四周全散热
|
||||||
|
|
||||||
|
- `data`中存放不同边界数据库
|
||||||
|
- `one_point`小孔散热边界
|
||||||
|
- `train`存放训练数据
|
||||||
|
- `train`训练样本存放文件夹
|
||||||
|
- `train_val.txt`用于网络训练的数据list
|
||||||
|
- `test`存放测试数据
|
||||||
|
- `test`测试样本存放文件夹
|
||||||
|
- `test_*.txt`用于测试的数据list,其中`test_0.txt`、`test_1.txt`、`test_2.txt`、`test_3.txt`、`test_4.txt`、`test_5.txt`、`test_6.txt`分别存放了不同方式采样得到的测试样本
|
||||||
|
- `rm_wall`单边散热边界
|
||||||
|
- `train`
|
||||||
|
- `train`
|
||||||
|
- `train_val.txt`
|
||||||
|
- `test`
|
||||||
|
- `test`
|
||||||
|
- `test_*.txt`
|
||||||
|
- `all_walls`四周全散热边界
|
||||||
|
- `train`
|
||||||
|
- `train`
|
||||||
|
- `train_val.txt`
|
||||||
|
- `test`
|
||||||
|
- `test`
|
||||||
|
- `test_*.txt`
|
||||||
|
|
||||||
|
## 组件介绍
|
||||||
|
|
||||||
|
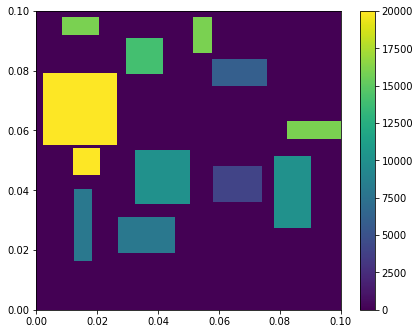
> 布局区域是`0.1m*0.1m`方形区域,共有12个大小功率不同组件
|
||||||
|
|
||||||
|
* 组件大小、功率
|
||||||
|
|
||||||
|
| 组件 | 长(m) | 宽(m) | 功率($W/m^2$) |
|
||||||
|
| :--: | :---: | :---: | :-----------: |
|
||||||
|
| 1 | 0.016 | 0.012 | 4000 |
|
||||||
|
| 2 | 0.012 | 0.006 | 16000 |
|
||||||
|
| 3 | 0.018 | 0.009 | 6000 |
|
||||||
|
| 4 | 0.018 | 0.012 | 8000 |
|
||||||
|
| 5 | 0.018 | 0.018 | 10000 |
|
||||||
|
| 6 | 0.012 | 0.012 | 14000 |
|
||||||
|
| 7 | 0.018 | 0.006 | 16000 |
|
||||||
|
| 8 | 0.009 | 0.009 | 20000 |
|
||||||
|
| 9 | 0.006 | 0.024 | 8000 |
|
||||||
|
| 10 | 0.006 | 0.012 | 16000 |
|
||||||
|
| 11 | 0.012 | 0.024 | 10000 |
|
||||||
|
| 12 | 0.024 | 0.024 | 20000 |
|
||||||
|
|
||||||
|
* 组件布局示例
|
||||||
|
|
||||||
|
|  |  |
|
||||||
|
| :-----------------------------------------------------: | :-----------------------------------------------------: |
|
||||||
|
| Example 1 | Example 2 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 数据库详情
|
||||||
|
|
||||||
|
* train包含2000组sequence采样方式生成的训练样本 ,示例如下
|
||||||
|
|
||||||
|
| 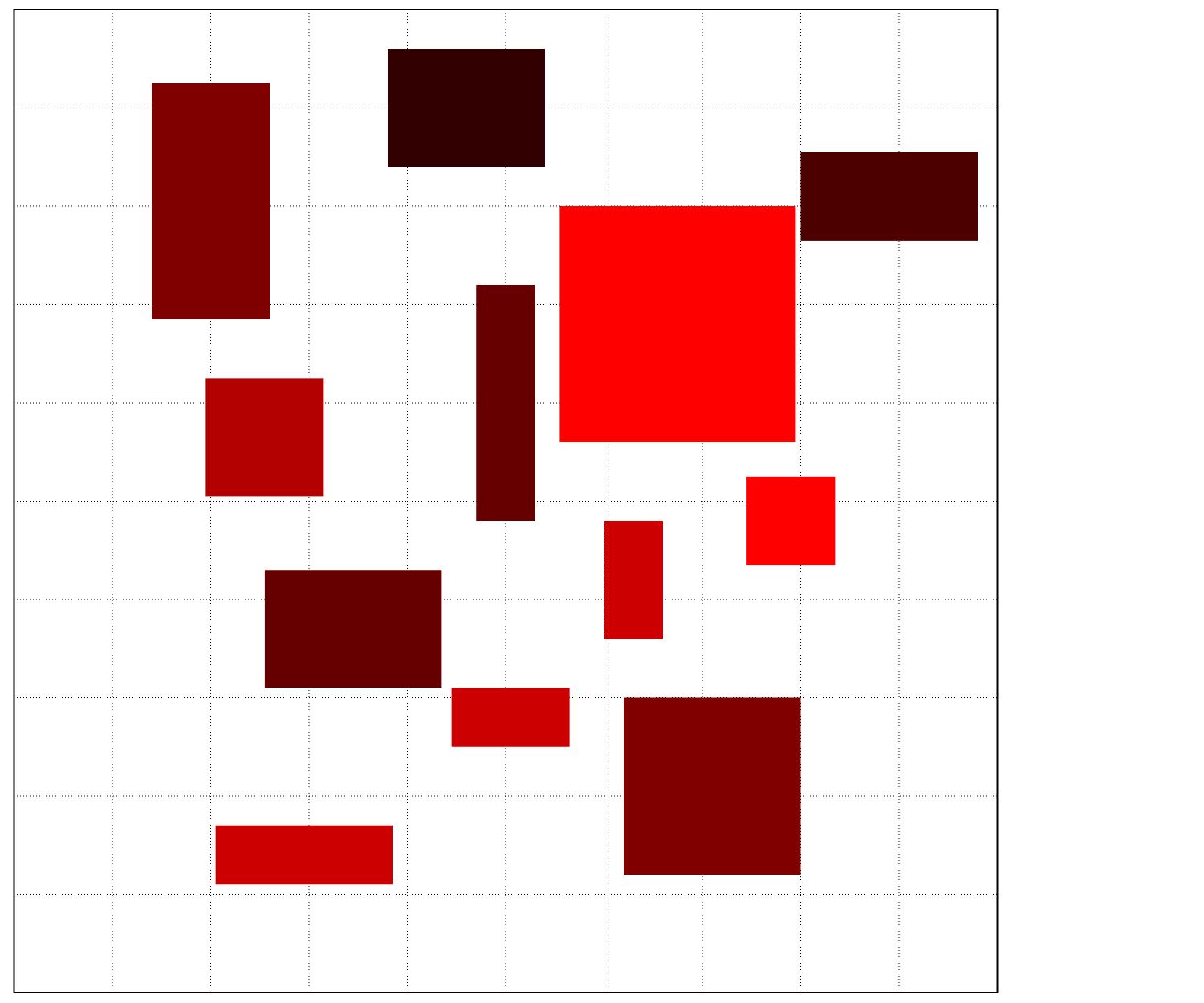 |  |  | 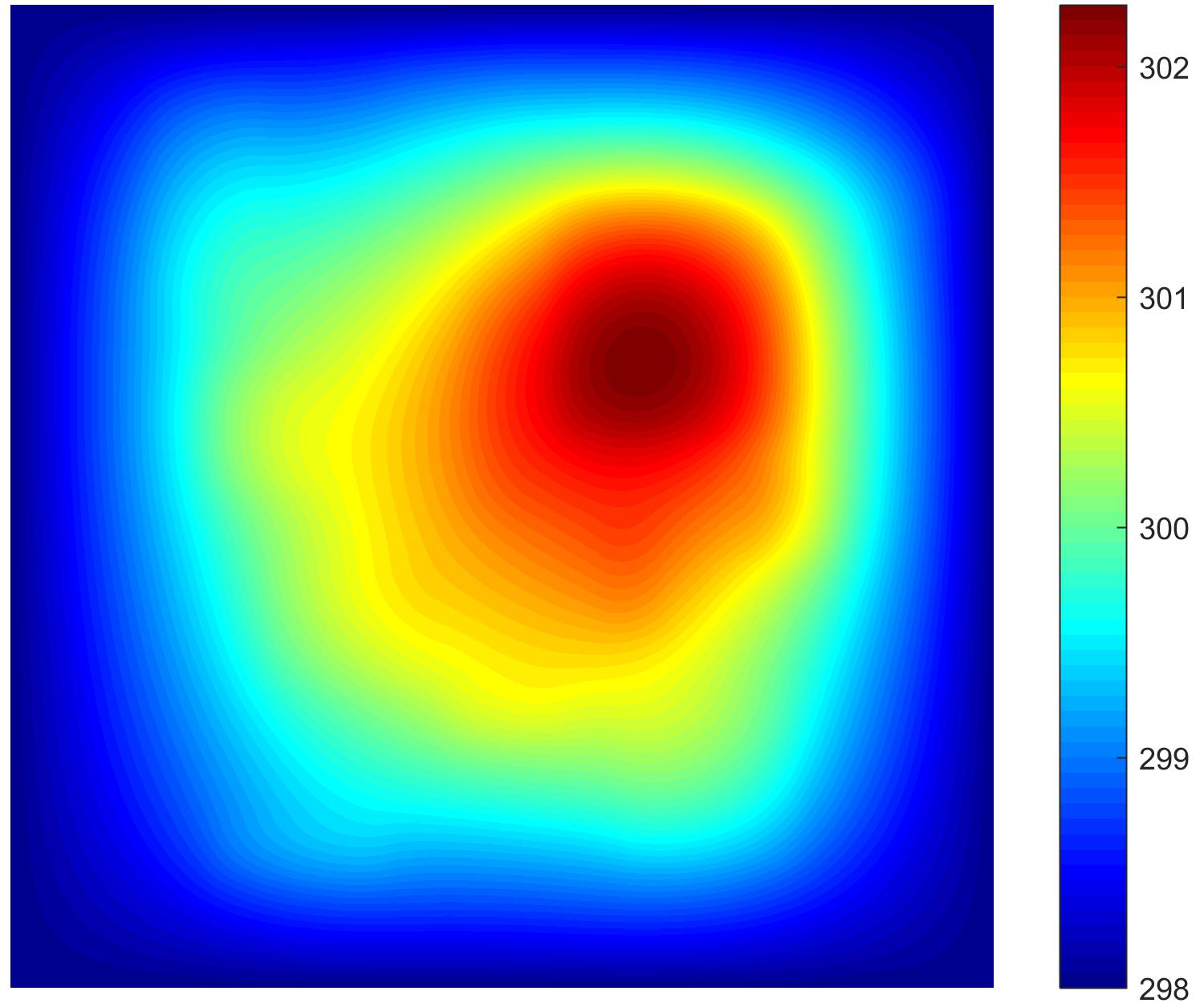 |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| heat layout | one point | rm_wall | all_walls |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* test包含不同方式获得的测试样本40000组
|
||||||
|
|
||||||
|
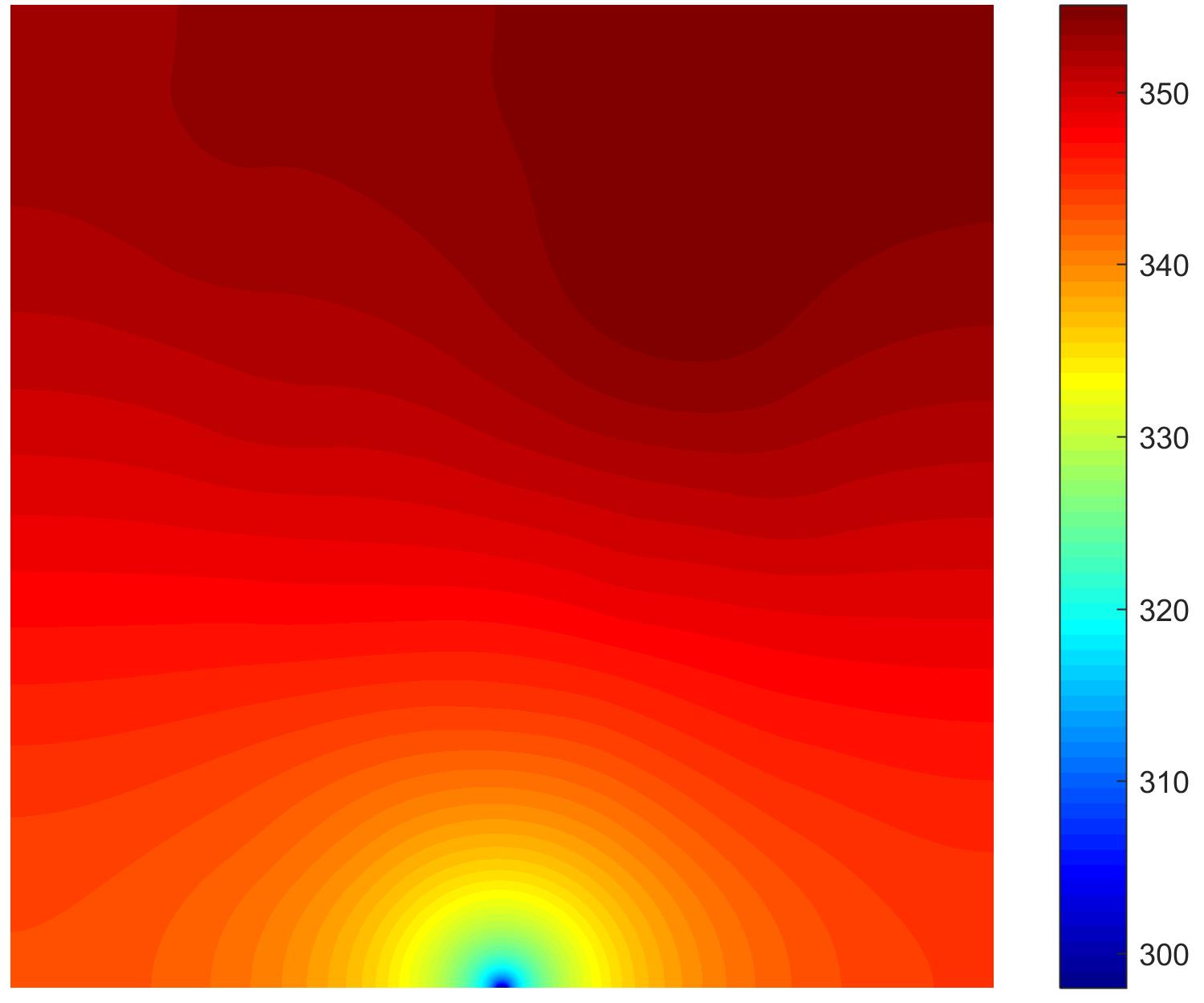
* `test_0.txt`通过sequence采样方式生成的10000组测试样本 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| Example 1 | Example 2 | Example 3 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
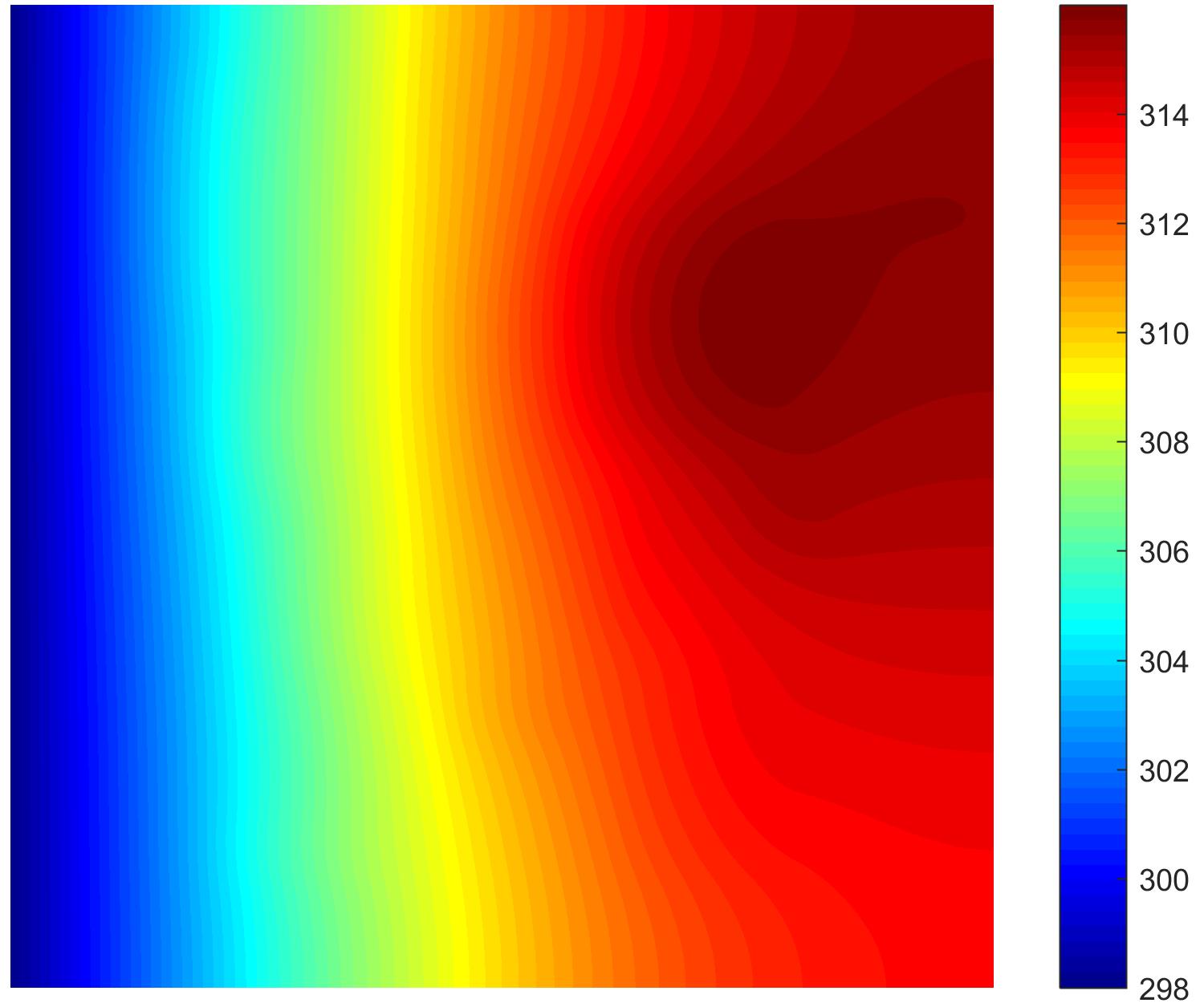
* `test_1.txt`通过gibbs方式采样生成的10000组测试样本 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| Example 1 | Example 2 | Example 3 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* `test_2.txt`功率相同或相近组件相邻构成的特殊组件布局样本,共有4类情况,每类情况1000组测试样本 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
|  |  |  |  |
|
||||||
|
| 8和12号组件 | 2和7和10号组件 | 5和11号组件 | 4和9号组件 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* `test_3.txt`组件布局密集在上半部,1/5区域,2/5区域,3/5区域,4/5区域,或下半部的测试样本,各1000组 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| 上半部 | 1/5区域 | 2/5区域 | 3/5区域 | 4/5区域 | 下半部 |
|
||||||
|
|
||||||
|
* `test_4.txt`组件布局密集在左半部,1/5区域,2/5区域,3/5区域,4/5区域,或右半部的测试样本,各1000组 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| 左半部 | 1/5区域 | 2/5区域 | 3/5区域 | 4/5区域 | 右半部 |
|
||||||
|
|
||||||
|
* `test_5.txt`组件布局在内部较小方形区域测试样本,共考虑100x100区域,120x120区域,140x140区域3种情况,各1000组测试样本 ,示例如下
|
||||||
|
|
||||||
|
|  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
|  |  |  |
|
||||||
|
| 100x100 | 120x120 | 140x140 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* `test_6.txt`最大功率布局在角落中的特殊样本,共1000组测试样本,示例如下
|
||||||
|
|
||||||
|
|  |  |  |  |
|
||||||
|
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| 右下角 | 左上角 | 左下角 | 左下角 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 其他
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,8 @@
|
||||||
|
aw_test0_1.mat
|
||||||
|
aw_test0_2.mat
|
||||||
|
aw_test0_3.mat
|
||||||
|
aw_test0_4.mat
|
||||||
|
aw_test0_5.mat
|
||||||
|
aw_test0_6.mat
|
||||||
|
aw_test0_7.mat
|
||||||
|
aw_test0_8.mat
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,10 @@
|
||||||
|
aw_train_1.mat
|
||||||
|
aw_train_2.mat
|
||||||
|
aw_train_3.mat
|
||||||
|
aw_train_4.mat
|
||||||
|
aw_train_5.mat
|
||||||
|
aw_train_6.mat
|
||||||
|
aw_train_7.mat
|
||||||
|
aw_train_8.mat
|
||||||
|
aw_train_9.mat
|
||||||
|
aw_train_10.mat
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,8 @@
|
||||||
|
op_test0_1.mat
|
||||||
|
op_test0_2.mat
|
||||||
|
op_test0_3.mat
|
||||||
|
op_test0_4.mat
|
||||||
|
op_test0_5.mat
|
||||||
|
op_test0_6.mat
|
||||||
|
op_test0_7.mat
|
||||||
|
op_test0_8.mat
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,10 @@
|
||||||
|
op_train_1.mat
|
||||||
|
op_train_2.mat
|
||||||
|
op_train_3.mat
|
||||||
|
op_train_4.mat
|
||||||
|
op_train_5.mat
|
||||||
|
op_train_6.mat
|
||||||
|
op_train_7.mat
|
||||||
|
op_train_8.mat
|
||||||
|
op_train_9.mat
|
||||||
|
op_train_10.mat
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,8 @@
|
||||||
|
rw_test0_1.mat
|
||||||
|
rw_test0_2.mat
|
||||||
|
rw_test0_3.mat
|
||||||
|
rw_test0_4.mat
|
||||||
|
rw_test0_5.mat
|
||||||
|
rw_test0_6.mat
|
||||||
|
rw_test0_7.mat
|
||||||
|
rw_test0_8.mat
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,10 @@
|
||||||
|
rw_train_1.mat
|
||||||
|
rw_train_2.mat
|
||||||
|
rw_train_3.mat
|
||||||
|
rw_train_4.mat
|
||||||
|
rw_train_5.mat
|
||||||
|
rw_train_6.mat
|
||||||
|
rw_train_7.mat
|
||||||
|
rw_train_8.mat
|
||||||
|
rw_train_9.mat
|
||||||
|
rw_train_10.mat
|
||||||
|
|
@ -0,0 +1,200 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
import math
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from torch.utils.data import DataLoader, random_split
|
||||||
|
import torchvision
|
||||||
|
from torch.optim.lr_scheduler import ExponentialLR
|
||||||
|
from pytorch_lightning import LightningModule
|
||||||
|
|
||||||
|
from src.data.layout import LayoutDataset
|
||||||
|
import src.utils.np_transforms as transforms
|
||||||
|
import src.models as models
|
||||||
|
from src.metric.metrics import Metric
|
||||||
|
|
||||||
|
|
||||||
|
class Model(LightningModule):
|
||||||
|
|
||||||
|
def __init__(self, hparams):
|
||||||
|
super().__init__()
|
||||||
|
self.hparams = hparams
|
||||||
|
self._build_model()
|
||||||
|
self.criterion = nn.L1Loss()
|
||||||
|
self.train_dataset = None
|
||||||
|
self.val_dataset = None
|
||||||
|
self.test_dataset = None
|
||||||
|
|
||||||
|
def _build_model(self):
|
||||||
|
model_list = ["SegNet_AlexNet", "SegNet_VGG", "SegNet_ResNet18", "SegNet_ResNet50",
|
||||||
|
"SegNet_ResNet101", "SegNet_ResNet34", "SegNet_ResNet152",
|
||||||
|
"FPN_ResNet18", "FPN_ResNet50", "FPN_ResNet101", "FPN_ResNet34", "FPN_ResNet152",
|
||||||
|
"FCN_AlexNet", "FCN_VGG", "FCN_ResNet18", "FCN_ResNet50", "FCN_ResNet101",
|
||||||
|
"FCN_ResNet34", "FCN_ResNet152",
|
||||||
|
"UNet_VGG"]
|
||||||
|
layout_model = self.hparams.model_name + '_' + self.hparams.backbone
|
||||||
|
assert layout_model in model_list
|
||||||
|
self.model = getattr(models, layout_model)(in_channels=1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.model(x)
|
||||||
|
x = torch.sigmoid(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
def __dataloader(self, dataset, shuffle=False):
|
||||||
|
loader = DataLoader(
|
||||||
|
dataset=dataset,
|
||||||
|
shuffle=shuffle,
|
||||||
|
batch_size=self.hparams.batch_size,
|
||||||
|
num_workers=self.hparams.num_workers,
|
||||||
|
)
|
||||||
|
return loader
|
||||||
|
|
||||||
|
def configure_optimizers(self):
|
||||||
|
optimizer = torch.optim.Adam(self.parameters(),
|
||||||
|
lr=self.hparams.lr)
|
||||||
|
scheduler = ExponentialLR(optimizer, gamma=0.99)
|
||||||
|
return [optimizer], [scheduler]
|
||||||
|
|
||||||
|
def prepare_data(self):
|
||||||
|
"""Prepare dataset
|
||||||
|
"""
|
||||||
|
size: int = self.hparams.input_size
|
||||||
|
transform_layout = transforms.Compose(
|
||||||
|
[
|
||||||
|
transforms.Resize(size=(size, size)),
|
||||||
|
transforms.ToTensor(),
|
||||||
|
transforms.Normalize(
|
||||||
|
torch.tensor([self.hparams.mean_layout]),
|
||||||
|
torch.tensor([self.hparams.std_layout]),
|
||||||
|
),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
transform_heat = transforms.Compose(
|
||||||
|
[
|
||||||
|
transforms.Resize(size=(size, size)),
|
||||||
|
transforms.ToTensor(),
|
||||||
|
transforms.Normalize(
|
||||||
|
torch.tensor([self.hparams.mean_heat]),
|
||||||
|
torch.tensor([self.hparams.std_heat]),
|
||||||
|
),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
# here only support format "mat"
|
||||||
|
assert self.hparams.data_format == "mat"
|
||||||
|
trainval_dataset = LayoutDataset(
|
||||||
|
self.hparams.data_root,
|
||||||
|
self.hparams.boundary,
|
||||||
|
list_path=self.hparams.train_list,
|
||||||
|
train=True,
|
||||||
|
transform=transform_layout,
|
||||||
|
target_transform=transform_heat,
|
||||||
|
)
|
||||||
|
test_dataset = LayoutDataset(
|
||||||
|
self.hparams.data_root,
|
||||||
|
self.hparams.boundary,
|
||||||
|
list_path=self.hparams.test_list,
|
||||||
|
train=False,
|
||||||
|
transform=transform_layout,
|
||||||
|
target_transform=transform_heat,
|
||||||
|
)
|
||||||
|
|
||||||
|
# split train/val set
|
||||||
|
train_length, val_length = int(len(trainval_dataset) * 0.8), int(len(trainval_dataset) * 0.2)
|
||||||
|
train_dataset, val_dataset = torch.utils.data.random_split(trainval_dataset,
|
||||||
|
[train_length, val_length])
|
||||||
|
|
||||||
|
print(
|
||||||
|
f"Prepared dataset, train:{int(len(train_dataset))},\
|
||||||
|
val:{int(len(val_dataset))}, test:{len(test_dataset)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
# assign to use in dataloaders
|
||||||
|
self.train_dataset = self.__dataloader(train_dataset, shuffle=True)
|
||||||
|
self.val_dataset = self.__dataloader(val_dataset, shuffle=False)
|
||||||
|
self.test_dataset = self.__dataloader(test_dataset, shuffle=False)
|
||||||
|
|
||||||
|
def train_dataloader(self):
|
||||||
|
return self.train_dataset
|
||||||
|
|
||||||
|
def val_dataloader(self):
|
||||||
|
return self.val_dataset
|
||||||
|
|
||||||
|
def test_dataloader(self):
|
||||||
|
return self.test_dataset
|
||||||
|
|
||||||
|
def training_step(self, batch, batch_idx):
|
||||||
|
layout, heat = batch
|
||||||
|
heat_pred = self(layout)
|
||||||
|
loss = self.criterion(heat, heat_pred)
|
||||||
|
self.log("train/training_mae", loss * self.hparams.std_heat)
|
||||||
|
|
||||||
|
if batch_idx == 0:
|
||||||
|
grid = torchvision.utils.make_grid(
|
||||||
|
heat_pred[:4, ...], normalize=True
|
||||||
|
)
|
||||||
|
self.logger.experiment.add_image(
|
||||||
|
"train_pred_heat_field", grid, self.global_step
|
||||||
|
)
|
||||||
|
if self.global_step == 0:
|
||||||
|
grid = torchvision.utils.make_grid(
|
||||||
|
heat[:4, ...], normalize=True
|
||||||
|
)
|
||||||
|
self.logger.experiment.add_image(
|
||||||
|
"train_heat_field", grid, self.global_step
|
||||||
|
)
|
||||||
|
|
||||||
|
return {"loss": loss}
|
||||||
|
|
||||||
|
def validation_step(self, batch, batch_idx):
|
||||||
|
layout, heat = batch
|
||||||
|
heat_pred = self(layout)
|
||||||
|
loss = self.criterion(heat, heat_pred)
|
||||||
|
return {"val_loss": loss}
|
||||||
|
|
||||||
|
def validation_epoch_end(self, outputs):
|
||||||
|
val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean()
|
||||||
|
self.log("val/val_mae", val_loss_mean.item() * self.hparams.std_heat)
|
||||||
|
|
||||||
|
def test_step(self, batch, batch_idx):
|
||||||
|
layout, heat = batch
|
||||||
|
heat_pred = self(layout)
|
||||||
|
|
||||||
|
data_config = Path(__file__).absolute().parent.parent / "config/data.yml"
|
||||||
|
layout_metric = Metric(heat_pred, heat, boundary=self.hparams.boundary,
|
||||||
|
layout=layout, data_config=data_config, hparams=self.hparams)
|
||||||
|
assert self.hparams.metric in layout_metric.metrics
|
||||||
|
loss = getattr(layout_metric, self.hparams.metric)()
|
||||||
|
return {"test_loss": loss}
|
||||||
|
|
||||||
|
def test_epoch_end(self, outputs):
|
||||||
|
test_loss_mean = torch.stack([x["test_loss"] for x in outputs]).mean()
|
||||||
|
self.log("test_loss (" + self.hparams.metric +")", test_loss_mean.item())
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def add_model_specific_args(parser): # pragma: no-cover
|
||||||
|
"""Parameters you define here will be available to your model through `self.hparams`.
|
||||||
|
"""
|
||||||
|
# dataset args
|
||||||
|
parser.add_argument("--data_root", type=str, required=True, help="path of dataset")
|
||||||
|
parser.add_argument("--train_list", type=str, required=True, help="path of train dataset list")
|
||||||
|
parser.add_argument("--train_size", default=0.8, type=float, help="train_size in train_test_split")
|
||||||
|
parser.add_argument("--test_list", type=str, required=True, help="path of test dataset list")
|
||||||
|
parser.add_argument("--boundary", type=str, default="rm_wall", help="boundary condition")
|
||||||
|
parser.add_argument("--data_format", type=str, default="mat", choices=["mat", "h5"], help="dataset format")
|
||||||
|
|
||||||
|
# Normalization params
|
||||||
|
parser.add_argument("--mean_layout", default=0, type=float)
|
||||||
|
parser.add_argument("--std_layout", default=1, type=float)
|
||||||
|
parser.add_argument("--mean_heat", default=0, type=float)
|
||||||
|
parser.add_argument("--std_heat", default=1, type=float)
|
||||||
|
|
||||||
|
# Model params (opt)
|
||||||
|
parser.add_argument("--input_size", default=200, type=int)
|
||||||
|
parser.add_argument("--model_name", type=str, default='SegNet', help="the name of chosen model")
|
||||||
|
parser.add_argument("--backbone", type=str, default='ResNet18', help="the used backbone in the regression model")
|
||||||
|
parser.add_argument("--metric", type=str, default='mae_global',
|
||||||
|
help="the used metric for evaluation of testing")
|
||||||
|
return parser
|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
"""Layout dataset
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
from .loadresponse import LoadResponse, mat_loader
|
||||||
|
|
||||||
|
|
||||||
|
class LayoutDataset(LoadResponse):
|
||||||
|
"""Layout dataset (mutiple files) generated by 'layout-generator'.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
root,
|
||||||
|
sub_dir,
|
||||||
|
list_path=None,
|
||||||
|
train=True,
|
||||||
|
transform=None,
|
||||||
|
target_transform=None,
|
||||||
|
load_name="F",
|
||||||
|
resp_name="u",
|
||||||
|
):
|
||||||
|
subdir = os.path.join("train", "train") \
|
||||||
|
if train else os.path.join("test", "test")
|
||||||
|
|
||||||
|
# find the path of the list of train/test samples
|
||||||
|
list_path = os.path.join(root, sub_dir, list_path)
|
||||||
|
|
||||||
|
# find the root path of the samples
|
||||||
|
root = os.path.join(root, sub_dir, subdir)
|
||||||
|
|
||||||
|
super().__init__(
|
||||||
|
root,
|
||||||
|
mat_loader,
|
||||||
|
list_path,
|
||||||
|
load_name=load_name,
|
||||||
|
resp_name=resp_name,
|
||||||
|
extensions="mat",
|
||||||
|
transform=transform,
|
||||||
|
target_transform=target_transform,
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
"""Load Response Dataset.
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
|
||||||
|
import scipy.io as sio
|
||||||
|
import numpy as np
|
||||||
|
from torchvision.datasets import VisionDataset
|
||||||
|
|
||||||
|
|
||||||
|
class LoadResponse(VisionDataset):
|
||||||
|
"""Some Information about LoadResponse dataset"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
root,
|
||||||
|
loader,
|
||||||
|
list_path,
|
||||||
|
load_name="F",
|
||||||
|
resp_name="u",
|
||||||
|
extensions=None,
|
||||||
|
transform=None,
|
||||||
|
target_transform=None,
|
||||||
|
is_valid_file=None,
|
||||||
|
):
|
||||||
|
super().__init__(
|
||||||
|
root, transform=transform, target_transform=target_transform
|
||||||
|
)
|
||||||
|
self.list_path = list_path
|
||||||
|
self.loader = loader
|
||||||
|
self.load_name = load_name
|
||||||
|
self.resp_name = resp_name
|
||||||
|
self.extensions = extensions
|
||||||
|
self.sample_files = make_dataset_list(root, list_path, extensions, is_valid_file)
|
||||||
|
|
||||||
|
def __getitem__(self, index):
|
||||||
|
path = self.sample_files[index]
|
||||||
|
load, resp = self.loader(path, self.load_name, self.resp_name)
|
||||||
|
|
||||||
|
if self.transform is not None:
|
||||||
|
load = self.transform(load)
|
||||||
|
if self.target_transform is not None:
|
||||||
|
resp = self.target_transform(resp)
|
||||||
|
return load, resp
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self.sample_files)
|
||||||
|
|
||||||
|
|
||||||
|
def make_dataset(root_dir, extensions=None, is_valid_file=None):
|
||||||
|
"""make_dataset() from torchvision.
|
||||||
|
"""
|
||||||
|
files = []
|
||||||
|
root_dir = os.path.expanduser(root_dir)
|
||||||
|
if not ((extensions is None) ^ (is_valid_file is None)):
|
||||||
|
raise ValueError(
|
||||||
|
"Both extensions and is_valid_file \
|
||||||
|
cannot be None or not None at the same time"
|
||||||
|
)
|
||||||
|
if extensions is not None:
|
||||||
|
is_valid_file = lambda x: has_allowed_extension(x, extensions)
|
||||||
|
|
||||||
|
assert os.path.isdir(root_dir), root_dir
|
||||||
|
for root, _, fns in sorted(os.walk(root_dir, followlinks=True)):
|
||||||
|
for fn in sorted(fns):
|
||||||
|
path = os.path.join(root, fn)
|
||||||
|
if is_valid_file(path):
|
||||||
|
files.append(path)
|
||||||
|
return files
|
||||||
|
|
||||||
|
|
||||||
|
def make_dataset_list(root_dir, list_path, extensions=None, is_valid_file=None):
|
||||||
|
"""make_dataset() from torchvision.
|
||||||
|
"""
|
||||||
|
files = []
|
||||||
|
root_dir = os.path.expanduser(root_dir)
|
||||||
|
if not ((extensions is None) ^ (is_valid_file is None)):
|
||||||
|
raise ValueError(
|
||||||
|
"Both extensions and is_valid_file \
|
||||||
|
cannot be None or not None at the same time"
|
||||||
|
)
|
||||||
|
if extensions is not None:
|
||||||
|
is_valid_file = lambda x: has_allowed_extension(x, extensions)
|
||||||
|
|
||||||
|
assert os.path.isdir(root_dir), root_dir
|
||||||
|
with open(list_path, 'r') as rf:
|
||||||
|
for line in rf.readlines():
|
||||||
|
data_path = line.strip()
|
||||||
|
path = os.path.join(root_dir, data_path)
|
||||||
|
if is_valid_file(path):
|
||||||
|
files.append(path)
|
||||||
|
return files
|
||||||
|
|
||||||
|
|
||||||
|
def has_allowed_extension(filename, extensions):
|
||||||
|
return filename.lower().endswith(extensions)
|
||||||
|
|
||||||
|
|
||||||
|
def mat_loader(path, load_name, resp_name=None):
|
||||||
|
mats = sio.loadmat(path)
|
||||||
|
load = mats.get(load_name)
|
||||||
|
resp = mats.get(resp_name) if resp_name is not None else None
|
||||||
|
return load, resp
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
total_num = 50000
|
||||||
|
with open('train'+str(total_num)+'.txt', 'w') as wf:
|
||||||
|
for idx in range(int(total_num*0.8)):
|
||||||
|
wf.write('Example'+str(idx)+'.mat'+'\n')
|
||||||
|
with open('val'+str(total_num)+'.txt', 'w') as wf:
|
||||||
|
for idx in range(int(total_num*0.8), total_num):
|
||||||
|
wf.write('Example'+str(idx)+'.mat'+'\n')
|
||||||
|
|
@ -0,0 +1,25 @@
|
||||||
|
# Metrics for benchmark
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
> 本项目根据不同的需求构造了不同的metric准则,评价模型训练的好坏。
|
||||||
|
|
||||||
|
## Metrics准则
|
||||||
|
|
||||||
|
> 根据不同的需求,构造了pixel-level metrics,image-level metrics和batch-level metrics
|
||||||
|
|
||||||
|
* Pixel-level metrics
|
||||||
|
* `value_and_pos_error_of_maximum_temperature`: 最高温的预测误差和最高温发生位置的预测误差
|
||||||
|
* 可选参数`output_type`:`value`和`position`,默认`value`,其中`value`输出最高温预测误差,`position`输出最高温位置预测误差。
|
||||||
|
|
||||||
|
* Image-level metrics
|
||||||
|
* `mae_global`: 全局温度平均预测误差
|
||||||
|
* `mae_boundary`: 边界处温度平均预测误差
|
||||||
|
* 可选参数`output_type`:`Dirichlet`和`Neumann`,默认`Dirichlet`,其中`Dirichlet`输出`Dirichlet`边界处温度平均预测误差,`Neumann`输出`Neumann`边界处温度平均预测误差。
|
||||||
|
* `mae_component`: 最大的组件处温度平均预测误差
|
||||||
|
* `global_image_spearmanr`: 预测温度场和真实温度场的Spearman相关系数
|
||||||
|
|
||||||
|
- Batch-level metrics
|
||||||
|
- `max_tem_spearmanr`: 不同样本的预测最高温排序和真实最高温排序的Spearman相关系数,衡量代理模型对不同布局对应的最高温进行正确排序的能力
|
||||||
|
|
||||||
|
## 其他
|
||||||
|
|
@ -0,0 +1,464 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
import copy
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import yaml
|
||||||
|
import numpy as np
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from scipy.stats import spearmanr
|
||||||
|
|
||||||
|
|
||||||
|
class Metric:
|
||||||
|
|
||||||
|
def __init__(self, input, target, boundary=None,
|
||||||
|
layout=None, data_config=None, hparams=None):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
input: (batch size x 1 x N x N or N x N) the predicted temperature field
|
||||||
|
target: (batch size x 1 x N x N or N x N) the real temperature field
|
||||||
|
boundary: 'all_walls' - all the dirichlet BCs
|
||||||
|
: 'rm_wall' - the neumann BCs for three sides and the dirichlet BCs for one side
|
||||||
|
: 'one_point' - all the neumann BCs except one tiny heatsink with dirichlet BC
|
||||||
|
layout: Input layout
|
||||||
|
data_config: Dataset parameter
|
||||||
|
hparams: Model parameter
|
||||||
|
"""
|
||||||
|
self.data_config = data_config
|
||||||
|
self.layout = layout
|
||||||
|
self.boundary = boundary
|
||||||
|
self.input = input
|
||||||
|
self.target = target
|
||||||
|
self.hparams = hparams
|
||||||
|
self.data = None
|
||||||
|
self.data_info()
|
||||||
|
self.metrics = self.all_metrics()
|
||||||
|
|
||||||
|
def all_metrics(self):
|
||||||
|
self.metrics = ["mae_global", "mae_boundary", "mae_component",
|
||||||
|
"value_and_pos_error_of_maximum_temperature", "max_tem_spearmanr",
|
||||||
|
"global_image_spearmanr"]
|
||||||
|
return self.metrics
|
||||||
|
|
||||||
|
def data_info(self):
|
||||||
|
data_yaml = open(self.data_config, 'r', encoding='gbk')
|
||||||
|
self.data = yaml.load(data_yaml, yaml.FullLoader)
|
||||||
|
self.L = self.data['length']
|
||||||
|
self.power = np.array(self.data['powers']) / self.hparams.std_layout
|
||||||
|
self.comp_size = np.array(self.data['units'])
|
||||||
|
self.comp_pixel_size = np.round(self.comp_size / self.L * 200).astype(int)
|
||||||
|
|
||||||
|
# -------------------tool functions--------------------------#
|
||||||
|
def identify_same_power(self, power):
|
||||||
|
org_power = np.array(power)
|
||||||
|
power1 = np.array(list(set(power))) # 对元素去重
|
||||||
|
indx1 = []
|
||||||
|
indx2 = []
|
||||||
|
indx3 = []
|
||||||
|
for i in range(len(power1)):
|
||||||
|
ind = np.where(org_power == power1[i])[0]
|
||||||
|
if len(ind) == 1: # 一个组件一个功率
|
||||||
|
indx1 = indx1 + list(ind)
|
||||||
|
elif len(ind) == 2: # 两个组件一个功率
|
||||||
|
indx2 = indx2 + list(ind)
|
||||||
|
elif len(ind) == 3: # 三个组件一个功率
|
||||||
|
indx3 = indx3 + list(ind)
|
||||||
|
else:
|
||||||
|
print('There are four components with the same intensity!')
|
||||||
|
return (indx1, indx2, indx3)
|
||||||
|
|
||||||
|
def identify_component_boundary(self, layout, power, boundary):
|
||||||
|
"""
|
||||||
|
find the pixel locations of components
|
||||||
|
|
||||||
|
Args:
|
||||||
|
layout: pixel-level representation
|
||||||
|
power: the component dissapation power
|
||||||
|
boundary: 'all_walls' - all the dirichlet BCs
|
||||||
|
: 'rm_wall' - the neumann BCs for three sides and the dirichlet BCs for one side
|
||||||
|
: 'one_point' - all the neumann BCs except one tiny heatsink with dirichlet BC
|
||||||
|
When boundary is 'one_point', the input layout should be transposed and then read in an inverse-row order.
|
||||||
|
Returns:
|
||||||
|
location: -> Tensor: N * 4, pixel coordinates
|
||||||
|
"""
|
||||||
|
if boundary == 'one_point':
|
||||||
|
temp = layout.cpu().numpy().T[::-1].copy()
|
||||||
|
layout = torch.from_numpy(temp)
|
||||||
|
|
||||||
|
comp_num = len(power)
|
||||||
|
location = torch.zeros(comp_num, 4)
|
||||||
|
|
||||||
|
(indx1, indx2, indx3) = self.identify_same_power(power)
|
||||||
|
|
||||||
|
for i in range(comp_num):
|
||||||
|
[index_x, index_y] = torch.where(layout == power[i])
|
||||||
|
if i in indx1:
|
||||||
|
xmin, xmax = torch.min(index_x).item(), torch.max(index_x).item()
|
||||||
|
ymin, ymax = torch.min(index_y).item(), torch.max(index_y).item()
|
||||||
|
location[i, :] = torch.tensor([xmin, xmax, ymin, ymax])
|
||||||
|
if i in indx2: # [3, 8, 4, 10, 7, 11] # 4 和 9 号组件,P=8, 5和11,P=10, 8和12,P=12
|
||||||
|
flag1 = 0
|
||||||
|
layout_flag = torch.zeros_like(layout)
|
||||||
|
layout_flag[index_x, index_y] = 1
|
||||||
|
|
||||||
|
for j in range(int(len(indx2)/2)):
|
||||||
|
temp = indx2[(2*j): (2*j + 2)]
|
||||||
|
if i in temp:
|
||||||
|
comp_index = temp
|
||||||
|
|
||||||
|
comp_coord = self.find_comp_coordinate(layout_flag, self.comp_pixel_size, comp_index)
|
||||||
|
if comp_coord is None:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
location[comp_index[0], :] = torch.tensor(comp_coord[0])
|
||||||
|
location[comp_index[1], :] = torch.tensor(comp_coord[1])
|
||||||
|
flag1 = 1
|
||||||
|
if flag1 == 0:
|
||||||
|
print("Something wrong! Cannot locate the component #", i)
|
||||||
|
if i in indx3: # [1, 6, 9]
|
||||||
|
if i == 1:
|
||||||
|
flag2 = 0 # to indicate whether locate the components
|
||||||
|
layout_flag = torch.zeros_like(layout)
|
||||||
|
layout_flag[index_x, index_y] = 1
|
||||||
|
xmin1, ymin1 = self.find_left_top_point(index_x, index_y)
|
||||||
|
xmax1 = xmin1 + self.comp_pixel_size[i, 0] - 1
|
||||||
|
ymax1 = ymin1 + self.comp_pixel_size[i, 1] - 1
|
||||||
|
layout_flag[xmin1: (xmax1 + 1), ymin1: (ymax1 + 1)] = 0
|
||||||
|
for j in range(int(len(indx3)/3)):
|
||||||
|
temp = indx3[(3*j): (3*j + 3)]
|
||||||
|
if i in temp:
|
||||||
|
comp_index = temp
|
||||||
|
comp_index.remove(i)
|
||||||
|
comp_coord = self.find_comp_coordinate(layout_flag, self.comp_pixel_size, comp_index)
|
||||||
|
if comp_coord is None:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
location[i, :] = torch.tensor([xmin1, xmax1, ymin1, ymax1])
|
||||||
|
location[comp_index[0], :] = torch.tensor(comp_coord[0])
|
||||||
|
location[comp_index[1], :] = torch.tensor(comp_coord[1])
|
||||||
|
flag2 += 1
|
||||||
|
if i == 9 and flag2 == 0:
|
||||||
|
print("Something wrong! Cannot locate components # 2, 7, 10")
|
||||||
|
return location
|
||||||
|
|
||||||
|
def find_left_top_point(self, index_x, index_y):
|
||||||
|
x_min = torch.min(index_x).item()
|
||||||
|
indx_min = torch.where(index_x == torch.min(index_x))[0]
|
||||||
|
temp = index_y[indx_min]
|
||||||
|
y_min = torch.min(temp).item()
|
||||||
|
return (x_min, y_min)
|
||||||
|
|
||||||
|
def find_comp_coordinate(self, layout, comp_pixel_size, comp_index):
|
||||||
|
layout_flag = copy.deepcopy(layout)
|
||||||
|
|
||||||
|
indx, indy = torch.where(layout_flag == 1)
|
||||||
|
x_min1, y_min1 = self.find_left_top_point(indx, indy)
|
||||||
|
x_max1 = x_min1 + comp_pixel_size[comp_index[0], 0] - 1
|
||||||
|
y_max1 = y_min1 + comp_pixel_size[comp_index[0], 1] - 1
|
||||||
|
layout_flag[x_min1: x_max1 + 1, y_min1: y_max1 + 1] = 0
|
||||||
|
|
||||||
|
indx, indy = torch.where(layout_flag == 1)
|
||||||
|
x_min2, y_min2 = self.find_left_top_point(indx, indy)
|
||||||
|
x_max2 = x_min2 + comp_pixel_size[comp_index[1], 0] - 1
|
||||||
|
y_max2 = y_min2 + comp_pixel_size[comp_index[1], 1] - 1
|
||||||
|
layout_flag[x_min2: x_max2 + 1, y_min2: y_max2 + 1] = 0
|
||||||
|
if torch.sum(layout_flag) == 0:
|
||||||
|
return ([x_min1, x_max1, y_min1, y_max1], [x_min2, x_max2, y_min2, y_max2])
|
||||||
|
else:
|
||||||
|
layout_flag = copy.deepcopy(layout)
|
||||||
|
x_max1 = x_min1 + comp_pixel_size[comp_index[1], 0] - 1
|
||||||
|
y_max1 = y_min1 + comp_pixel_size[comp_index[1], 1] - 1
|
||||||
|
layout_flag[x_min1: x_max1 + 1, y_min1: y_max1 + 1] = 0
|
||||||
|
indx, indy = torch.where(layout_flag == 1)
|
||||||
|
x_min2, y_min2 = self.find_left_top_point(indx, indy)
|
||||||
|
x_max2 = x_min2 + comp_pixel_size[comp_index[0], 0] - 1
|
||||||
|
y_max2 = y_min2 + comp_pixel_size[comp_index[0], 1] - 1
|
||||||
|
layout_flag[x_min2: x_max2 + 1, y_min2: y_max2 + 1] = 0
|
||||||
|
if torch.sum(layout_flag) == 0:
|
||||||
|
return ([x_min2, x_max2, y_min2, y_max2], [x_min1, x_max1, y_min1, y_max1])
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
# -------------------tool functions--------------------------#
|
||||||
|
|
||||||
|
# --------------metric functions from here-------------------#
|
||||||
|
def mae_global(self):
|
||||||
|
"""
|
||||||
|
calculate the global temperature prediction mean absolute error between input and target.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
mae: the mean absolute error of the whole field for a batch of samples
|
||||||
|
"""
|
||||||
|
return F.l1_loss(self.input, self.target, reduction='mean') * self.hparams.std_heat
|
||||||
|
|
||||||
|
def mae_boundary(self, output_type='Dirichlet', reduction='mean'):
|
||||||
|
"""
|
||||||
|
calculate the temperature perdiction mean abosolute error of the boundary of the domain.
|
||||||
|
|
||||||
|
The input and target are tensors.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
output_type: 'Dirichlet' for outputing the error of Dirichlet boundary
|
||||||
|
'Neumann' for outputing the error of Neumann boundary
|
||||||
|
Returns:
|
||||||
|
mae: (dirichlet, neumann) -> tuple: the specific (mean for batch > 1) mae in the boundary
|
||||||
|
"""
|
||||||
|
if self.input.dim() == 2:
|
||||||
|
[nx, ny] = self.input.shape
|
||||||
|
batch = 1
|
||||||
|
std_input = self.input.unsqueeze(0).unsqueeze(0).cpu()
|
||||||
|
std_target = self.target.unsqueeze(0).unsqueeze(0).cpu()
|
||||||
|
elif self.input.dim() == 4:
|
||||||
|
[batch, channel, nx, ny] = self.input.shape
|
||||||
|
std_input = self.input.cpu()
|
||||||
|
std_target = self.target.cpu()
|
||||||
|
if channel != 1:
|
||||||
|
raise ValueError('Please input tensors with channel = 1.')
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input four-dim or two-dim tensors with (batch * 1 *) N * N.")
|
||||||
|
|
||||||
|
num_boundaryelement = 2*nx + 2*ny - 4 # 边界元素总数
|
||||||
|
# 初始化边界总 mask
|
||||||
|
mask = torch.zeros([nx, ny])
|
||||||
|
mask[..., 0, :] = 1
|
||||||
|
mask[..., -1, :] = 1
|
||||||
|
mask[..., :, 0] = 1
|
||||||
|
mask[..., :, -1] = 1
|
||||||
|
if self.boundary == 'all_walls':
|
||||||
|
num_dBC = num_boundaryelement
|
||||||
|
num_nBC = 0
|
||||||
|
dBC_mask = mask
|
||||||
|
nBC_mask = mask - dBC_mask
|
||||||
|
else:
|
||||||
|
[index_x, index_y] = torch.where(self.target[0, 0, :, :] == torch.min(self.target[0, 0, :, :]))
|
||||||
|
dBC_mask = torch.zeros_like(mask)
|
||||||
|
num_dBC = torch.max(torch.tensor([index_x[-1] - index_x[0] + 1, (index_y[-1] - index_y[0] + 1)])).item()
|
||||||
|
num_nBC = num_boundaryelement - num_dBC
|
||||||
|
dBC_mask[index_x, index_y] = 1
|
||||||
|
nBC_mask = mask - dBC_mask
|
||||||
|
dBC_mask.unsqueeze_(0).unsqueeze_(0)
|
||||||
|
nBC_mask.unsqueeze_(0).unsqueeze_(0)
|
||||||
|
|
||||||
|
dBC_input = std_input * dBC_mask
|
||||||
|
dBC_target = std_target * dBC_mask
|
||||||
|
nBC_input = std_input * nBC_mask
|
||||||
|
nBC_target = std_target * nBC_mask
|
||||||
|
|
||||||
|
dirichletBC_mae = torch.sum(torch.abs(dBC_input - dBC_target), (1, 2, 3)) / num_dBC
|
||||||
|
neumannBC_mae = (torch.sum(torch.abs(nBC_input - nBC_target), (1, 2, 3)) / num_nBC if num_nBC else torch.zeros([batch]))
|
||||||
|
if reduction == 'mean':
|
||||||
|
dir_mae = torch.mean(dirichletBC_mae)
|
||||||
|
neu_mae = torch.mean(neumannBC_mae)
|
||||||
|
elif reduction == 'max':
|
||||||
|
dir_mae = torch.max(dirichletBC_mae)
|
||||||
|
neu_mae = torch.max(neumannBC_mae)
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input reduction with 'mean' or 'max'.")
|
||||||
|
if output_type == 'Dirichlet':
|
||||||
|
return dir_mae * self.hparams.std_heat
|
||||||
|
elif output_type == 'Neumann':
|
||||||
|
return neu_mae * self.hparams.std_heat
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input the right boundary type ('Dirichlet' or 'Neumann').")
|
||||||
|
|
||||||
|
def mae_component(self, xs=None, ys=None):
|
||||||
|
"""
|
||||||
|
calculate the prediction mean absolute error of component-covering area
|
||||||
|
|
||||||
|
Args:
|
||||||
|
xs: meshgrid, N * N, when mesh = 'nonuniform', it is needed.
|
||||||
|
ys: meshgrid, N * N, when mesh = 'nonuniform', it is needed.
|
||||||
|
Returns:
|
||||||
|
comp_mae: -> list: with N elements
|
||||||
|
Note:
|
||||||
|
xs and ys have been generated and added automatically and specifically.
|
||||||
|
"""
|
||||||
|
if self.input.dim() != self.layout.dim():
|
||||||
|
raise ValueError("Please input 'layout' with the same size as 'input' tensors.")
|
||||||
|
|
||||||
|
if self.input.dim() == 2:
|
||||||
|
[nx, ny] = self.input.shape
|
||||||
|
batch = 1
|
||||||
|
std_input = self.input.unsqueeze(0).unsqueeze(0).cpu()
|
||||||
|
std_target = self.target.unsqueeze(0).unsqueeze(0).cpu()
|
||||||
|
std_layout = self.layout.unsqueeze(0).unsqueeze(0).cpu()
|
||||||
|
elif self.input.dim() == 4:
|
||||||
|
[batch, channel, nx, ny] = self.input.shape
|
||||||
|
std_input = self.input.cpu()
|
||||||
|
std_target = self.target.cpu()
|
||||||
|
std_layout = self.layout
|
||||||
|
if channel != 1:
|
||||||
|
raise ValueError('Please input tensors with channel = 1.')
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input four-dim or two-dim tensors with (batch * 1 *) N * N.")
|
||||||
|
|
||||||
|
domain_length = self.L
|
||||||
|
|
||||||
|
mesh = 'uniform'
|
||||||
|
if self.boundary == 'one_point':
|
||||||
|
mesh = 'nonuniform'
|
||||||
|
comp_mae_max_batch = torch.zeros(batch)
|
||||||
|
for k in range(batch):
|
||||||
|
single_input = std_input[k, 0, :, :]
|
||||||
|
single_target = std_target[k, 0, :, :]
|
||||||
|
single_layout = std_layout[k, 0, :, :]
|
||||||
|
|
||||||
|
location = self.identify_component_boundary(single_layout, self.power, self.boundary)
|
||||||
|
comp_num = len(self.power)
|
||||||
|
comp_mae = []
|
||||||
|
comp_mask = torch.zeros([comp_num, nx, ny])
|
||||||
|
comp_mae = torch.zeros([comp_num])
|
||||||
|
for i in range(comp_num):
|
||||||
|
[xmin, xmax, ymin, ymax] = location[i, :].numpy().astype(int)
|
||||||
|
mask = torch.zeros(nx, ny)
|
||||||
|
if mesh == 'uniform':
|
||||||
|
mask[xmin:(xmax + 1), ymin:(ymax + 1)] = 1
|
||||||
|
num_element = (xmax - xmin + 1) * (ymax - ymin + 1)
|
||||||
|
else:
|
||||||
|
if xs is None or ys is None:
|
||||||
|
xs = torch.linspace(0, domain_length, steps=200) # 生成200个均匀排列的数
|
||||||
|
ys = torch.linspace(0, domain_length, steps=200)
|
||||||
|
# 对应有限差分计算过程中的网格自适应加密函数
|
||||||
|
xs = 4 / ((xs[-1] - xs[0])**2) * ((xs - (xs[-1] + xs[0]) / 2)**3) + (xs[0] + xs[-1]) / 2
|
||||||
|
ys = ys**2 / (ys[0] + ys[-1]) + ys[0] * ys[-1] / (ys[0] + ys[-1])
|
||||||
|
xs, ys = torch.meshgrid(xs, ys)
|
||||||
|
x_min = xmin * domain_length / nx
|
||||||
|
x_max = (xmax + 1) * domain_length / nx
|
||||||
|
y_min = ymin * domain_length / ny
|
||||||
|
y_max = (ymax + 1) * domain_length / ny
|
||||||
|
ind = (xs >= x_min) & (xs <= x_max) & (ys >= y_min) & (ys <= y_max)
|
||||||
|
mask[ind] = 1
|
||||||
|
num_element = torch.sum(mask).item()
|
||||||
|
comp_mask[i, :, :] = mask
|
||||||
|
|
||||||
|
comp_input = single_input * mask
|
||||||
|
comp_target = single_target * mask
|
||||||
|
|
||||||
|
mae = torch.sum(torch.abs(comp_input - comp_target)) / num_element
|
||||||
|
comp_mae[i] = mae
|
||||||
|
comp_mae_max = torch.max(comp_mae)
|
||||||
|
comp_mae_max_batch[k] = comp_mae_max
|
||||||
|
return torch.mean(comp_mae_max_batch) * self.hparams.std_heat
|
||||||
|
|
||||||
|
def value_and_pos_error_of_maximum_temperature(self, output_type='value'):
|
||||||
|
"""
|
||||||
|
calculate the absolute error of the maximum temperature between input and target
|
||||||
|
|
||||||
|
Args:
|
||||||
|
output_type: 'value' for outputing the value error of maximum temperature
|
||||||
|
'position' for outputing the position error of maximum temperature
|
||||||
|
Returns:
|
||||||
|
error_max_tem: batch : the error of the maximum temperature between input and target
|
||||||
|
error_max_tem_pos: batch : the element error of the position of the maximum temperature
|
||||||
|
"""
|
||||||
|
if self.input.dim() == 2:
|
||||||
|
[nx, ny] = self.input.shape
|
||||||
|
batch = 1
|
||||||
|
std_input = self.input.unsqueeze(0)
|
||||||
|
std_target = self.target.unsqueeze(0)
|
||||||
|
elif self.input.dim() == 4:
|
||||||
|
[batch, channel, nx, ny] = self.input.shape
|
||||||
|
std_input = self.input.squeeze(1)
|
||||||
|
std_target = self.target.squeeze(1)
|
||||||
|
if channel != 1:
|
||||||
|
raise ValueError('Please input tensors with channel = 1.')
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input four-dim or two-dim tensors with (batch * 1 *) N * N.")
|
||||||
|
|
||||||
|
[input_max_tem, input_ind] = torch.max(std_input.reshape(batch, -1), 1)
|
||||||
|
[target_max_tem, target_ind] = torch.max(std_target.reshape(batch, -1), 1)
|
||||||
|
# 计算最高温的误差
|
||||||
|
error_max_temp = torch.abs(input_max_tem - target_max_tem)
|
||||||
|
# 找出最高温对应位置
|
||||||
|
input_max_tem_pos = torch.zeros(batch, 2)
|
||||||
|
target_max_tem_pos = torch.zeros(batch, 2)
|
||||||
|
for i in range(batch):
|
||||||
|
ind1 = input_ind[i].item()
|
||||||
|
ind2 = target_ind[i].item()
|
||||||
|
flag = ind1 % ny
|
||||||
|
ind1_x = ((ind1 // ny) if flag > 0 else (ind1 // ny - 1))
|
||||||
|
ind1_y = ((flag - 1) if flag > 0 else (ny - 1))
|
||||||
|
flag = ind2 % ny
|
||||||
|
ind2_x = ((ind2 // ny) if flag > 0 else (ind2 // ny - 1))
|
||||||
|
ind2_y = ((flag - 1) if flag > 0 else (ny - 1))
|
||||||
|
input_max_tem_pos[i, :] = torch.Tensor([ind1_x, ind1_y])
|
||||||
|
target_max_tem_pos[i, :] = torch.Tensor([ind2_x, ind2_y])
|
||||||
|
diff_pos = input_max_tem_pos - target_max_tem_pos
|
||||||
|
error_max_temp_pos = torch.sum(diff_pos * diff_pos, dim=1).sqrt_()
|
||||||
|
if output_type == 'value':
|
||||||
|
return torch.mean(error_max_temp) * self.hparams.std_heat
|
||||||
|
elif output_type == 'position':
|
||||||
|
return torch.mean(error_max_temp_pos)
|
||||||
|
else:
|
||||||
|
return ValueError("Please input the right output type ('value' or 'position').")
|
||||||
|
|
||||||
|
def max_tem_spearmanr(self):
|
||||||
|
"""
|
||||||
|
calculate the indicator (spearmanr) of the maximum temperature between input and target
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
rho: [-1, 1]
|
||||||
|
p_value: the smaller the better. (ideal: p_value < 0.05)
|
||||||
|
"""
|
||||||
|
if self.input.dim() == 2:
|
||||||
|
[nx, ny] = self.input.shape
|
||||||
|
batch = 1
|
||||||
|
std_input = self.input.unsqueeze(0)
|
||||||
|
std_target = self.target.unsqueeze(0)
|
||||||
|
elif self.input.dim() == 4:
|
||||||
|
[batch, channel, nx, ny] = self.input.shape
|
||||||
|
std_input = self.input.squeeze(1)
|
||||||
|
std_target = self.target.squeeze(1)
|
||||||
|
if channel != 1:
|
||||||
|
raise ValueError('Please input tensors with channel = 1.')
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input four-dim or two-dim tensors with (batch * 1 *) N * N.")
|
||||||
|
|
||||||
|
if batch == 1:
|
||||||
|
raise ValueError('please provide a batch of samples (batch > 1).')
|
||||||
|
input_max_tem = torch.max(std_input.reshape(batch, -1), 1)[0].data.cpu().numpy()
|
||||||
|
target_max_tem = torch.max(std_target.reshape(batch, -1), 1)[0].data.cpu().numpy()
|
||||||
|
rho, p_value = spearmanr(target_max_tem, input_max_tem)
|
||||||
|
return torch.tensor(rho)
|
||||||
|
|
||||||
|
def global_image_spearmanr(self):
|
||||||
|
"""
|
||||||
|
calculate the indicator (spearmanr) correlation coefficient between input and target
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
rho: [-1, 1]
|
||||||
|
p_value: the smaller the better. (ideal: p_value < 0.05)
|
||||||
|
"""
|
||||||
|
if self.input.dim() == 2:
|
||||||
|
[nx, ny] = self.input.shape
|
||||||
|
batch = 1
|
||||||
|
std_input = self.input.unsqueeze(0)
|
||||||
|
std_target = self.target.unsqueeze(0)
|
||||||
|
elif self.input.dim() == 4:
|
||||||
|
[batch, channel, nx, ny] = self.input.shape
|
||||||
|
std_input = self.input.squeeze(1)
|
||||||
|
std_target = self.target.squeeze(1)
|
||||||
|
if channel != 1:
|
||||||
|
raise ValueError('Please input tensors with channel = 1.')
|
||||||
|
else:
|
||||||
|
raise ValueError("Please input four-dim or two-dim tensors with (batch * 1 *) N * N.")
|
||||||
|
|
||||||
|
spear_batch = torch.zeros(batch)
|
||||||
|
for i in range(batch):
|
||||||
|
single_input = std_input[i, :, :].reshape(-1).data.cpu().numpy()
|
||||||
|
single_target = std_target[i, :, :].reshape(-1).data.cpu().numpy()
|
||||||
|
rho, p_value = spearmanr(single_input, single_target)
|
||||||
|
spear_batch[i] = rho
|
||||||
|
return torch.mean(spear_batch)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
|
||||||
|
data_config = Path(__file__).absolute().parent.parent.parent / "config/data.yml"
|
||||||
|
data_yaml = open(data_config, 'r', encoding='gbk')
|
||||||
|
data = yaml.load(data_yaml, Loader=yaml.FullLoader)
|
||||||
|
L = data['length']
|
||||||
|
power = data['powers']
|
||||||
|
comp_size = data['units']
|
||||||
|
|
||||||
|
print(np.array(L))
|
||||||
|
print(np.array(power))
|
||||||
|
print(np.array(comp_size))
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
from .unet import *
|
||||||
|
from .fcn import *
|
||||||
|
from .segnet import *
|
||||||
|
from .fpn import *
|
||||||
|
|
@ -0,0 +1,3 @@
|
||||||
|
from .alexnet import *
|
||||||
|
from .resnet import *
|
||||||
|
from .vgg import *
|
||||||
|
|
@ -0,0 +1,55 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
"""
|
||||||
|
Alexnet backbone
|
||||||
|
|
||||||
|
"""
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.utils.model_zoo as model_zoo
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["AlexNet"]
|
||||||
|
|
||||||
|
|
||||||
|
class AlexNet(nn.Module):
|
||||||
|
def __init__(self, in_channels=1, bn=False):
|
||||||
|
super(AlexNet, self).__init__()
|
||||||
|
self.features3 = nn.Sequential(
|
||||||
|
# kernel(11, 11) -> kernel(7, 7)
|
||||||
|
nn.Conv2d(in_channels=in_channels, out_channels=64,
|
||||||
|
kernel_size=7, stride=4, padding=3),
|
||||||
|
nn.BatchNorm2d(64) if bn else nn.GroupNorm(32, 64),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
# padding=0 -> padding=1
|
||||||
|
self.features4 = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=5, padding=2),
|
||||||
|
nn.BatchNorm2d(192) if bn else nn.GroupNorm(32, 192),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.features5 = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels=192, out_channels=384, kernel_size=3, padding=1),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
|
||||||
|
|
||||||
|
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||||
|
x = self.features3(x)
|
||||||
|
x, indices3 = self.maxpool(x)
|
||||||
|
x = self.features4(x)
|
||||||
|
x, indices4 = self.maxpool(x)
|
||||||
|
x = self.features5(x)
|
||||||
|
x, indices5 = self.maxpool(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
x = torch.zeros(8, 1, 200, 200)
|
||||||
|
net = Alexnet()
|
||||||
|
print(net)
|
||||||
|
y = net(x)
|
||||||
|
print()
|
||||||
|
|
@ -0,0 +1,233 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
"""
|
||||||
|
ResNet backbone
|
||||||
|
|
||||||
|
"""
|
||||||
|
import math
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.utils.model_zoo as model_zoo
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["ResNet", "resnet18", "resnet34", "resnet50", "resnet101", "resnet152"]
|
||||||
|
|
||||||
|
|
||||||
|
model_urls = {
|
||||||
|
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
|
||||||
|
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
|
||||||
|
"resnet50": "https://download.pytorch.org/models/resnet50-19c8e357.pth",
|
||||||
|
"resnet101": "https://download.pytorch.org/models/resnet101-5d3b4d8f.pth",
|
||||||
|
"resnet152": "https://download.pytorch.org/models/resnet152-b121ed2d.pth",
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def conv3x3(in_planes, out_planes, stride=1):
|
||||||
|
"""3x3 convolution with padding"""
|
||||||
|
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
|
||||||
|
|
||||||
|
|
||||||
|
class BasicBlock(nn.Module):
|
||||||
|
expansion = 1
|
||||||
|
|
||||||
|
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
||||||
|
super(BasicBlock, self).__init__()
|
||||||
|
self.conv1 = conv3x3(inplanes, planes, stride)
|
||||||
|
self.bn1 = nn.BatchNorm2d(planes)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.conv2 = conv3x3(planes, planes)
|
||||||
|
self.bn2 = nn.BatchNorm2d(planes)
|
||||||
|
self.downsample = downsample
|
||||||
|
self.stride = stride
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
residual = x
|
||||||
|
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
|
||||||
|
if self.downsample is not None:
|
||||||
|
residual = self.downsample(x)
|
||||||
|
|
||||||
|
out += residual
|
||||||
|
out = self.relu(out)
|
||||||
|
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class Bottleneck(nn.Module):
|
||||||
|
expansion = 4
|
||||||
|
|
||||||
|
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
||||||
|
super(Bottleneck, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(planes)
|
||||||
|
self.conv2 = nn.Conv2d(planes,
|
||||||
|
planes,
|
||||||
|
kernel_size=3,
|
||||||
|
stride=stride,
|
||||||
|
padding=1,
|
||||||
|
bias=False)
|
||||||
|
self.bn2 = nn.BatchNorm2d(planes)
|
||||||
|
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
|
||||||
|
self.bn3 = nn.BatchNorm2d(planes * 4)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.downsample = downsample
|
||||||
|
self.stride = stride
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
residual = x
|
||||||
|
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
|
||||||
|
out = self.conv3(out)
|
||||||
|
out = self.bn3(out)
|
||||||
|
|
||||||
|
if self.downsample is not None:
|
||||||
|
residual = self.downsample(x)
|
||||||
|
|
||||||
|
out += residual
|
||||||
|
out = self.relu(out)
|
||||||
|
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class ResNet(nn.Module):
|
||||||
|
def __init__(self, block, layers, in_channels=1):
|
||||||
|
self.inplanes = 64
|
||||||
|
super(ResNet, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(64)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
||||||
|
self.layer1 = self._make_layer(block, 64, layers[0])
|
||||||
|
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
||||||
|
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
||||||
|
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
|
||||||
|
|
||||||
|
for m in self.modules():
|
||||||
|
if isinstance(m, nn.Conv2d):
|
||||||
|
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
||||||
|
m.weight.data.normal_(0, math.sqrt(2.0 / n))
|
||||||
|
elif isinstance(m, nn.BatchNorm2d):
|
||||||
|
m.weight.data.fill_(1)
|
||||||
|
m.bias.data.zero_()
|
||||||
|
|
||||||
|
def _make_layer(self, block, planes, blocks, stride=1):
|
||||||
|
downsample = None
|
||||||
|
if stride != 1 or self.inplanes != planes * block.expansion:
|
||||||
|
downsample = nn.Sequential(
|
||||||
|
nn.Conv2d(self.inplanes,
|
||||||
|
planes * block.expansion,
|
||||||
|
kernel_size=1,
|
||||||
|
stride=stride,
|
||||||
|
bias=False),
|
||||||
|
nn.BatchNorm2d(planes * block.expansion),
|
||||||
|
)
|
||||||
|
|
||||||
|
layers = []
|
||||||
|
layers.append(block(self.inplanes, planes, stride, downsample))
|
||||||
|
self.inplanes = planes * block.expansion
|
||||||
|
for i in range(1, blocks):
|
||||||
|
layers.append(block(self.inplanes, planes))
|
||||||
|
|
||||||
|
return nn.Sequential(*layers)
|
||||||
|
|
||||||
|
def _load_pretrained_model(self, model_url):
|
||||||
|
pretrain_dict = model_zoo.load_url(model_url)
|
||||||
|
model_dict = {}
|
||||||
|
state_dict = self.state_dict()
|
||||||
|
for k, v in pretrain_dict.items():
|
||||||
|
if k in state_dict:
|
||||||
|
model_dict[k] = v
|
||||||
|
state_dict.update(model_dict)
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
|
||||||
|
def forward(self, input):
|
||||||
|
x = self.conv1(input)
|
||||||
|
x = self.bn1(x)
|
||||||
|
x = self.relu(x)
|
||||||
|
c1 = self.maxpool(x)
|
||||||
|
c2 = self.layer1(c1)
|
||||||
|
c3 = self.layer2(c2)
|
||||||
|
c4 = self.layer3(c3)
|
||||||
|
c5 = self.layer4(c4)
|
||||||
|
return c1, c2, c3, c4, c5
|
||||||
|
|
||||||
|
|
||||||
|
def resnet18(pretrained=False, in_channels=1, **kwargs):
|
||||||
|
"""Constructs a ResNet-18 model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
"""
|
||||||
|
model = ResNet(BasicBlock, [2, 2, 2, 2], in_channels=in_channels, **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
model._load_pretrained_model(model_urls['resnet18'])
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def resnet34(pretrained=False, in_channels=1, **kwargs):
|
||||||
|
"""Constructs a ResNet-34 model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
"""
|
||||||
|
model = ResNet(BasicBlock, [3, 4, 6, 3], in_channels=in_channels, **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
model._load_pretrained_model(model_urls['resnet34'])
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def resnet50(pretrained=False, in_channels=1, **kwargs):
|
||||||
|
"""Constructs a ResNet-50 model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
"""
|
||||||
|
model = ResNet(Bottleneck, [3, 4, 6, 3], in_channels=in_channels, **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
model._load_pretrained_model(model_urls["resnet50"])
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def resnet101(pretrained=False, in_channels=1, **kwargs):
|
||||||
|
"""Constructs a ResNet-101 model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
"""
|
||||||
|
model = ResNet(Bottleneck, [3, 4, 23, 3], in_channels=in_channels, **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
model._load_pretrained_model(model_urls["resnet101"])
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def resnet152(pretrained=False, in_channels=1, **kwargs):
|
||||||
|
"""Constructs a ResNet-152 model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
"""
|
||||||
|
model = ResNet(Bottleneck, [3, 8, 36, 3], in_channels=in_channels, **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
model._load_pretrained_model(model_urls["resnet152"])
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
x = torch.zeros(8, 1, 640, 640)
|
||||||
|
net = resnet50()
|
||||||
|
print(net)
|
||||||
|
y = net(x)
|
||||||
|
print()
|
||||||
|
|
@ -0,0 +1,196 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
"""
|
||||||
|
VGG backbone
|
||||||
|
|
||||||
|
"""
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from typing import Union, List, Dict, Any, cast
|
||||||
|
|
||||||
|
from src.utils.vgg_utils import load_state_dict_from_url
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"VGG", "vgg11", "vgg11_bn", "vgg13", "vgg13_bn", "vgg16", "vgg16_bn",
|
||||||
|
"vgg19_bn", "vgg19",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
model_urls = {
|
||||||
|
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
|
||||||
|
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
|
||||||
|
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
|
||||||
|
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
|
||||||
|
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
|
||||||
|
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
|
||||||
|
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
|
||||||
|
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
class VGG(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
features: nn.Module,
|
||||||
|
num_classes: int = 1000,
|
||||||
|
init_weights: bool = True
|
||||||
|
) -> None:
|
||||||
|
super(VGG, self).__init__()
|
||||||
|
self.features = features
|
||||||
|
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
|
||||||
|
self.classifier = nn.Sequential(
|
||||||
|
nn.Linear(512 * 7 * 7, 4096),
|
||||||
|
nn.ReLU(True),
|
||||||
|
nn.Dropout(),
|
||||||
|
nn.Linear(4096, 4096),
|
||||||
|
nn.ReLU(True),
|
||||||
|
nn.Dropout(),
|
||||||
|
nn.Linear(4096, num_classes),
|
||||||
|
)
|
||||||
|
if init_weights:
|
||||||
|
self._initialize_weights()
|
||||||
|
|
||||||
|
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||||
|
x = self.features(x)
|
||||||
|
x = self.avgpool(x)
|
||||||
|
x = torch.flatten(x, 1)
|
||||||
|
x = self.classifier(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
def _initialize_weights(self) -> None:
|
||||||
|
for m in self.modules():
|
||||||
|
if isinstance(m, nn.Conv2d):
|
||||||
|
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
||||||
|
if m.bias is not None:
|
||||||
|
nn.init.constant_(m.bias, 0)
|
||||||
|
elif isinstance(m, nn.BatchNorm2d):
|
||||||
|
nn.init.constant_(m.weight, 1)
|
||||||
|
nn.init.constant_(m.bias, 0)
|
||||||
|
elif isinstance(m, nn.Linear):
|
||||||
|
nn.init.normal_(m.weight, 0, 0.01)
|
||||||
|
nn.init.constant_(m.bias, 0)
|
||||||
|
|
||||||
|
|
||||||
|
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
|
||||||
|
layers: List[nn.Module] = []
|
||||||
|
in_channels = 3
|
||||||
|
for v in cfg:
|
||||||
|
if v == 'M':
|
||||||
|
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
|
||||||
|
else:
|
||||||
|
v = cast(int, v)
|
||||||
|
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
|
||||||
|
if batch_norm:
|
||||||
|
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
|
||||||
|
else:
|
||||||
|
layers += [conv2d, nn.ReLU(inplace=True)]
|
||||||
|
in_channels = v
|
||||||
|
return nn.Sequential(*layers)
|
||||||
|
|
||||||
|
|
||||||
|
cfgs: Dict[str, List[Union[str, int]]] = {
|
||||||
|
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
|
||||||
|
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
|
||||||
|
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
|
||||||
|
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _vgg(arch: str, cfg: str, batch_norm: bool, pretrained: bool, progress: bool, **kwargs: Any) -> VGG:
|
||||||
|
if pretrained:
|
||||||
|
kwargs['init_weights'] = False
|
||||||
|
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
|
||||||
|
if pretrained:
|
||||||
|
state_dict = load_state_dict_from_url(model_urls[arch],
|
||||||
|
progress=progress)
|
||||||
|
model.load_state_dict(state_dict)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def vgg11(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 11-layer model (configuration "A") from
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg11_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 11-layer model (configuration "A") with batch normalization
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg11_bn', 'A', True, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg13(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 13-layer model (configuration "B")
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg13', 'B', False, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg13_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 13-layer model (configuration "B") with batch normalization
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg13_bn', 'B', True, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 16-layer model (configuration "D")
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg16_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 16-layer model (configuration "D") with batch normalization
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg19(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 19-layer model (configuration "E")
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg19', 'E', False, pretrained, progress, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def vgg19_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
|
||||||
|
r"""VGG 19-layer model (configuration 'E') with batch normalization
|
||||||
|
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
|
||||||
|
|
||||||
|
Args:
|
||||||
|
pretrained (bool): If True, returns a model pre-trained on ImageNet
|
||||||
|
progress (bool): If True, displays a progress bar of the download to stderr
|
||||||
|
"""
|
||||||
|
return _vgg('vgg19_bn', 'E', True, pretrained, progress, **kwargs)
|
||||||
|
|
@ -0,0 +1,217 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
from torch.nn import functional as F
|
||||||
|
|
||||||
|
from .backbone import *
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"FCN_VGG", "FCN_AlexNet", "FCN_ResNet18", "FCN_ResNet34",
|
||||||
|
"FCN_ResNet50", "FCN_ResNet101", "FCN_ResNet152",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class Conv3x3GNReLU(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels, upsample=False):
|
||||||
|
super().__init__()
|
||||||
|
self.upsample = upsample
|
||||||
|
self.block = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels, out_channels, (3, 3), stride=1, padding=1, bias=False),
|
||||||
|
nn.GroupNorm(32, out_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x, size):
|
||||||
|
if self.upsample:
|
||||||
|
x = F.interpolate(x, size=size, mode="bilinear", align_corners=True)
|
||||||
|
x = self.block(x)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class FCN_VGG(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, inter_channels=256, in_channels=1, bn=False):
|
||||||
|
super(FCN_VGG, self).__init__()
|
||||||
|
vgg = vgg16()
|
||||||
|
features, classifier = list(vgg.features.children()), list(vgg.classifier.children())
|
||||||
|
|
||||||
|
if in_channels != 3:
|
||||||
|
features[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
for f in features:
|
||||||
|
if 'MaxPool' in f.__class__.__name__:
|
||||||
|
f.ceil_mode = True
|
||||||
|
elif 'ReLU' in f.__class__.__name__:
|
||||||
|
f.inplace = True
|
||||||
|
|
||||||
|
features_temp = []
|
||||||
|
if not bn:
|
||||||
|
for i in range(len(features)):
|
||||||
|
features_temp.append(features[i])
|
||||||
|
if isinstance(features[i], nn.Conv2d):
|
||||||
|
features_temp.append(nn.GroupNorm(32, features[i].out_channels))
|
||||||
|
|
||||||
|
self.features3 = nn.Sequential(*features[:17])
|
||||||
|
self.features4 = nn.Sequential(*features[17: 24])
|
||||||
|
self.features5 = nn.Sequential(*features[24:])
|
||||||
|
|
||||||
|
self.score_pool3 = nn.Conv2d(256, inter_channels, kernel_size=1)
|
||||||
|
self.score_pool4 = nn.Conv2d(512, inter_channels, kernel_size=1)
|
||||||
|
|
||||||
|
fc6 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
|
||||||
|
fc7 = nn.Conv2d(512, 512, kernel_size=1)
|
||||||
|
score_fr = nn.Conv2d(512, inter_channels, kernel_size=1)
|
||||||
|
|
||||||
|
self.score_fr = nn.Sequential(
|
||||||
|
fc6, nn.ReLU(inplace=True), fc7, nn.ReLU(inplace=True), score_fr
|
||||||
|
)
|
||||||
|
self.upscore2 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.upscore_pool4 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.final_conv = nn.Conv2d(inter_channels, 1, kernel_size=1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
pool3 = self.features3(x)
|
||||||
|
pool4 = self.features4(pool3)
|
||||||
|
pool5 = self.features5(pool4)
|
||||||
|
|
||||||
|
score_fr = self.score_fr(pool5)
|
||||||
|
upscore2 = self.upscore2(score_fr, pool4.size()[-2:])
|
||||||
|
|
||||||
|
score_pool4 = self.score_pool4(pool4)
|
||||||
|
upscore_pool4 = self.upscore_pool4(score_pool4 + upscore2, pool3.size()[-2:])
|
||||||
|
|
||||||
|
score_pool3 = self.score_pool3(pool3)
|
||||||
|
upscore8 = F.interpolate(self.final_conv(score_pool3 + upscore_pool4), x.size()[-2:], mode='bilinear', align_corners=True)
|
||||||
|
return upscore8
|
||||||
|
|
||||||
|
|
||||||
|
class FCN_AlexNet(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, inter_channels=256, in_channels=1):
|
||||||
|
super(FCN_AlexNet, self).__init__()
|
||||||
|
self.alexnet = AlexNet(in_channels=in_channels)
|
||||||
|
|
||||||
|
self.score_pool3 = nn.Conv2d(64, inter_channels, kernel_size=1)
|
||||||
|
self.score_pool4 = nn.Conv2d(192, inter_channels, kernel_size=1)
|
||||||
|
|
||||||
|
fc6 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
|
||||||
|
fc7 = nn.Conv2d(512, 512, kernel_size=1)
|
||||||
|
score_fr = nn.Conv2d(512, inter_channels, kernel_size=1)
|
||||||
|
|
||||||
|
self.score_fr = nn.Sequential(
|
||||||
|
fc6, nn.ReLU(inplace=True), fc7, nn.ReLU(inplace=True), score_fr
|
||||||
|
)
|
||||||
|
self.upscore2 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.upscore_pool4 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.final_conv = nn.Conv2d(inter_channels, 1, kernel_size=1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
pool3 = self.alexnet.features3(x)
|
||||||
|
pool4 = self.alexnet.features4(pool3)
|
||||||
|
pool5 = self.alexnet.features5(pool4)
|
||||||
|
|
||||||
|
score_fr = self.score_fr(pool5)
|
||||||
|
upscore2 = self.upscore2(score_fr, pool4.size()[-2:])
|
||||||
|
|
||||||
|
score_pool4 = self.score_pool4(pool4)
|
||||||
|
upscore_pool4 = self.upscore_pool4(score_pool4 + upscore2, pool3.size()[-2:])
|
||||||
|
|
||||||
|
score_pool3 = self.score_pool3(pool3)
|
||||||
|
upscore8 = F.interpolate(self.final_conv(score_pool3 + upscore_pool4), x.size()[-2:],
|
||||||
|
mode='bilinear', align_corners=True)
|
||||||
|
return upscore8
|
||||||
|
|
||||||
|
|
||||||
|
class FCN_ResNet(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, backbone, inter_channels=256):
|
||||||
|
super(FCN_ResNet, self).__init__()
|
||||||
|
self.backbone = backbone
|
||||||
|
|
||||||
|
self.score_pool3 = nn.Conv2d(backbone.layer2[0].downsample[1].num_features,
|
||||||
|
inter_channels, kernel_size=1)
|
||||||
|
self.score_pool4 = nn.Conv2d(backbone.layer3[0].downsample[1].num_features,
|
||||||
|
inter_channels, kernel_size=1)
|
||||||
|
|
||||||
|
fc6 = nn.Conv2d(backbone.layer4[0].downsample[1].num_features,
|
||||||
|
512, kernel_size=3, padding=1)
|
||||||
|
fc7 = nn.Conv2d(512, 512, kernel_size=1)
|
||||||
|
score_fr = nn.Conv2d(512, inter_channels, kernel_size=1)
|
||||||
|
self.score_fr = nn.Sequential(
|
||||||
|
fc6, nn.ReLU(inplace=True), fc7, nn.ReLU(inplace=True), score_fr
|
||||||
|
)
|
||||||
|
self.upscore2 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.upscore_pool4 = Conv3x3GNReLU(inter_channels, inter_channels, upsample=True)
|
||||||
|
self.final_conv = nn.Conv2d(inter_channels, 1, kernel_size=1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
_, _, pool3, pool4, pool5 = self.backbone(x)
|
||||||
|
|
||||||
|
score_fr = self.score_fr(pool5)
|
||||||
|
upscore2 = self.upscore2(score_fr, pool4.size()[-2:])
|
||||||
|
|
||||||
|
score_pool4 = self.score_pool4(pool4)
|
||||||
|
upscore_pool4 = self.upscore_pool4(score_pool4 + upscore2, pool3.size()[-2:])
|
||||||
|
|
||||||
|
score_pool3 = self.score_pool3(pool3)
|
||||||
|
upscore8 = F.interpolate(self.final_conv(score_pool3 + upscore_pool4), x.size()[-2:], mode='bilinear', align_corners=True)
|
||||||
|
return upscore8
|
||||||
|
|
||||||
|
|
||||||
|
def FCN_ResNet18(in_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Constructs FCN based on ResNet18 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet18(in_channels=in_channels)
|
||||||
|
model = FCN_ResNet(backbone_net, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FCN_ResNet34(in_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Constructs FCN based on ResNet18 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet34(in_channels=in_channels)
|
||||||
|
model = FCN_ResNet(backbone_net, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FCN_ResNet50(in_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Constructs FCN based on ResNet50 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet50(in_channels=in_channels)
|
||||||
|
model = FCN_ResNet(backbone_net, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FCN_ResNet101(in_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Constructs FCN based on ResNet101 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet101(in_channels=in_channels)
|
||||||
|
model = FCN_ResNet(backbone_net, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FCN_ResNet152(in_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Constructs FCN based on ResNet18 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet152(in_channels=in_channels)
|
||||||
|
model = FCN_ResNet(backbone_net, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
model = FCN_AlexNet(in_channels=1, inter_channels=128)
|
||||||
|
x = torch.randn(1, 1, 200, 200)
|
||||||
|
with torch.no_grad():
|
||||||
|
y = model(x)
|
||||||
|
print(y.shape)
|
||||||
|
|
@ -0,0 +1,170 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from src.utils.model_init import weights_init
|
||||||
|
from .backbone import *
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["FPN_ResNet18", "FPN_ResNet34", "FPN_ResNet50", "FPN_ResNet101", "FPN_ResNet152"]
|
||||||
|
|
||||||
|
|
||||||
|
class Conv3x3GNReLU(nn.Module):
|
||||||
|
def __init__(self, in_channels, out_channels, upsample=False):
|
||||||
|
super().__init__()
|
||||||
|
self.upsample = upsample
|
||||||
|
self.block = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels, out_channels, (3, 3), stride=1, padding=1, bias=False),
|
||||||
|
nn.GroupNorm(32, out_channels),
|
||||||
|
# nn.BatchNorm2d(out_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x, size):
|
||||||
|
x = self.block(x)
|
||||||
|
if self.upsample:
|
||||||
|
x = F.interpolate(x, size=size, mode="bilinear", align_corners=True)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class FPNBlock(nn.Module):
|
||||||
|
def __init__(self, pyramid_channels, skip_channels):
|
||||||
|
super().__init__()
|
||||||
|
self.skip_conv = nn.Conv2d(skip_channels, pyramid_channels, kernel_size=1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x, skip = x
|
||||||
|
x = F.interpolate(x, size=skip.size()[-2:], mode="bilinear", align_corners=True)
|
||||||
|
skip = self.skip_conv(skip)
|
||||||
|
|
||||||
|
x = x + skip
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class SegmentationBlock(nn.Module):
|
||||||
|
def __init__(self, in_channels, out_channels, n_upsamples=0):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
self.blocks = [Conv3x3GNReLU(in_channels, out_channels, upsample=bool(n_upsamples))]
|
||||||
|
|
||||||
|
if n_upsamples > 1:
|
||||||
|
for _ in range(1, n_upsamples):
|
||||||
|
self.blocks.append(Conv3x3GNReLU(out_channels, out_channels, upsample=True))
|
||||||
|
|
||||||
|
self.blocks_name = []
|
||||||
|
for i, block in enumerate(self.blocks):
|
||||||
|
self.add_module("Block_{}".format(i), block)
|
||||||
|
self.blocks_name.append("Block_{}".format(i))
|
||||||
|
|
||||||
|
def forward(self, x, sizes=[]):
|
||||||
|
for i, block_name in enumerate(self.blocks_name):
|
||||||
|
x = getattr(self, block_name)(x, sizes[i])
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class FPN_ResNet(nn.Module):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
backbone,
|
||||||
|
encoder_channels,
|
||||||
|
pyramid_channels=256,
|
||||||
|
segmentation_channels=128,
|
||||||
|
final_upsampling=4,
|
||||||
|
final_channels=1,
|
||||||
|
dropout=0.2,
|
||||||
|
):
|
||||||
|
super().__init__()
|
||||||
|
self.backbone = backbone
|
||||||
|
self.backbone.apply(weights_init)
|
||||||
|
self.final_upsampling = final_upsampling
|
||||||
|
self.conv1 = nn.Conv2d(encoder_channels[0],
|
||||||
|
pyramid_channels,
|
||||||
|
kernel_size=(1, 1))
|
||||||
|
|
||||||
|
self.p4 = FPNBlock(pyramid_channels, encoder_channels[1])
|
||||||
|
self.p3 = FPNBlock(pyramid_channels, encoder_channels[2])
|
||||||
|
self.p2 = FPNBlock(pyramid_channels, encoder_channels[3])
|
||||||
|
|
||||||
|
self.s5 = SegmentationBlock(pyramid_channels,
|
||||||
|
segmentation_channels,
|
||||||
|
n_upsamples=3)
|
||||||
|
self.s4 = SegmentationBlock(pyramid_channels,
|
||||||
|
segmentation_channels,
|
||||||
|
n_upsamples=2)
|
||||||
|
self.s3 = SegmentationBlock(pyramid_channels,
|
||||||
|
segmentation_channels,
|
||||||
|
n_upsamples=1)
|
||||||
|
self.s2 = SegmentationBlock(pyramid_channels,
|
||||||
|
segmentation_channels,
|
||||||
|
n_upsamples=0)
|
||||||
|
|
||||||
|
self.dropout = nn.Dropout2d(p=dropout, inplace=True)
|
||||||
|
self.final_conv = nn.Conv2d(segmentation_channels,
|
||||||
|
final_channels,
|
||||||
|
kernel_size=1,
|
||||||
|
padding=0)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.backbone(x)
|
||||||
|
|
||||||
|
_, c2, c3, c4, c5 = x
|
||||||
|
|
||||||
|
p5 = self.conv1(c5)
|
||||||
|
p4 = self.p4([p5, c4])
|
||||||
|
p3 = self.p3([p4, c3])
|
||||||
|
p2 = self.p2([p3, c2])
|
||||||
|
|
||||||
|
s5 = self.s5(p5, sizes=[c4.size()[-2:], c3.size()[-2:], c2.size()[-2:]])
|
||||||
|
s4 = self.s4(p4, sizes=[c3.size()[-2:], c2.size()[-2:]])
|
||||||
|
s3 = self.s3(p3, sizes=[c2.size()[-2:]])
|
||||||
|
s2 = self.s2(p2, sizes=[c2.size()[-2:]])
|
||||||
|
|
||||||
|
# x = torch.cat([s5, s4, s3, s2], dim=1)
|
||||||
|
x = s5 + s4 + s3 + s2
|
||||||
|
|
||||||
|
x = self.dropout(x)
|
||||||
|
x = self.final_conv(x)
|
||||||
|
|
||||||
|
if self.final_upsampling is not None and self.final_upsampling > 1:
|
||||||
|
x = F.interpolate(x, scale_factor=self.final_upsampling, mode="bilinear", align_corners=True)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
def FPN_ResNet18(in_channels=1, **kwargs):
|
||||||
|
"""FPN with ResNet18 as backbone
|
||||||
|
"""
|
||||||
|
backbone = resnet18(in_channels=in_channels)
|
||||||
|
model = FPN_ResNet(backbone, encoder_channels=[512, 256, 128, 64], **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FPN_ResNet34(in_channels=1, **kwargs):
|
||||||
|
"""FPN with ResNet18 as backbone
|
||||||
|
"""
|
||||||
|
backbone = resnet34(in_channels=in_channels)
|
||||||
|
model = FPN_ResNet(backbone, encoder_channels=[512, 256, 128, 64], **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FPN_ResNet50(in_channels=1, **kwargs):
|
||||||
|
"""FPN with ResNet50 as backbone
|
||||||
|
"""
|
||||||
|
backbone = resnet50(in_channels=in_channels)
|
||||||
|
model = FPN_ResNet(backbone, encoder_channels=[2048, 1024, 512, 256], **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FPN_ResNet101(in_channels=1, **kwargs):
|
||||||
|
"""FPN with ResNet101 as backbone
|
||||||
|
"""
|
||||||
|
backbone = resnet101(in_channels=in_channels)
|
||||||
|
model = FPN_ResNet(backbone, encoder_channels=[2048, 1024, 512, 256], **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def FPN_ResNet152(in_channels=1, **kwargs):
|
||||||
|
"""FPN with ResNet101 as backbone
|
||||||
|
"""
|
||||||
|
backbone = resnet152(in_channels=in_channels)
|
||||||
|
model = FPN_ResNet(backbone, encoder_channels=[2048, 1024, 512, 256], **kwargs)
|
||||||
|
return model
|
||||||
|
|
@ -0,0 +1,550 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
from math import ceil
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from .backbone import *
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["SegNet_VGG", "SegNet_VGG_GN", "SegNet_AlexNet", "SegNet_ResNet18",
|
||||||
|
"SegNet_ResNet50", "SegNet_ResNet101", "SegNet_ResNet34", "SegNet_ResNet152"]
|
||||||
|
|
||||||
|
|
||||||
|
# required class for decoder of SegNet_ResNet
|
||||||
|
class DecoderBottleneck(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(DecoderBottleneck, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(in_channels, in_channels // 4,
|
||||||
|
kernel_size=1, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(in_channels // 4)
|
||||||
|
self.conv2 = nn.ConvTranspose2d(in_channels // 4, in_channels // 4,
|
||||||
|
kernel_size=2, stride=2, bias=False)
|
||||||
|
self.bn2 = nn.BatchNorm2d(in_channels // 4)
|
||||||
|
self.conv3 = nn.Conv2d(in_channels // 4, in_channels // 2, 1, bias=False)
|
||||||
|
self.bn3 = nn.BatchNorm2d(in_channels // 2)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.downsample = nn.Sequential(
|
||||||
|
nn.ConvTranspose2d(in_channels, in_channels // 2,
|
||||||
|
kernel_size=2, stride=2, bias=False),
|
||||||
|
nn.BatchNorm2d(in_channels // 2))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv3(out)
|
||||||
|
out = self.bn3(out)
|
||||||
|
|
||||||
|
identity = self.downsample(x)
|
||||||
|
out += identity
|
||||||
|
out = self.relu(out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
# required class for decoder of SegNet_ResNet
|
||||||
|
class LastBottleneck(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(LastBottleneck, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(in_channels, in_channels // 4,
|
||||||
|
kernel_size=1, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(in_channels // 4)
|
||||||
|
self.conv2 = nn.Conv2d(in_channels // 4, in_channels // 4,
|
||||||
|
kernel_size=3, padding=1, bias=False)
|
||||||
|
self.bn2 = nn.BatchNorm2d(in_channels // 4)
|
||||||
|
self.conv3 = nn.Conv2d(in_channels // 4, in_channels // 4, 1, bias=False)
|
||||||
|
self.bn3 = nn.BatchNorm2d(in_channels // 4)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.downsample = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels, in_channels // 4, kernel_size=1, bias=False),
|
||||||
|
nn.BatchNorm2d(in_channels // 4))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv3(out)
|
||||||
|
out = self.bn3(out)
|
||||||
|
|
||||||
|
identity = self.downsample(x)
|
||||||
|
out += identity
|
||||||
|
out = self.relu(out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
# required class for decoder of SegNet_ResNet
|
||||||
|
class DecoderBasicBlock(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(DecoderBasicBlock, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(in_channels, in_channels // 2,
|
||||||
|
kernel_size=3, padding=1, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(in_channels // 2)
|
||||||
|
self.conv2 = nn.ConvTranspose2d(in_channels // 2, in_channels // 2,
|
||||||
|
kernel_size=2, stride=2, bias=False)
|
||||||
|
self.bn2 = nn.BatchNorm2d(in_channels // 2)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.downsample = nn.Sequential(
|
||||||
|
nn.ConvTranspose2d(in_channels, in_channels // 2,
|
||||||
|
kernel_size=2, stride=2, bias=False),
|
||||||
|
nn.BatchNorm2d(in_channels // 2))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
|
||||||
|
identity = self.downsample(x)
|
||||||
|
out += identity
|
||||||
|
out = self.relu(out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class LastBasicBlock(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(LastBasicBlock, self).__init__()
|
||||||
|
self.conv1 = nn.Conv2d(in_channels, in_channels,
|
||||||
|
kernel_size=3, padding=1, bias=False)
|
||||||
|
self.bn1 = nn.BatchNorm2d(in_channels)
|
||||||
|
self.conv2 = nn.Conv2d(in_channels, in_channels,
|
||||||
|
kernel_size=3, padding=1, bias=False)
|
||||||
|
self.bn2 = nn.BatchNorm2d(in_channels)
|
||||||
|
self.relu = nn.ReLU(inplace=True)
|
||||||
|
self.downsample = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels, in_channels, kernel_size=1, bias=False),
|
||||||
|
nn.BatchNorm2d(in_channels))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
out = self.conv1(x)
|
||||||
|
out = self.bn1(out)
|
||||||
|
out = self.relu(out)
|
||||||
|
out = self.conv2(out)
|
||||||
|
out = self.bn2(out)
|
||||||
|
|
||||||
|
identity = self.downsample(x)
|
||||||
|
out += identity
|
||||||
|
out = self.relu(out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class SegNet_VGG(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_channels=1, in_channels=1, pretrained=False):
|
||||||
|
super(SegNet_VGG, self).__init__()
|
||||||
|
vgg_bn = vgg16_bn(pretrained=pretrained)
|
||||||
|
encoder = list(vgg_bn.features.children())
|
||||||
|
|
||||||
|
# Adjust the input size
|
||||||
|
if in_channels != 3:
|
||||||
|
encoder[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
|
||||||
|
# Encoder, VGG without any maxpooling
|
||||||
|
self.stage1_encoder = nn.Sequential(*encoder[:6])
|
||||||
|
self.stage2_encoder = nn.Sequential(*encoder[7:13])
|
||||||
|
self.stage3_encoder = nn.Sequential(*encoder[14:23])
|
||||||
|
self.stage4_encoder = nn.Sequential(*encoder[24:33])
|
||||||
|
self.stage5_encoder = nn.Sequential(*encoder[34:-1])
|
||||||
|
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
|
||||||
|
|
||||||
|
# Decoder, same as the encoder but reversed, maxpool will not be used
|
||||||
|
decoder = encoder
|
||||||
|
decoder = [i for i in list(reversed(decoder)) if not isinstance(i, nn.MaxPool2d)]
|
||||||
|
# Replace the last conv layer
|
||||||
|
decoder[-1] = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
# When reversing, we also reversed conv->batchN->relu, correct it
|
||||||
|
decoder = [item for i in range(0, len(decoder), 3)
|
||||||
|
for item in decoder[i:i + 3][::-1]]
|
||||||
|
# Replace some conv layers & batchN after them
|
||||||
|
for i, module in enumerate(decoder):
|
||||||
|
if isinstance(module, nn.Conv2d):
|
||||||
|
if module.in_channels != module.out_channels:
|
||||||
|
decoder[i + 1] = nn.BatchNorm2d(module.in_channels)
|
||||||
|
decoder[i] = nn.Conv2d(module.out_channels, module.in_channels,
|
||||||
|
kernel_size=3, stride=1, padding=1)
|
||||||
|
|
||||||
|
self.stage1_decoder = nn.Sequential(*decoder[0:9])
|
||||||
|
self.stage2_decoder = nn.Sequential(*decoder[9:18])
|
||||||
|
self.stage3_decoder = nn.Sequential(*decoder[18:27])
|
||||||
|
self.stage4_decoder = nn.Sequential(*decoder[27:33])
|
||||||
|
self.stage5_decoder = nn.Sequential(*decoder[33:],
|
||||||
|
nn.Conv2d(64, out_channels,
|
||||||
|
kernel_size=3,
|
||||||
|
stride=1,
|
||||||
|
padding=1)
|
||||||
|
)
|
||||||
|
self.unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
|
||||||
|
|
||||||
|
self._initialize_weights(self.stage1_decoder, self.stage2_decoder, self.stage3_decoder,
|
||||||
|
self.stage4_decoder, self.stage5_decoder)
|
||||||
|
|
||||||
|
def _initialize_weights(self, *stages):
|
||||||
|
for modules in stages:
|
||||||
|
for module in modules.modules():
|
||||||
|
if isinstance(module, nn.Conv2d):
|
||||||
|
nn.init.kaiming_normal_(module.weight)
|
||||||
|
if module.bias is not None:
|
||||||
|
module.bias.data.zero_()
|
||||||
|
elif isinstance(module, nn.BatchNorm2d):
|
||||||
|
module.weight.data.fill_(1)
|
||||||
|
module.bias.data.zero_()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
# Encoder
|
||||||
|
x = self.stage1_encoder(x)
|
||||||
|
x1_size = x.size()
|
||||||
|
x, indices1 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage2_encoder(x)
|
||||||
|
x2_size = x.size()
|
||||||
|
x, indices2 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage3_encoder(x)
|
||||||
|
x3_size = x.size()
|
||||||
|
x, indices3 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage4_encoder(x)
|
||||||
|
x4_size = x.size()
|
||||||
|
x, indices4 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage5_encoder(x)
|
||||||
|
x5_size = x.size()
|
||||||
|
x, indices5 = self.pool(x)
|
||||||
|
|
||||||
|
# Decoder
|
||||||
|
x = self.unpool(x, indices=indices5, output_size=x5_size)
|
||||||
|
x = self.stage1_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices4, output_size=x4_size)
|
||||||
|
x = self.stage2_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices3, output_size=x3_size)
|
||||||
|
x = self.stage3_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices2, output_size=x2_size)
|
||||||
|
x = self.stage4_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices1, output_size=x1_size)
|
||||||
|
x = self.stage5_decoder(x)
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class SegNet_VGG_GN(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_channels=1, in_channels=3, pretrained=False):
|
||||||
|
super(SegNet_VGG_GN, self).__init__()
|
||||||
|
vgg_bn = vgg16_bn(pretrained=pretrained)
|
||||||
|
encoder = list(vgg_bn.features.children())
|
||||||
|
|
||||||
|
# Adjust the input size
|
||||||
|
if in_channels != 3:
|
||||||
|
encoder[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
|
||||||
|
#
|
||||||
|
for i in range(len(encoder)):
|
||||||
|
if isinstance(encoder[i], nn.BatchNorm2d):
|
||||||
|
encoder[i] = nn.GroupNorm(32, encoder[i].num_features)
|
||||||
|
|
||||||
|
# Encoder, VGG without any maxpooling
|
||||||
|
self.stage1_encoder = nn.Sequential(*encoder[:6])
|
||||||
|
self.stage2_encoder = nn.Sequential(*encoder[7:13])
|
||||||
|
self.stage3_encoder = nn.Sequential(*encoder[14:23])
|
||||||
|
self.stage4_encoder = nn.Sequential(*encoder[24:33])
|
||||||
|
self.stage5_encoder = nn.Sequential(*encoder[34:-1])
|
||||||
|
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
|
||||||
|
|
||||||
|
# Decoder, same as the encoder but reversed, maxpool will not be used
|
||||||
|
decoder = encoder
|
||||||
|
decoder = [i for i in list(reversed(decoder)) if not isinstance(i, nn.MaxPool2d)]
|
||||||
|
# Replace the last conv layer
|
||||||
|
decoder[-1] = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
# When reversing, we also reversed conv->batchN->relu, correct it
|
||||||
|
decoder = [item for i in range(0, len(decoder), 3)
|
||||||
|
for item in decoder[i:i + 3][::-1]]
|
||||||
|
# Replace some conv layers & batchN after them
|
||||||
|
for i, module in enumerate(decoder):
|
||||||
|
if isinstance(module, nn.Conv2d):
|
||||||
|
if module.in_channels != module.out_channels:
|
||||||
|
decoder[i + 1] = nn.GroupNorm(32, module.in_channels)
|
||||||
|
decoder[i] = nn.Conv2d(module.out_channels, module.in_channels,
|
||||||
|
kernel_size=3, stride=1, padding=1)
|
||||||
|
|
||||||
|
self.stage1_decoder = nn.Sequential(*decoder[0:9])
|
||||||
|
self.stage2_decoder = nn.Sequential(*decoder[9:18])
|
||||||
|
self.stage3_decoder = nn.Sequential(*decoder[18:27])
|
||||||
|
self.stage4_decoder = nn.Sequential(*decoder[27:33])
|
||||||
|
self.stage5_decoder = nn.Sequential(*decoder[33:], nn.Conv2d(64,
|
||||||
|
out_channels,
|
||||||
|
kernel_size=3,
|
||||||
|
stride=1,
|
||||||
|
padding=1))
|
||||||
|
self.unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
|
||||||
|
|
||||||
|
self._initialize_weights(self.stage1_decoder, self.stage2_decoder, self.stage3_decoder,
|
||||||
|
self.stage4_decoder, self.stage5_decoder)
|
||||||
|
|
||||||
|
def _initialize_weights(self, *stages):
|
||||||
|
for modules in stages:
|
||||||
|
for module in modules.modules():
|
||||||
|
if isinstance(module, nn.Conv2d):
|
||||||
|
nn.init.kaiming_normal_(module.weight)
|
||||||
|
if module.bias is not None:
|
||||||
|
module.bias.data.zero_()
|
||||||
|
elif isinstance(module, nn.BatchNorm2d):
|
||||||
|
module.weight.data.fill_(1)
|
||||||
|
module.bias.data.zero_()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
# Encoder
|
||||||
|
x = self.stage1_encoder(x)
|
||||||
|
x1_size = x.size()
|
||||||
|
x, indices1 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage2_encoder(x)
|
||||||
|
x2_size = x.size()
|
||||||
|
x, indices2 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage3_encoder(x)
|
||||||
|
x3_size = x.size()
|
||||||
|
x, indices3 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage4_encoder(x)
|
||||||
|
x4_size = x.size()
|
||||||
|
x, indices4 = self.pool(x)
|
||||||
|
|
||||||
|
x = self.stage5_encoder(x)
|
||||||
|
x5_size = x.size()
|
||||||
|
x, indices5 = self.pool(x)
|
||||||
|
|
||||||
|
# Decoder
|
||||||
|
x = self.unpool(x, indices=indices5, output_size=x5_size)
|
||||||
|
x = self.stage1_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices4, output_size=x4_size)
|
||||||
|
x = self.stage2_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices3, output_size=x3_size)
|
||||||
|
x = self.stage3_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices2, output_size=x2_size)
|
||||||
|
x = self.stage4_decoder(x)
|
||||||
|
|
||||||
|
x = self.unpool(x, indices=indices1, output_size=x1_size)
|
||||||
|
x = self.stage5_decoder(x)
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class SegNet_AlexNet(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_channels=1, in_channels=1, bn=False):
|
||||||
|
super(SegNet_AlexNet, self).__init__()
|
||||||
|
self.stage3_encoder = nn.Sequential(
|
||||||
|
# kernel(11, 11) -> kernel(7, 7)
|
||||||
|
nn.Conv2d(in_channels, 64, kernel_size=7, stride=4, padding=3),
|
||||||
|
nn.BatchNorm2d(64) if bn else nn.GroupNorm(32, 64),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
# padding=0 -> padding=1
|
||||||
|
)
|
||||||
|
self.stage4_encoder = nn.Sequential(
|
||||||
|
nn.Conv2d(64, 192, kernel_size=5, padding=2),
|
||||||
|
nn.BatchNorm2d(192) if bn else nn.GroupNorm(32, 192),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.stage5_encoder = nn.Sequential(
|
||||||
|
nn.Conv2d(192, 384, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(384) if bn else nn.GroupNorm(32, 384),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(384, 256, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(256) if bn else nn.GroupNorm(32, 256),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(256, 256, kernel_size=3, padding=1),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=False, return_indices=True)
|
||||||
|
self.unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
|
||||||
|
self.stage5_decoder = nn.Sequential(
|
||||||
|
nn.Conv2d(256, 256, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(256) if bn else nn.GroupNorm(32, 256),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(256, 384, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(384) if bn else nn.GroupNorm(32, 384),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(384, 192, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(192) if bn else nn.GroupNorm(32, 192),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.stage4_decoder = nn.Sequential(
|
||||||
|
nn.Conv2d(192, 64, kernel_size=5, padding=2),
|
||||||
|
nn.BatchNorm2d(64) if bn else nn.GroupNorm(32, 64),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.stage3_decoder = nn.Sequential(
|
||||||
|
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2, bias=False),
|
||||||
|
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2, bias=False),
|
||||||
|
nn.Conv2d(64, out_channels, kernel_size=7, stride=1, padding=3),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x3 = self.stage3_encoder(x)
|
||||||
|
x3_size = x3.size()
|
||||||
|
x3, indices3 = self.maxpool(x3)
|
||||||
|
x4 = self.stage4_encoder(x3)
|
||||||
|
x4_size = x4.size()
|
||||||
|
x4, indices4 = self.maxpool(x4)
|
||||||
|
x5 = self.stage5_encoder(x4)
|
||||||
|
x5_size = x5.size()
|
||||||
|
x5, indices5 = self.maxpool(x5)
|
||||||
|
|
||||||
|
out = self.unpool(x5, indices=indices5, output_size=x5_size)
|
||||||
|
out = self.stage5_decoder(out)
|
||||||
|
out = self.unpool(out, indices=indices4, output_size=x4_size)
|
||||||
|
out = self.stage4_decoder(out)
|
||||||
|
out = self.unpool(out, indices=indices3, output_size=x3_size)
|
||||||
|
out = self.stage3_decoder(out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class SegNet_ResNet(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, backbone, out_channels=1, is_bottleneck=False, in_channels=1):
|
||||||
|
super(SegNet_ResNet, self).__init__()
|
||||||
|
resnet_backbone = backbone
|
||||||
|
encoder = list(resnet_backbone.children())
|
||||||
|
if in_channels != 3:
|
||||||
|
encoder[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
|
||||||
|
encoder[3].return_indices = True
|
||||||
|
|
||||||
|
# Encoder
|
||||||
|
self.first_conv = nn.Sequential(*encoder[:4])
|
||||||
|
resnet_blocks = list(resnet_backbone.children())[4:]
|
||||||
|
self.encoder = nn.Sequential(*resnet_blocks)
|
||||||
|
|
||||||
|
# Decoder
|
||||||
|
resnet_r_blocks = list(resnet_backbone.children())[4:][::-1]
|
||||||
|
decoder = []
|
||||||
|
if is_bottleneck:
|
||||||
|
channels = (2048, 1024, 512)
|
||||||
|
else:
|
||||||
|
channels = (512, 256, 128)
|
||||||
|
for i, block in enumerate(resnet_r_blocks[:-1]):
|
||||||
|
new_block = list(block.children())[::-1][:-1]
|
||||||
|
decoder.append(nn.Sequential(*new_block,
|
||||||
|
DecoderBottleneck(channels[i])
|
||||||
|
if is_bottleneck else DecoderBasicBlock(channels[i])))
|
||||||
|
new_block = list(resnet_r_blocks[-1].children())[::-1][:-1]
|
||||||
|
decoder.append(nn.Sequential(*new_block,
|
||||||
|
LastBottleneck(256)
|
||||||
|
if is_bottleneck else LastBasicBlock(64)))
|
||||||
|
|
||||||
|
self.decoder = nn.Sequential(*decoder)
|
||||||
|
self.last_conv = nn.Sequential(
|
||||||
|
nn.ConvTranspose2d(64, 64, kernel_size=2, stride=2, bias=False),
|
||||||
|
nn.Conv2d(64, out_channels, kernel_size=3, stride=1, padding=1)
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
inputsize = x.size()
|
||||||
|
|
||||||
|
# Encoder
|
||||||
|
x, indices = self.first_conv(x)
|
||||||
|
x = self.encoder(x)
|
||||||
|
|
||||||
|
# Decoder
|
||||||
|
x = self.decoder(x)
|
||||||
|
h_diff = ceil((x.size()[2] - indices.size()[2]) / 2)
|
||||||
|
w_diff = ceil((x.size()[3] - indices.size()[3]) / 2)
|
||||||
|
if indices.size()[2] % 2 == 1:
|
||||||
|
x = x[:, :, h_diff:x.size()[2] - (h_diff - 1),
|
||||||
|
w_diff: x.size()[3] - (w_diff - 1)]
|
||||||
|
else:
|
||||||
|
x = x[:, :, h_diff:x.size()[2] - h_diff, w_diff: x.size()[3] - w_diff]
|
||||||
|
|
||||||
|
x = F.max_unpool2d(x, indices, kernel_size=2, stride=2)
|
||||||
|
x = self.last_conv(x)
|
||||||
|
|
||||||
|
if inputsize != x.size():
|
||||||
|
h_diff = (x.size()[2] - inputsize[2]) // 2
|
||||||
|
w_diff = (x.size()[3] - inputsize[3]) // 2
|
||||||
|
x = x[:, :, h_diff:x.size()[2] - h_diff, w_diff: x.size()[3] - w_diff]
|
||||||
|
if h_diff % 2 != 0: x = x[:, :, :-1, :]
|
||||||
|
if w_diff % 2 != 0: x = x[:, :, :, :-1]
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
def SegNet_ResNet18(in_channels=1, out_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct SegNet based on ResNet18 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet18()
|
||||||
|
model = SegNet_ResNet(backbone_net, out_channels=out_channels, is_bottleneck=False,
|
||||||
|
in_channels=in_channels, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def SegNet_ResNet34(in_channels=1, out_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct SegNet based on ResNet18 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet34()
|
||||||
|
model = SegNet_ResNet(backbone_net, out_channels=out_channels, is_bottleneck=False,
|
||||||
|
in_channels=in_channels, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def SegNet_ResNet50(in_channels=1, out_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct SegNet based on ResNet50 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet50()
|
||||||
|
model = SegNet_ResNet(backbone_net, out_channels=out_channels, is_bottleneck=True,
|
||||||
|
in_channels=in_channels, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def SegNet_ResNet101(in_channels=1, out_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct SegNet based on ResNet101 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet101()
|
||||||
|
model = SegNet_ResNet(backbone_net, out_channels=out_channels, is_bottleneck=True,
|
||||||
|
in_channels=in_channels, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def SegNet_ResNet152(in_channels=1, out_channels=1, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct SegNet based on ResNet101 model.
|
||||||
|
|
||||||
|
"""
|
||||||
|
backbone_net = resnet101()
|
||||||
|
model = SegNet_ResNet(backbone_net, out_channels=out_channels, is_bottleneck=True,
|
||||||
|
in_channels=in_channels, **kwargs)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
model = SegNet_AlexNet(in_channels=1, out_channels=1)
|
||||||
|
print(model)
|
||||||
|
x = torch.randn(1, 1, 200, 200)
|
||||||
|
with torch.no_grad():
|
||||||
|
y = model(x)
|
||||||
|
print(y.shape)
|
||||||
|
|
@ -0,0 +1,100 @@
|
||||||
|
# encoding: utf-8
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from torch import nn
|
||||||
|
|
||||||
|
from src.utils.unet_initialize import initialize_weights
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["UNet_VGG"]
|
||||||
|
|
||||||
|
|
||||||
|
class _EncoderBlock(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels, dropout=False, polling=True, bn=False):
|
||||||
|
super(_EncoderBlock, self).__init__()
|
||||||
|
layers = [
|
||||||
|
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(out_channels) if bn else nn.GroupNorm(32, out_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(out_channels) if bn else nn.GroupNorm(32, out_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
]
|
||||||
|
if dropout:
|
||||||
|
layers.append(nn.Dropout())
|
||||||
|
self.encode = nn.Sequential(*layers)
|
||||||
|
self.pool = None
|
||||||
|
if polling:
|
||||||
|
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
if self.pool is not None:
|
||||||
|
x = self.pool(x)
|
||||||
|
return self.encode(x)
|
||||||
|
|
||||||
|
|
||||||
|
class _DecoderBlock(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_channels, middle_channels, out_channels, bn=False):
|
||||||
|
super(_DecoderBlock, self).__init__()
|
||||||
|
self.decode = nn.Sequential(
|
||||||
|
nn.Conv2d(in_channels, middle_channels, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(middle_channels) if bn else nn.GroupNorm(32, middle_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(middle_channels, middle_channels, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(middle_channels) if bn else nn.GroupNorm(32, middle_channels),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.ConvTranspose2d(middle_channels, out_channels, kernel_size=2, stride=2),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.decode(x)
|
||||||
|
|
||||||
|
|
||||||
|
class UNet_VGG(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_channels=1, in_channels=1, bn=False):
|
||||||
|
super(UNet_VGG, self).__init__()
|
||||||
|
self.enc1 = _EncoderBlock(in_channels, 64, polling=False, bn=bn)
|
||||||
|
self.enc2 = _EncoderBlock(64, 128, bn=bn)
|
||||||
|
self.enc3 = _EncoderBlock(128, 256, bn=bn)
|
||||||
|
self.enc4 = _EncoderBlock(256, 512, bn=bn)
|
||||||
|
self.polling = nn.MaxPool2d(kernel_size=2, stride=2)
|
||||||
|
self.center = _DecoderBlock(512, 1024, 512, bn=bn)
|
||||||
|
self.dec4 = _DecoderBlock(1024, 512, 256, bn=bn)
|
||||||
|
self.dec3 = _DecoderBlock(512, 256, 128, bn=bn)
|
||||||
|
self.dec2 = _DecoderBlock(256, 128, 64, bn=bn)
|
||||||
|
self.dec1 = nn.Sequential(
|
||||||
|
nn.Conv2d(128, 64, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(64) if bn else nn.GroupNorm(32, 64),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Conv2d(64, 64, kernel_size=3, padding=1),
|
||||||
|
nn.BatchNorm2d(64) if bn else nn.GroupNorm(32, 64),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
)
|
||||||
|
self.final = nn.Conv2d(64, out_channels, kernel_size=1)
|
||||||
|
initialize_weights(self)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
enc1 = self.enc1(x)
|
||||||
|
enc2 = self.enc2(enc1)
|
||||||
|
enc3 = self.enc3(enc2)
|
||||||
|
enc4 = self.enc4(enc3)
|
||||||
|
center = self.center(self.polling(enc4))
|
||||||
|
dec4 = self.dec4(torch.cat([F.interpolate(center, enc4.size()[-2:], mode='bilinear',
|
||||||
|
align_corners=True), enc4], 1))
|
||||||
|
dec3 = self.dec3(torch.cat([dec4, enc3], 1))
|
||||||
|
dec2 = self.dec2(torch.cat([dec3, enc2], 1))
|
||||||
|
dec1 = self.dec1(torch.cat([dec2, enc1], 1))
|
||||||
|
final = self.final(dec1)
|
||||||
|
return final
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
model = UNet(in_channels=1, out_channels=1)
|
||||||
|
print(model)
|
||||||
|
x = torch.randn(1, 1, 200, 200)
|
||||||
|
with torch.no_grad():
|
||||||
|
y = model(x)
|
||||||
|
print(y.shape)
|
||||||
|
|
@ -0,0 +1,146 @@
|
||||||
|
"""
|
||||||
|
Runs a model on a single node across multiple gpus.
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import numpy as np
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import scipy.io as sio
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import configargparse
|
||||||
|
|
||||||
|
from src.LayoutDeepRegression import Model
|
||||||
|
|
||||||
|
|
||||||
|
def main(hparams):
|
||||||
|
model = Model(hparams).cuda()
|
||||||
|
|
||||||
|
print(hparams)
|
||||||
|
print()
|
||||||
|
|
||||||
|
# Model loading
|
||||||
|
model_path = os.path.join(f'lightning_logs/version_' +
|
||||||
|
hparams.test_check_num, 'checkpoints/')
|
||||||
|
ckpt = list(Path(model_path).glob("*.ckpt"))[0]
|
||||||
|
print(ckpt)
|
||||||
|
|
||||||
|
model = model.load_from_checkpoint(str(ckpt))
|
||||||
|
|
||||||
|
model.eval()
|
||||||
|
model.cuda()
|
||||||
|
mae_test = []
|
||||||
|
|
||||||
|
# Testing Set
|
||||||
|
root = hparams.data_root
|
||||||
|
boundary = hparams.boundary
|
||||||
|
test_list = hparams.test_list
|
||||||
|
file_path = os.path.join(root, boundary, test_list)
|
||||||
|
root_dir = os.path.join(root, boundary, 'test', 'test')
|
||||||
|
|
||||||
|
with open(file_path, 'r') as fp:
|
||||||
|
for line in fp.readlines():
|
||||||
|
# Data Reading
|
||||||
|
data_path = line.strip()
|
||||||
|
path = os.path.join(root_dir, data_path)
|
||||||
|
data = sio.loadmat(path)
|
||||||
|
u_true, layout = data["u"], data["F"]
|
||||||
|
|
||||||
|
# Plot Layout and Real Temperature Field
|
||||||
|
fig = plt.figure(figsize=(10.5, 3))
|
||||||
|
|
||||||
|
grid_x = np.linspace(0, 0.1, num=200)
|
||||||
|
grid_y = np.linspace(0, 0.1, num=200)
|
||||||
|
X, Y = np.meshgrid(grid_x, grid_y)
|
||||||
|
|
||||||
|
plt.subplot(131)
|
||||||
|
plt.title('Heat Source Layout')
|
||||||
|
im = plt.pcolormesh(X, Y, layout)
|
||||||
|
plt.colorbar(im)
|
||||||
|
fig.tight_layout(w_pad=3.0)
|
||||||
|
|
||||||
|
layout = torch.Tensor(layout / 1000.0).unsqueeze(0).unsqueeze(0).cuda()
|
||||||
|
print(layout.size())
|
||||||
|
heat = torch.Tensor((u_true - 298) / 50.0).unsqueeze(0).unsqueeze(0).cuda()
|
||||||
|
with torch.no_grad():
|
||||||
|
heat_pre = model(layout)
|
||||||
|
mae = F.l1_loss(heat, heat_pre) * 50
|
||||||
|
print('MAE:', mae)
|
||||||
|
mae_test.append(mae.item())
|
||||||
|
heat_pre = heat_pre.squeeze(0).squeeze(0).cpu().numpy() * 50.0 + 298
|
||||||
|
hmax = max(np.max(heat_pre), np.max(u_true))
|
||||||
|
hmin = min(np.min(heat_pre), np.min(u_true))
|
||||||
|
|
||||||
|
plt.subplot(132)
|
||||||
|
plt.title('Real Temperature Field')
|
||||||
|
if "xs" and "ys" in data.keys():
|
||||||
|
xs, ys = data["xs"], data["ys"]
|
||||||
|
im = plt.pcolormesh(xs, ys, u_true, vmin=hmin, vmax=hmax)
|
||||||
|
plt.axis('equal')
|
||||||
|
else:
|
||||||
|
im = plt.pcolormesh(X, Y, u_true, vmin=hmin, vmax=hmax)
|
||||||
|
plt.colorbar(im)
|
||||||
|
|
||||||
|
plt.subplot(133)
|
||||||
|
plt.title('Predicted Temperature Field')
|
||||||
|
if "xs" and "ys" in data.keys():
|
||||||
|
xs, ys = data["xs"], data["ys"]
|
||||||
|
im = plt.pcolormesh(xs, ys, heat_pre, vmin=hmin, vmax=hmax)
|
||||||
|
plt.axis('equal')
|
||||||
|
else:
|
||||||
|
im = plt.pcolormesh(X, Y, heat_pre, vmin=hmin, vmax=hmax)
|
||||||
|
plt.colorbar(im)
|
||||||
|
|
||||||
|
save_name = os.path.join('outputs/predict_plot', os.path.splitext(os.path.basename(path))[0]+'.jpg')
|
||||||
|
fig.savefig(save_name, dpi=300)
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
mae_test = np.array(mae_test)
|
||||||
|
print(mae_test.mean())
|
||||||
|
np.savetxt('outputs/mae_test.csv', mae_test, fmt='%f', delimiter=',')
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# TRAINING ARGUMENTS
|
||||||
|
# ------------------------
|
||||||
|
# these are project-wide arguments
|
||||||
|
# default configuration file
|
||||||
|
config_path = Path(__file__).absolute().parent / "config/config.yml"
|
||||||
|
parser = configargparse.ArgParser(default_config_files=[str(config_path)], description="Hyper-parameters.")
|
||||||
|
|
||||||
|
# configuration file
|
||||||
|
parser.add_argument("--config", is_config_file=True, default=False, help="config file path")
|
||||||
|
|
||||||
|
# mode
|
||||||
|
parser.add_argument("-m", "--mode", type=str, default="train", help="model: train or test or plot")
|
||||||
|
|
||||||
|
# args for training
|
||||||
|
parser.add_argument("--gpus", type=int, default=0, help="how many gpus")
|
||||||
|
parser.add_argument("--batch_size", default=16, type=int)
|
||||||
|
parser.add_argument("--max_epochs", default=20, type=int)
|
||||||
|
parser.add_argument("--lr", default="0.01", type=float)
|
||||||
|
parser.add_argument("--resume_from_checkpoint", type=str, help="resume from checkpoint")
|
||||||
|
parser.add_argument("--num_workers", default=2, type=int, help="num_workers in DataLoader")
|
||||||
|
parser.add_argument("--seed", type=int, default=1, help="seed")
|
||||||
|
parser.add_argument("--use_16bit", type=bool, default=False, help="use 16bit precision")
|
||||||
|
parser.add_argument("--profiler", action="store_true", help="use profiler")
|
||||||
|
|
||||||
|
# args for validation
|
||||||
|
parser.add_argument("--val_check_interval", type=float, default=1,
|
||||||
|
help="how often within one training epoch to check the validation set")
|
||||||
|
|
||||||
|
# args for testing
|
||||||
|
parser.add_argument("--test_check_num", default='0', type=str, help="checkpoint for test")
|
||||||
|
parser.add_argument("--test_args", action="store_true", help="print args")
|
||||||
|
|
||||||
|
parser = Model.add_model_specific_args(parser)
|
||||||
|
hparams = parser.parse_args()
|
||||||
|
|
||||||
|
# test args in cli
|
||||||
|
if hparams.test_args:
|
||||||
|
print(hparams)
|
||||||
|
else:
|
||||||
|
main(hparams)
|
||||||
|
|
@ -0,0 +1,83 @@
|
||||||
|
"""
|
||||||
|
Runs a model on a single node across multiple gpus.
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from torch.backends import cudnn
|
||||||
|
import configargparse
|
||||||
|
import numpy as np
|
||||||
|
import pytorch_lightning as pl
|
||||||
|
|
||||||
|
from src.LayoutDeepRegression import Model
|
||||||
|
|
||||||
|
|
||||||
|
def main(hparams):
|
||||||
|
"""
|
||||||
|
Main training routine specific for this project
|
||||||
|
"""
|
||||||
|
seed = hparams.seed
|
||||||
|
np.random.seed(seed)
|
||||||
|
torch.manual_seed(seed)
|
||||||
|
cudnn.deterministic = True
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 1 INIT LIGHTNING MODEL
|
||||||
|
# ------------------------
|
||||||
|
model = Model(hparams)
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 2 INIT TRAINER
|
||||||
|
# ------------------------
|
||||||
|
trainer = pl.Trainer(
|
||||||
|
gpus=hparams.gpus,
|
||||||
|
precision=16 if hparams.use_16bit else 32,
|
||||||
|
# limit_test_batches=0.05
|
||||||
|
)
|
||||||
|
|
||||||
|
model_path = os.path.join(f'lightning_logs/version_' +
|
||||||
|
hparams.test_check_num, 'checkpoints/')
|
||||||
|
model_path = list(Path(model_path).glob("*.ckpt"))[0]
|
||||||
|
test_model = model.load_from_checkpoint(checkpoint_path=model_path, hparams=hparams)
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 3 START PREDICTING
|
||||||
|
# ------------------------
|
||||||
|
print(hparams)
|
||||||
|
print()
|
||||||
|
|
||||||
|
trainer.test(model=test_model)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# TESTING ARGUMENTS
|
||||||
|
# ------------------------
|
||||||
|
# these are project-wide arguments
|
||||||
|
config_path = Path(__file__).absolute().parent / "config/config.yml"
|
||||||
|
parser = configargparse.ArgParser(default_config_files=[str(config_path)], description="Hyper-parameters.")
|
||||||
|
parser.add_argument("--config", is_config_file=True, default=False, help="config file path")
|
||||||
|
|
||||||
|
# args
|
||||||
|
parser.add_argument("--save_check_num", default=0, type=int, help="checkpoint for test")
|
||||||
|
parser.add_argument("--max_epochs", default=20, type=int)
|
||||||
|
parser.add_argument("--max_iters", default=40000, type=int)
|
||||||
|
parser.add_argument("--resume_from_checkpoint", type=str, help="resume from checkpoint")
|
||||||
|
parser.add_argument("--seed", type=int, default=1, help="seed")
|
||||||
|
parser.add_argument("--gpus", type=int, default=0, help="how many gpus")
|
||||||
|
parser.add_argument("--use_16bit", type=bool, default=False, help="use 16bit precision")
|
||||||
|
parser.add_argument("--val_check_interval", type=float, default=1,
|
||||||
|
help="how often within one training epoch to check the validation set")
|
||||||
|
parser.add_argument("--profiler", action="store_true", help="use profiler")
|
||||||
|
parser.add_argument("--test_args", action="store_true", help="print args")
|
||||||
|
|
||||||
|
parser = Model.add_model_specific_args(parser)
|
||||||
|
hparams = parser.parse_args()
|
||||||
|
|
||||||
|
# test args in cli
|
||||||
|
if hparams.test_args:
|
||||||
|
print(hparams)
|
||||||
|
else:
|
||||||
|
main(hparams)
|
||||||
|
|
@ -0,0 +1,80 @@
|
||||||
|
"""
|
||||||
|
Runs a model on a single node across multiple gpus.
|
||||||
|
"""
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from torch.backends import cudnn
|
||||||
|
import configargparse
|
||||||
|
import numpy as np
|
||||||
|
import pytorch_lightning as pl
|
||||||
|
|
||||||
|
from src.LayoutDeepRegression import Model
|
||||||
|
|
||||||
|
|
||||||
|
def main(hparams):
|
||||||
|
"""
|
||||||
|
Main training routine specific for this project
|
||||||
|
"""
|
||||||
|
seed = hparams.seed
|
||||||
|
np.random.seed(seed)
|
||||||
|
torch.manual_seed(seed)
|
||||||
|
cudnn.deterministic = True
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 1 INIT LIGHTNING MODEL
|
||||||
|
# ------------------------
|
||||||
|
model = Model(hparams)
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 2 INIT TRAINER
|
||||||
|
# ------------------------
|
||||||
|
trainer = pl.Trainer(
|
||||||
|
max_epochs=hparams.max_epochs,
|
||||||
|
gpus=hparams.gpus,
|
||||||
|
precision=16 if hparams.use_16bit else 32,
|
||||||
|
val_check_interval=hparams.val_check_interval,
|
||||||
|
resume_from_checkpoint=hparams.resume_from_checkpoint,
|
||||||
|
profiler=hparams.profiler,
|
||||||
|
)
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# 3 START TRAINING
|
||||||
|
# ------------------------
|
||||||
|
print(hparams)
|
||||||
|
print()
|
||||||
|
trainer.fit(model)
|
||||||
|
|
||||||
|
trainer.test()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
|
||||||
|
# ------------------------
|
||||||
|
# TRAINING ARGUMENTS
|
||||||
|
# ------------------------
|
||||||
|
# these are project-wide arguments
|
||||||
|
config_path = Path(__file__).absolute().parent.parent / "config/config.yml"
|
||||||
|
parser = configargparse.ArgParser(default_config_files=[str(config_path)], description="Hyper-parameters.")
|
||||||
|
parser.add_argument("--config", is_config_file=True, default=False, help="config file path")
|
||||||
|
|
||||||
|
# args
|
||||||
|
parser.add_argument("--max_epochs", default=20, type=int)
|
||||||
|
parser.add_argument("--max_iters", default=None, type=int)
|
||||||
|
parser.add_argument("--resume_from_checkpoint", type=str, help="resume from checkpoint")
|
||||||
|
parser.add_argument("--seed", type=int, default=1, help="seed")
|
||||||
|
parser.add_argument("--gpus", type=int, default=0, help="how many gpus")
|
||||||
|
parser.add_argument("--use_16bit", type=bool, default=False, help="use 16bit precision")
|
||||||
|
parser.add_argument("--val_check_interval", type=float, default=1,
|
||||||
|
help="how often within one training epoch to check the validation set")
|
||||||
|
parser.add_argument("--profiler", action="store_true", help="use profiler")
|
||||||
|
parser.add_argument("--test_args", action="store_true", help="print args")
|
||||||
|
|
||||||
|
parser = Model.add_model_specific_args(parser)
|
||||||
|
hparams = parser.parse_args()
|
||||||
|
|
||||||
|
# test args in cli
|
||||||
|
if hparams.test_args:
|
||||||
|
print(hparams)
|
||||||
|
else:
|
||||||
|
main(hparams)
|
||||||
|
|
@ -0,0 +1,66 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
def weights_init(m):
|
||||||
|
"""
|
||||||
|
模型的权重初始化函数,由模型调用,如CRNN model
|
||||||
|
:param m: 待初始化的模型 nn.Module
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
class_name = m.__class__.__name__
|
||||||
|
if class_name.find("Conv") != -1:
|
||||||
|
torch.nn.init.kaiming_normal_(m.weight,
|
||||||
|
mode="fan_out",
|
||||||
|
nonlinearity="relu") # 初始化卷积层权重
|
||||||
|
# torch.nn.init.xavier_normal_(m.weight)
|
||||||
|
elif (class_name.find("BatchNorm") != -1
|
||||||
|
and class_name.find("WithFixedBatchNorm") == -1
|
||||||
|
): # batch norm层不能用kaiming_normal初始化
|
||||||
|
torch.nn.init.constant_(m.weight, 1)
|
||||||
|
torch.nn.init.constant_(m.bias, 0)
|
||||||
|
# m.weight.data.normal_(1.0, 0.02)
|
||||||
|
# m.bias.data.fill_(0)
|
||||||
|
elif class_name.find("Linear") != -1:
|
||||||
|
torch.nn.init.xavier_normal_(m.weight.data)
|
||||||
|
if m.bias is not None:
|
||||||
|
m.bias.data.fill_(0)
|
||||||
|
elif class_name.find("LSTM") != -1 or class_name.find("LSTMCell") != -1:
|
||||||
|
for name, param in m.named_parameters():
|
||||||
|
if "weight_ih" in name:
|
||||||
|
torch.nn.init.xavier_uniform_(param.data)
|
||||||
|
elif "weight_hh" in name:
|
||||||
|
torch.nn.init.orthogonal_(param.data)
|
||||||
|
elif "bias" in name:
|
||||||
|
param.data.fill_(0)
|
||||||
|
|
||||||
|
|
||||||
|
def weights_init_without_kaiming(m):
|
||||||
|
"""
|
||||||
|
模型的权重初始化函数,由模型调用,如CRNN model
|
||||||
|
:param m: 待初始化的模型 nn.Module
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
class_name = m.__class__.__name__
|
||||||
|
if class_name.find("Conv") != -1:
|
||||||
|
torch.nn.init.xavier_normal_(m.weight)
|
||||||
|
# torch.nn.init.normal_(m.weight) # 初始化卷积层权重
|
||||||
|
elif (class_name.find("BatchNorm") != -1
|
||||||
|
and class_name.find("WithFixedBatchNorm") == -1
|
||||||
|
): # batch norm层不能用kaiming_normal初始化
|
||||||
|
torch.nn.init.constant_(m.weight, 1)
|
||||||
|
torch.nn.init.constant_(m.bias, 0)
|
||||||
|
# m.weight.data.normal_(1.0, 0.02)
|
||||||
|
# m.bias.data.fill_(0)
|
||||||
|
elif class_name.find("Linear") != -1:
|
||||||
|
torch.nn.init.xavier_normal_(m.weight.data)
|
||||||
|
if m.bias is not None:
|
||||||
|
m.bias.data.fill_(0)
|
||||||
|
elif class_name.find("LSTM") != -1 or class_name.find("LSTMCell") != -1:
|
||||||
|
for name, param in m.named_parameters():
|
||||||
|
if "weight_ih" in name:
|
||||||
|
torch.nn.init.xavier_uniform_(param.data)
|
||||||
|
elif "weight_hh" in name:
|
||||||
|
torch.nn.init.orthogonal_(param.data)
|
||||||
|
elif "bias" in name:
|
||||||
|
param.data.fill_(0)
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Desc : Transforms.
|
||||||
|
"""
|
||||||
|
# File : np_transforms.py
|
||||||
|
# Time : 2020/04/06 17:24:54
|
||||||
|
# Author : Zweien
|
||||||
|
# Contact : 278954153@qq.com
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from torchvision import transforms
|
||||||
|
from torch.nn.functional import interpolate
|
||||||
|
|
||||||
|
|
||||||
|
class ToTensor:
|
||||||
|
"""Transform np.array to torch.tensor
|
||||||
|
Args:
|
||||||
|
add_dim (bool, optional): add first dim. Defaults to True.
|
||||||
|
type_ (torch.dtype, optional): dtype of the tensor. Defaults to tensor.torch.float32.
|
||||||
|
Returns:
|
||||||
|
torch.tensor: tensor
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, add_dim=True, type_=torch.float32):
|
||||||
|
|
||||||
|
self.add_dim = add_dim
|
||||||
|
self.type = type_
|
||||||
|
|
||||||
|
def __call__(self, x):
|
||||||
|
if self.add_dim:
|
||||||
|
return torch.tensor(x, dtype=self.type).unsqueeze(0)
|
||||||
|
return torch.tensor(x, dtype=self.type)
|
||||||
|
|
||||||
|
|
||||||
|
class Resize:
|
||||||
|
|
||||||
|
def __init__(self, size):
|
||||||
|
self.size = size
|
||||||
|
|
||||||
|
def __call__(self, x):
|
||||||
|
x_tensor = torch.tensor(x)
|
||||||
|
x_dim = x_tensor.dim()
|
||||||
|
for _ in range(4 - x_dim):
|
||||||
|
x_tensor = x_tensor.unsqueeze(0)
|
||||||
|
x_resize = interpolate(x_tensor, size=self.size)
|
||||||
|
for _ in range(4-x_dim):
|
||||||
|
x_resize = x_resize.squeeze(0)
|
||||||
|
return x_resize.numpy()
|
||||||
|
|
||||||
|
|
||||||
|
class Lambda(transforms.Lambda):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class Compose(transforms.Compose):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class Normalize(transforms.Normalize):
|
||||||
|
pass
|
||||||
|
|
@ -0,0 +1,29 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
|
||||||
|
|
||||||
|
def get_upsampling_weight(in_channels, out_channels, kernel_size):
|
||||||
|
factor = (kernel_size + 1) // 2
|
||||||
|
if kernel_size % 2 == 1:
|
||||||
|
center = factor - 1
|
||||||
|
else:
|
||||||
|
center = factor - 0.5
|
||||||
|
og = np.ogrid[:kernel_size, :kernel_size]
|
||||||
|
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
|
||||||
|
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float64)
|
||||||
|
weight[list(range(in_channels)), list(range(out_channels)), :, :] = filt
|
||||||
|
return torch.from_numpy(weight).float()
|
||||||
|
|
||||||
|
|
||||||
|
def initialize_weights(*models):
|
||||||
|
for model in models:
|
||||||
|
for module in model.modules():
|
||||||
|
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
|
||||||
|
nn.init.kaiming_normal_(module.weight)
|
||||||
|
if module.bias is not None:
|
||||||
|
module.bias.data.zero_()
|
||||||
|
elif isinstance(module, nn.BatchNorm2d):
|
||||||
|
module.weight.data.fill_(1)
|
||||||
|
module.bias.data.zero_()
|
||||||
|
|
@ -0,0 +1,5 @@
|
||||||
|
# -*- encoding: utf-8 -*-
|
||||||
|
try:
|
||||||
|
from torch.hub import load_state_dict_from_url
|
||||||
|
except ImportError:
|
||||||
|
from torch.utils.model_zoo import load_url as load_state_dict_from_url
|
||||||
|
|
@ -0,0 +1,7 @@
|
||||||
|
# content of test_sample.py
|
||||||
|
def inc(x):
|
||||||
|
return x + 1
|
||||||
|
|
||||||
|
|
||||||
|
def test_answer():
|
||||||
|
assert inc(3) == 4
|
||||||
Loading…
Reference in New Issue