96 KiB
| title | description | published | date | tags | editor | dateCreated |
|---|---|---|---|---|---|---|
| 10.APIs Reference List | true | 2022-05-17T07:17:08.267Z | ccai | markdown | 2022-03-11T03:18:01.489Z |
FCGI APIs Manual
CCAI provides many FCGI APIs. They are named fcgi_xxxx. Each fcgi API is a fcgi server, running in the background. Client APPs communicate with the fcgi server by using http post protocol.

These fcgi APIs will do AI for different cases, such as classification, face detection, OCR, TTS, or ASR. Please refer to the following API list to understand the specific API.
Some fcgi APIs have two working modes. One mode is doing inference locally in the fcgi_xxxx server, the other one is proxy mode. In proxy mode, the fcgi_xxxx server forwards requests from client apps to the remote server (such as QQ server or Tencent server), the remote server does inference. In which mode the fcgi_xxxx server works is decided by configuration file (policy_setting.cfg) or the result of policy calculation.
The following picture shows two working modes.
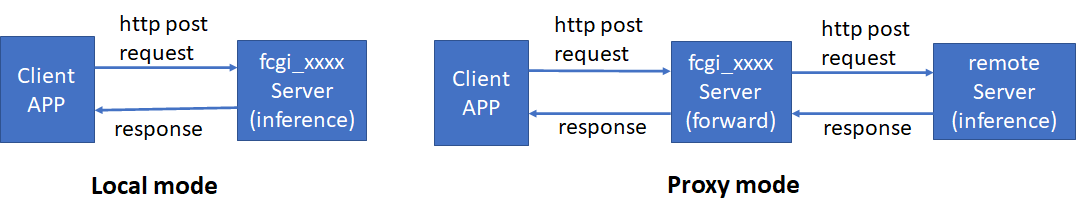
Some FCGI APIs are implemented by two languages, C++ and python. So some APIs have two types of API: python API and C++ API. Both python API and C++ API provide the same functionality and parameters. The only difference is they have different http addresses. So clients' apps can get the same inference result from either FCGI C++ API or python API by using different addresses.
TTS API usage
fcgi_tts API is used for text-to-speech. This is an end-to-end TTS API. Client app inputs one text sentence, fcgi_tts outputs the wave data of the text sentence. The wave data is the sound data. There are two paths for the wave data generated. The first path is that the wave data is written to a wav file. The second path is that the wave data is sent to the speakers directly, so you can hear the sentence from the speaker devices.
There are two working modes for fcgi_tts server, local mode and proxy mode.
Client app uses http protocol to communicate with fcgi_tts server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_py_tts'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'aht' | Int | [-24, 24] | 0 | increase(+)/descread(-) amount of semitone for generated speech |
| 'apc' | int | [0,100] | 58 | Set the speaker’s timbre |
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'format' | Int | Positive integer | 2 | 1:PCM 2:WAV 3:MP3 |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'speaker' | Int | Positive integer | 1 | 1: male voice 5: female voice |
| 'speed' | Int | [50-200] | 100 | The speed of voice |
| ‘text’ | string | Utf-8 encoding, No more than 150 bytes | Hello world | The input text sentence |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘volum’ | Int | [-10, 10] | 0 | volume |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In local mode(doing inference locally), only a “text” field is needed to set, other fields are ignored.
In proxy mode(doing inference on a remote server), all fields are needed to set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server (www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/aaitts.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret": 0, //return value: 0 (success) or 1(failure)
"msg": "ok", // request result: “ok” or “inference failed”
"data": { //inference result
"format": 2, // the format of voice : 1(pcm) 2(wav) 3(mp3)
"speech": "UklGRjL4Aw..." // wave data of input sentence
"md5sum": "3bae7bf99ad32bc2880ef1938ba19590" //Base64 encoding of synthesized speech
},
"time": 7.283 //fcgi_tts processing time
}
If the speaker devices are configured correctly, you can also hear the sentence directly from the speakers.
One example of a client app for fcgi_tts API is “api-gateway/cgi-bin/test-script/test-demo/post_local_tts_py.py”.
- c) Notice
Currently, this model only supports English text, not Chinese text.
It provides only python API.
To configure the speaker devices, you need to enable the pulseaudio and health-monitor services by following the following steps:
(1) On the host PC, install the pulseaudio package if this package hasn't been installed.
For example:
$> sudo apt-get install pulseaudio
(2) Enable the TCP protocol of the pulseaudio.
Edit the configuration file. for example:
$> sudo vim /etc/pulse/default.pa
Find out the following tcp configuration:
#load-module module-native-protocol-tcp
Uncomment the tcp configuration(remove "#"):
load-module module-native-protocol-tcp
Save and quit the configuration file.
(3) Restart the pulseaudio service. For example:
$> sudo systemctl restart pulseaudio
(4) Running the health-monitor service on the host pc if you don't run it.
This service is used to monitor the CCAI container.
ASR API usage (offline ASR case)
fcgi_asr API is a usage of Automatic-Speech-Recognition. This is an end-to-end speech recognition. It includes several libraries released by the OpenVINO™ toolkit. These libraries perform feature extraction, OpenVINO™-based neural-network speech recognition, and decoding to produce text from scores. All these libraries provide an end-to-end pipeline converting speech to text. Client app inputs an utterance (speech), fcgi_asr outputs the text directly expressed by this utterance.
Same as fcgi_tts, fcgi_asr also has two working modes, local mode and proxy mode.
Client app uses http protocol to communicate with fcgi_asr server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_asr'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'format' | Int | Positive integer | 2 | 1:PCM 2:WAV 3:AMR 4:SILK |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'speech' | string | Utterance data. Usually PCM data | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
In local mode(doing inference locally), only a “speech” field is needed to be set.
In proxy mode(doing inference on a remote server), all fields are needed to be set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server(www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/aaiasr.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret":0, //return value: 0 (success) or 1(failure)
"msg":"ok", // request result: “ok” or “inference error”
"data":{ //inference result
"text":HOW ARE YOU DOING //text
},
"time":0.695 //fcgi_asr processing time
}
One example of a client app for fcgi_asr API is “api-gateway/cgi-bin/test-script/test-demo/post_local_asr_c.py”.
- c) Notice
Currently, this model only supports English utterance, not Mathaland.
It provides two types of APIs: both C++ and python API.
API in Speech sample
fcgi_speech API is used for inference speech. The acoustic model is trained on Kaldi * neural networks. The input speech data must be speech feature vectors. The feature vector is ARK format (ARK file - the result of feature extraction). The inference result is score data, which is also ARK format.
Client app uses http protocol to communicate with fcgi_speech server.
The sample of sending request in client app is:
response = requests.post(url, post_parameter)
The following is the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_speech'
- post parameter: this parameter should include these fields:
| Field name | Type | Value | comments |
|---|---|---|---|
| 'stage' | string | {'RAW_FORMAT_INIT', 'IR_FORMAT_INIT_NETWORK', 'IR_FORMAT_INIT_EXENETWORK', 'INFERENCE'} | Only have 4 items |
| 'model' | string | Example: './models/wsj_dnn5b.xml' | IR format file or no IR format model |
| 'batch' | int | Positive integer. Example: 1 or 8 | Set based on the real case |
| 'device' | string | Example: 'GNA_AUTO' or ‘CPU’ | Select the inference device |
| 'scale_factor' | int | Positive integer Example: 2048 | Used for GNA HW |
| 'speech' | string | Speech input vector data | Must be encoded by base64 method |
| 'time_stamp' | int | Positive integer | Time stamp for this request. |
The fcgi_speech uses a finite state machine to record the behavior. Client apps should use different ‘stage’ requests to trigger translation of fcgi_speech behavior.
For IR format model, the sample of post requests sequence is:
The First post request is init request
['stage'] = 'IR_FORMAT_INIT_NETWORK'
['model'] = './models/wsj_dnn5b.xml'
['batch'] = 8
The second post request is also init request:
['stage'] = 'IR_FORMAT_INIT_EXENETWORK '
['model'] = './models/wsj_dnn5b.xml'
['device'] = 'GNA_AUTO'
The last post request is for inference:
['stage'] = 'INFERENCE'
['model'] = './models/wsj_dnn5b.xml'
['speech'] = base64_data
For IR format model, the sample of post requests sequence is: (two requests only)
The First post request is init request:
['stage'] = 'RAW_FORMAT_INIT'
['model'] = './models/ELE_M.raw'
['batch'] = 1
['device'] = 'GNA_AUTO'
['scale_factor'] = 2048
The second post request which is also the last request is for inference:
['stage'] = 'INFERENCE'
['model'] = './models/ELE_M.raw'
['speech'] = base64_data
- b) Response
The response of post request is json format, for example:
{
"ret":0, //return value: 0 (success) or 1(failure)
"msg":"ok", // request result: “ok” or “inference error”
"data":{ ….. // inference result
………… // response data
},
"time":0.344222 //fcgi_speech processing time
}
One example of a client app for fcgi_speech API is “api-gateway/cgi-bin/test-script/test-demo/post_local_speech_c.py”.
- c) Notice
The fcgi_speech API doesn’t have proxy mode. That means this API doesn’t support doing inference on remote servers.
This API can use GNA_HW as a reference device.
It provides only C++ API.
Policy API usage
fcgi_policy API is used to select inference devices or working mode(local model or proxy mode) for fcgi APIs.
Client app uses http protocol to communicate with fcgi_policy server.
The sample of sending request in client app is:
response = requests.post(url, post_parameter)
The following is the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_policy'
- post parameter: this parameter should include these fields.
| Field name | Type | Value | comments |
|---|---|---|---|
| 'device' | string | CPU, GPU, GNA_AUTO, GNA_HW, GNA_SW | This field is used to set inference devices. Such as “GPU”, “CPU” etc. |
| 'local' | string | “1” - do inference locally “0” - do inference on a remote server | Select working mode of fcgi server: local mode or proxy mode |
- b) Response
The response of the post request is a string, which indicates whether the request is processed correctly.
“successfully set the policy daemon" // OK
"failed to set policy daemon" // Fail
- c) Notice
The policy daemon must be run, or else calling this API will fail.
Run this policy API before running any other case if you want to select an inference device or change working mode of fcgi APIs.
This setting is a global setting. That means the setting will impact the following cases.
It provides two types of APIs: C++ and python API.
Classification API usage
fcgi_classification API is used to run inference on an image, and produce the classification information for objects in the image. Client app inputs one picture(image), fcgi_classification outputs the object information, such as what the object is, and the coordinates of the object in the picture.
Same as fcgi_tts, fcgi_classification also has two working modes, locol mode and proxy mode.
Client app uses http protocol to communicate with fcgi_classification server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_classfication'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
In proxy mode(doing inference on a remote server), all fields are needed to be set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server(www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/imagetag.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret":0,
"msg":"ok",
"data":{
"tag_list":[
{"tag_name":'sandal',"tag_confidence":0.786503}
]
},
"time":0.380
}
One example of a client app for fcgi_classification API is “api-gateway/cgi-bin/test-script/test-demo/post_local_classification_c.py ”.
- c) Notice
It provides two types of APIs: both C++ and python API.
Face Detection API usage
fcgi_face_detection API is used to run inference on an image, and find out human faces in the image. Client app inputs one picture(image), fcgi_face_detection outputs the face information, such as how many human faces, and the bounding box for each face in the picture.
Same as fcgi_tts, fcgi_face_detection also has two working modes, local mode and proxy mode.
Client app uses http protocol to communicate with fcgi_face_detection server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_face_detection'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
In proxy mode(doing inference on a remote server), all fields are needed to be set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server(www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/detectface.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret":0,
"msg":"ok",
"data":{
"face_list":[
{
"x1":655,
"y1":124,
"x2":783,
"y2":304
},
{
"x1":68,
"y1":149,
"x2":267,
"y2":367
} ]
},
"time":0.305
}
One example of a client app for fcgi_face_detection API is “api-gateway/cgi-bin/test-script/test-demo/post_local_face_detection_c.py ”.
- c) Notice
It provides two types of API: both C++ and python API.
Facial Landmark API usage
fcgi_facial_landmark API is used to run inference on an image, and print human facial landmarks in the image. Client app inputs one picture(image), fcgi_facial_landmark outputs the coordinates of facial landmark points.
Same as fcgi_tts, fcgi_facial_landmark also has two working modes, local mode and proxy mode.
Client app uses http protocol to communicate with fcgi_facial_landmark server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_facial_landmark'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
In proxy mode(doing inference on a remote server), all fields are needed to be set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server(www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/detectface.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret":0,
"msg":"ok",
"data":{
"image_width":916.000000,
"image_height":502.000000,
"face_shape_list":[
{"x":684.691284,
"y":198.765793},
{"x":664.316528,
"y":195.681824},
……
{"x":241.314194,
"y":211.847031} ]
},
"time":0.623
}
One example of a client app for fcgi_facial_landmark API is “api-gateway/cgi-bin/test-script/test-demo/post_local_facial_landmark_c.py ”.
- c) Notice
It provides two types of API: both C++ and python API.
OCR API usage
fcgi_ocr API is used to run inference on an image, and recognize handwritten or printed text from an image. Client app inputs one picture(image), fcgi_ocr outputs the text information in the picture. The information includes text coordinations and text confidence.
Same as fcgi_tts, fcgi_ocr also has two working modes, local mode and proxy mode.
Client app uses http protocol to communicate with fcgi_ocr server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_ocr'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
In proxy mode(doing inference on a remote server), all fields are needed to be set.
In proxy mode, ‘appid’ and ‘appkey’ are the necessary parameters in order to get the right results from the remote server(www.ai.qq.com). You should register on www.ai.qq.com and get ‘appid’ and ‘appkey’. Please refer to https://ai.qq.com/doc/imgtotext.shtml , find out how to apply these fields and how to write a post request for the remote server.
- b) Response
The response of post request is json format, for example:
{
"ret":0,
"msg":"ok",
"data":{
"item_list":[
{
"itemcoord":[
{
"x":161.903748,
"y":91.755684,
"width":141.737503,
"height":81.645004
}
],
"words":[
{
"character":i,
"confidence":0.999999
},
{
"character":n,
"confidence":0.999998
},
{
"character":t,
"confidence":0.621934
},
{
"character":e,
"confidence":0.999999
},
{
"character":l,
"confidence":0.999995
} ],
"itemstring":intel
},
{
"itemcoord":[
{
"x":205.378326,
"y":153.429291,
"width":175.314835,
"height":77.421722
}
],
"words":[
{
"character":i,
"confidence":1.000000
},
{
"character":n,
"confidence":1.000000
},
{
"character":s,
"confidence":1.000000
},
{
"character":i,
"confidence":0.776524
},
{
"character":d,
"confidence":1.000000
},
{
"character":e,
"confidence":1.000000
} ],
"itemstring":inside
} ]
},
"time":1.986
}
One example of a client app for fcgi_ocr API is “api-gateway/cgi-bin/test-script/test-demo/post_local_ocr_c.py ”.
- c) Notice
It provides two types of API: both C++ and python API.
formula API usage
fcgi_formula API is used to run inference on an image. It can recognize formulas and output formulas in latex format. Client app inputs one picture(image), fcgi_formula outputs the formula in latex format.
fcgi_formula has only one working mode, local mode.
Client app uses http protocol to communicate with fcgi_formula server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_py_formula'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
- b) Response
The response of post request is json format, for example:
{'ret': 0, 'msg': 'ok', 'data': '1 1 1 v v ^ { 1 } + 7 . 7 9 o ^ { 1 } - o - 0 . 9 0 f ^ { 7 } s ^ { 7 }', 'time': 0.518}
One example of a client app for fcgi_ocr API is “api-gateway/cgi-bin/test-script/test-demo/post_local_formula_py.py ”.
- c) Notice
It provides only python API.
handwritten API usage
fcgi_handwritten API is used to run inference on an image, and recognize handwritten chinese from an image. Client app inputs one picture(image), fcgi_handwritten outputs the text information in the picture.
fcgi_handwritten has one working mode, local mode.
Client app uses http protocol to communicate with fcgi_handwritten server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_py_handwritten'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
- b) Response
The response of post request is json format, for example:
{'ret': 0, 'msg': 'ok', 'data': '的人不一了是他有为在责新中任自之我们', 'time': 0.405}
One example of a client app for fcgi_handwritten API is “api-gateway/cgi-bin/test-script/test-demo/post_local_handwritten_py.py ”.
- c) Notice
It provides only python API.
ppocr API usage
fcgi_ppocr API is used to run inference on an image, and recognize printed text from an image. Client app inputs one picture(image), fcgi_ppocr outputs the text information in the picture.
fcgi_ppocr has one working mode, local mode.
Client app uses http protocol to communicate with fcgi_ppocr server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_py_ppocr'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
- b) Response
The response of post request is json format, for example (OCR result with chinese characters):
{'ret': 0, 'msg': 'ok', 'data': ' 纯臻营养护发素 产品信息/参数 45元/每公斤,100公斤起订 每瓶22元,1000瓶起订) 【品牌】:代加工方式/OEMODM 【品名】:纯臻营养护发素 ODMOEM 【产品编号】:YM-X-3011 【净含量】:220ml (适用人群】:适合所有肤质 (主要成分】:鲸蜡硬脂醇,燕麦B-葡聚 糖、椰油酰胺丙基甜菜碱、泛醇 (成品包材) (主要功能】:可紧致头发磷层,从而达到 即时持久改善头发光泽的效果,给干燥的头 发足够的滋养', 'time': 0.308}
One example of a client app for fcgi_ppocr API is “api-gateway/cgi-bin/test-script/test-demo/post_local_ppocr_py.py ”.
- c) Notice
- It provides only python API.
segmentation API usage
fcgi_segmentation API is used to run inference on an image, and recognize semantic segmentation from an image. Client app inputs one picture(image), fcgi_segmentation outputs a semantic segmentation picture.
fcgi_segmentation has one working mode, local mode.
Client app uses http protocol to communicate with fcgi_segmentation server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_segmentation'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
- b) Response
The response of post request is json format, for example:
{ "ret": 0, "msg": "ok", "data": "b'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA...AABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBBAABwQQAAcEEAAHBB'","time": 0.31}
One example of a client app for fcgi_segmentation API is “api-gateway/cgi-bin/test-script/test-demo/post_local_segmentation_c.py ”.
- c) Notice
It provides two types of API: both C++ and python API.
super resolution API usage
fcgi_super_resolution API is used to run inference on an image, and convert a small picture to a large picture. Client app inputs one picture(image), fcgi_super_resolution outputs a large picture.
fcgi_super_resolution has one working mode, local mode.
Client app uses http protocol to communicate with fcgi_super_resolution server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_super_resolution'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
In Local mode(doing inference locally), only an “image” field is needed to be set.
- b) Response
The response of post request is json format, for example
{"ret":0, "msg":"ok","data":"/////+rX//////vm+9/K/uPO/+PO/+jU/+3a//Lf//Tg//fj//Tg//3o//3p//nm/+7a/+vY/+3a/+/d/+7c//Xj//jl//jm//De//Hf//Th//Ti//Ph//7r///s//nn/+7c/+/e/+/c/+rX/+LO/+le:...AAAAAAAAAAAAAAAAAAAAAACggDHx4ZLS0oMzMwNjc3tQ==", "time":0.238}
One example of a client app for fcgi_super_resolution API is “*api-gateway/cgi-bin/test-script/test-demo/post_local_super_resolution_c.py *”.
- c) Notice
It provides two types of API: both C++ and python API.
digitalnote API usage
digitalnote API is used to run inference on an image, .Recognize and output the handwriting, machine writing and formulas in the picture. Client app inputs one picture(image), fcgi_digitalnote outputs the handwriting, machine writing and formulas in the picture.
fcgi_digitalnote only has local mode and does not have remote mode.
Client app uses http protocol to communicate with fcgi_digitalnote server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_digitalnote'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'app_id' | Int | Positive integer | 2128571502 | Application ID |
| 'nonce_str' | string | No more than 32 byte | fa577ce340859f9fe | Random string |
| 'image' | string | image data, often is a picture | Must be encoded by base64 method | |
| ‘time_stamp’ | Int | Positive integer | 1493468759 | timestamp |
| ‘appkey’ | string | string | di6ik9b9JiYfImUB | Application key |
| ‘latex’ | string | string | "365 234 " | Pixel coordinates of latex |
| ‘handwritten’ | string | string | "354 39 431 123 " | Pixel coordinates of latex |
| ‘html’ | int | {0,1} | 0 | 0 for terminal client 1 for html clinet |
In Local mode(doing inference locally), “image” field ,formula, latex and html are needed to be set. Find the coordinates of a pixel in the formula from the picture and fill in the latex field. Find the coordinates of a pixel in the handwritten from the picture and fill in the handwritten field. Use spaces to connect coordinates. If you use a terminal client the html field is 0.
- b) Response
The response of post request is json format, for example
{'ret': 0, 'msg': 'ok', 'data': '的人不一了是他有为在责新中任自之我们\n 的人不一了是他有为在责新中任自之我们\n 4 7 4 W ^ { 1 } + 7 . 1 9 o ^ { 4 } - 6 - 0 . 9 6 L ^ { 1 } U\n 区是我国载人航天工程立项实施以来的第19次飞行任务,也是空间站阶段的首次载\n 人飞行任务。飞船入轨后,将按照预定程序,与大和核心舱进行自主快速交会对接\n 自合体飞行期间,航大员将进驻大和核心能,完成为期3个月的在轨驻留,开展机械\n 操作、出舱活动等工作,验证航大员长期在轨驻留、再生生保等一系列关键技术\n 自前,大和核心舱与大舟二号的组合体运行在约390km的近圆对接轨道,状态良\n 好,满足与神舟十二号交会对接的任务要求和航大员进驻条件\n 震撼!神舟十二号与地球同框\n 神舟十二号载人飞船升空过程中,舱内3名航天员状态良好,推进舱外摄像机拍摄全\n 了神舟十二号与地球同框震想面面\n 自关报道:神舟十二号载人飞船飞行乘组确定!他们在太空将怎样生活3个月\n ', 'time': 1.095}
One example of a client app for fcgi_super_resolution API is “api-gateway/cgi-bin/test-script/test-demo/post_local_digitalnote_c.py”.
- c) Notice
It only provides python API.
It can speed up the inference. The picture does not need to be sent three times to get three different results. Handwriting, machine writing and formula can be called by one request.
Video pipeline management (control) API usage
Video pipeline API is used to start or stop a video pipeline.
The following are the detailed information about request parameters and response.
- a) Request
- url: such as: url 'http://localhost:8080/cgi-bin/streaming'
- Content-Type: application/json
- JSON object fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| "pipeline" | string | string | "launcher.object_detection" | |
| "method" | string | "start"/"stop" | "start" | |
| "parameter" | string | JSON string | "{"source":"device=/dev/video0","sink":"v4l2sink device=/dev/video2","resolution":"width=800,height=600" }" | optional, example is the default value |
- example:
$ curl -H "Content-Type:application/json" -X POST \
http://localhost:8080/cgi-bin/streaming -d \
'{"pipeline":"launcher.object_detection", "method":"start"}'
- b) Response
The response is a string, “0” means success, “1” means failure.
Live ASR API usage (online ASR case)
fcgi_live_asr API is also a usage of Automatic-Speech-Recognition. It uses the same models as fcgi_asr API(ASR API usage in 10.1.2). The difference is that this API is an online ASR case while 10.1.2 is an offline ASR case. That means this live asr API continuously captures the voice from the MIC devices, do inference, and send out the sentences what the voice expressed.
fcgi_live_asr case has only one working mode - local mode. It doesn’t support proxy mode.
Client app uses http protocol to communicate with fcgi_live_asr server.
The sample code of sending post request in client app is:
response = requests.post(url, post_parameter)
The following are the detailed information about request parameters and response.
- a) Input parameters
- http url: such as: url= 'http://localhost:8080/cgi-bin/fcgi_live_asr'
- post parameter: this parameter should include these fields:
| Field name | Type | Range | Example | comments |
|---|---|---|---|---|
| 'mode' | Int | 0,1,2 | 0 | To control the running mode of fcgi_live_asr service: 0: starting the live asr service 1: do inference and get the result sentences. 2: stop live ar service |
- b) Response
The response of post request is json format, for example:
Starting live asr ok!
HOW ARE YOU DOING
HELLO
HA
…………..
Stop live asr ok!
One example of a client app for fcgi_live_asr API is “api-gateway/cgi-bin/test-script/test-demo/post_local_live_asr.py”.
- c) Notice
Currently, this model only supports English utterance, not Mathaland.
It only provides C++ APIs.
In order to use this API, you need to enable the pulseaudio and health-monitor services.
(1) On the host PC, install the pulseaudio package if this package hasn't been installed. For example:
$> sudo apt-get install pulseaudio
(2) Enable the TCP protocol of the pulseaudio. Edit the configuration file. for example:
$> sudo vim /etc/pulse/default.pa
Find out the following tcp configuration:
#load-module module-native-protocol-tcp
Uncomment the tcp configuration(remove "#"):
load-module module-native-protocol-tcp
Save and quit the configuration file. (3) Restart the pulseaudio service. For example:
$> sudo systemctl restart pulseaudio
(4) Running the health-monitor service on the host pc if you don't run it. This service is used to monitor the CCAI container.
gRPC APIs Manual
CCAI framework not only provides FGCI APIs, but also provides many gRPC APIs. Client APPs can do inference by calling gRPC APIs.

The following are detailed gRPC APIs.
proto file
syntax = "proto3";
package inference_service;
service Inference {
rpc OCR (Input) returns (Result) {}
rpc ASR (Input) returns (Result) {}
rpc Classification (Input) returns (Result) {}
rpc FaceDetection (Input) returns (Result) {}
rpc FacialLandmark (Input) returns (Result) {}
rpc SimulationLib (SimInput) returns (SimResult) {}
}
message Input {
bytes buffer = 1;
}
message Result {
string json = 1;
}
message SimInput {
uint32 stage = 1;
string model = 2;
uint32 batch = 3;
string device = 4;
uint32 scale_factor = 5;
bytes speech = 6;
}
message SimResult {
string json = 1;
bytes rawdata = 2;
}
In the .proto file the service interface, ‘Inference’, is defined, and rpc methods, ‘OCR’, ‘Classification’, ‘FaceDetection’, ‘FacialLandmark’, ‘SimulationLib’ and ‘ASR’ are defined inside the service.
OCR method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| buffer | bytes | .jpg or .png image file buffer |
Response: message, Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | example: [ { "itemcoord":{ "x":162, "y":91, "width":141, "height":81 }, "itemstring":"intel" }, { "itemcoord":{ "x":205, "y":153, "width":175, "height":77 } "itemstring":"inside" } ] |
the field is json format string |
ASR method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| buffer | bytes | .wav file buffer |
Response: message Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | example: { "text":"HOW ARE YOU DOING" } |
the field is json format string |
Classification method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| buffer | bytes | .jpg or .png image file buffer |
Response: message, Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | example: [ { "Tag_name":"sandal","tag_confidence":0.743236 } ] |
the field is json format string |
FaceDetection method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| buffer | bytes | .jpg or .png image file buffer |
Response: message, Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | example: [ {"x1":611,"y1":106,"x2":827,"y2":322}, {"x1":37,"y1":128,"x2":298,"y2":389} ] |
the field is json format string |
FacialLandmark method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| buffer | bytes | .jpg or .png image file buffer |
Response: message, Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | example: [ {"x":684,"y":198}, {"x":664,"y":195}, … ] |
the field is json format string |
SimulationLib method
Request: message Input
| Field name | Type | Value | comments |
|---|---|---|---|
| stage | uint32 | Range of {0, 1, 2, 3} | Specify working phases: initialization or inference. |
| model | string | Example: /home/xxx/models/wsj_dnn5b.xml | Model file, including path |
| batch | uint32 | Example: 8 | batch size |
| device | string | CPU or GNA_HW | Inference device: CPU or GNA? |
| scale_factor | uint32 | Example: 2048 | Used for GNA HW, provided by client app. |
| speech | bytes | Speech data buffer |
Response: message Result
| Field name | Type | Value | comments |
|---|---|---|---|
| json | string | Example: Initialization { "ret":0, "msg":"ok", "data":{ "input information(name:dimension)":{ "Parameter":[8,440] }, "output information(name:dimension)":{ "affinetransform14/Fused_Add_":[8,3425] } }, "time":0.223394 } Inference: { "ret":0, "msg":"ok", "data":{ "inference result":"-11" }, "time":0.014026 } |
The field is a json format string. It includes the status of initialization or inference results. For initialization, the “data” field includes input/output information, such as name, shape etcs. For inference, the “data” field includes the status code of inference. |
| rawdata | bytes | The output data of inference. It is often the score ark data. |
Simulation lib
What is simulation lib
For supporting those already existing applications which are using OpenVINO C++ APIs via CCAI, we introduced a simulation library named simlib. This library provided the same APIs like OpenVINO does, but will convert those APIs calling to CCAI REST/gRPC calling internally, so that under the most cases, those applications just need replace 1 or 2 header file including from OpenVINO header file(s) to simulation lib header file, and recompile the application with linkage to simulation lib. All existing logics within those applications will not need to change.
Note: So far, only limited OpenVINO APIs were available from simulation lib, the remaining APIs support are ongoing.
How to make those applications work with simulation lib
Remark original OV header file and include our simulation header file like:
// #include <inference_engine.hpp>
#include <sr_inference_engine.hpp>
Compile or link simulation lib as:
g++ -I /opt/intel/service_runtime/simlib/ sample.cpp -o sample -L /opt/intel/service_runtime/simlib/ -linference_engine
Note: please make sure the simulation lib was installed (by service-runtime-simlib_xxx.deb package), you can find it under /opt/intel/service_runtime/simlib/ in host system, and make sure the service container is running so that the simulation lib can communicate with backend services.
Low level APIs Manual
Runtime service library provides APIs for upper layers, such as for fcgi or grpc layer etc. Runtime library supports different inference engines, such as Openvino or Pytorch. But the runtime library only provides one set of APIs to the upper layer. Upper layers select the inference engine by passing parameters to runtime APIs.
Runtime APIs are *“simple” *APIs. “simple” means the number of APIs is limited. Although a few APIs, you can call these APIs to do inference for many cases, such as processing image, speech, or video etc. “simple” also means they can be used friendly and easily. For example, if you want to do inference on an image, you can finish this work by calling only one API, vino_ie_pipeline_infer_image(). You need not care about how to build up inference pipelines. They are opaque to the end user. All building work is done in the Runtime library.
The runtime service library APIs are implemented by two kinds of languages, C++ and python. So it provides two types of APIs. One type is C++ APIs, it can be called by C++ programs directly. Another is python APIs, it is prepared for python programs.
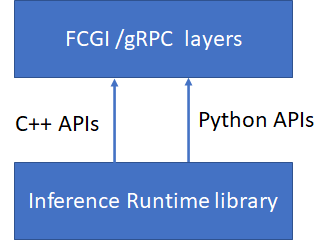
Notice:
There are two versions of C++ API. Version 0 is described in section 10.3.1(C++ APIs for Openvino Backend Engine). It only supports Openvino as an inference engine, and doesn't support pytorch engine.
Version 1 is described in section 10.3.3(C++ APIs for Different backend Engines). It supports both Openvino and Pytorch engie. Some APIs in version 0 can be replaced by APIs in version 1.
Some C++ APIs in version 0 will be deprecated in the future. I encourage you to try to use C++ APIs in version 1 if APIs in version 0 are marked “deprecated”.
C++ APIs for Openvino Backend Engine(Version 0)
Return value (deprecated)
/**
*@brief Status code of inference
*/
#define RT_INFER_ERROR -1 //inference error
#define RT_LOCAL_INFER_OK 0 //inference successfully on local
#define RT_REMOTE_INFER_OK 1 //inference successfully on remote server
Some APIs have two work modes. One mode is local mode, which means doing inference on local XPU. Another is proxy mode. In proxy mode, API forwards requests to the remote server (such as QQ server or Tencent server). The remote server does inference.
In local mode, the return value is
RT_LOCAL_INFER_OK (success) or RT_INFER_ERROR (failure).
In proxy mode, the return value is
RT_REMOTE_INFER_OK (success) orRT_INFER_ERROR(failure).
Server parameter
/**
* @brief This is the parameters to do inference on remote server
*/
struct serverParams {
std::string url; //the address of server
std::string urlParam; //the post parameter of request
std::string response; //the response data of server
};
This parameter is used by the API in proxy mode. Set server address(serverParams.url) and request(serverParams.urlParam), get server response(serverParams.response).
The example of usage:
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
…………do inference on remote servers ………………
//get server response
std::cout << urlInfo.response << std::endl;
Policy configuration API
This API is used by users to change API behavior. Users can set API working mode (such as local mode or proxy mode), or assign inference devices (XPU) in local mode.
-
- API
/**
* @brief Set parameters to configure vino ie pipeline
* @param configuration Parameters set from the end user.
*/
int vino_ie_pipeline_set_parameters(struct userCfgParams& configuration);
-
- parameter
/**
* @brief This is the parameters setting from end user
*/
struct userCfgParams {
bool isLocalInference; //do inference in local or remote
std::string inferDevice; //inference device: CPU, GPU or other device
};
isLocalInference: true – local mode, do inference in local XPU.
False – proxy mode, do inference on remote server.
inferDevice: inference device in local mode, you can select: CPU, GPU, GNA_AUTO etc.
-
- example
struct userCfgParams cfg{true, "CPU"};
int res = vino_ie_pipeline_set_parameters(cfg);
-
- Notice
This API setting is a global setting. That means this setting affects all the following APIs behaviors.
image API (deprecated)
This API is used to do inference on images. It is related to image processing.
-
- API
/**
* @brief Do inference for image
* @param image Images input for network
* @param additionalInput Other inputs of network(except image input)
* @param xmls Path of IE model file(xml)
* @param rawDetectionResults Outputs of network, they are raw data.
* @param remoteSeverInfo parameters to do inference on remote server
* @return Status code of inference
*/int vino_ie_pipeline_infer_image(std::vector<std::shared_ptr<cv::Mat>>& image,
std::vector<std::vector<float>>& additionalInput,
std::string xmls,
std::vector<std::vector<float>*>& rawDetectionResults,
struct serverParams& remoteServerInfo);
-
- parameter
| Parameter | Type | Comments |
|---|---|---|
| image | std::vector<std::shared_ptr<cv::Mat>> | The input data of the image. The data format of the image is cv::Mat. The input is a batch of images. The batch is expressed by std::vector<>. The vector size is batch size. Each item in the vector is a shared pointer, std::shared_ptr<cv::Mat>, which points to one image data in the batch. |
| additionalInput | std::vector<std::vector float> | For some networks, they have more than one input. This parameter is used for other inputs except image input. The type is also std::vector <>. Vector size is the number of inputs in a network except image input. For each input, the input data type is std::vector float. |
| std::string | The IE model file, which includes the file path. The file must be xml format. | |
| rawDetectionResults | std::vector<std::vectorfloat*> | The inference results. For some networks, they have more than one output port. This parameter is defined to std::vector<>. The vector size is the number of output ports. Each item in the vector is a pointer, which points to a vector(std::vector float), this vector is the inference result of one output port. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
-
- example
std::string img_file = "./models/person-detection-retail-0013.png";
std::string model_file = "./models/person-detection-retail-0013.xml";
std::vector<float> rawDetectionResult;
std::vector<std::vector<float>> additionalInput;
std::vector<std::vector<float>*> rawDetectionResults;
rawDetectionResults.push_back(&rawDetectionResult);
std::vector<std::shared_ptr<cv::Mat>> images;
std::shared_ptr<cv::Mat> frame_ptr = std::make_shared<cv::Mat>(cv::imread(img_file, cv::IMREAD_COLOR));
images.push_back(frame_ptr);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg"; // = "test";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
int res = vino_ie_pipeline_infer_image(images, additionalInput, model_file, rawDetectionResults, urlInfo);
-
- Notice
Parameter - additionalInput: don’t support cv::Mat data format.
ASR API (deprecated)
ASR means Automatic Speech Recognition, speech-to-text. This API is implemented based on some Intel speech libraries.
-
- API
/**
* @brief Do inference for speech (ASR). Using intel speech libraries.
* @param samples Speech data buffer.
* @param sampleLength Buffer size of speech data
* @param bytesPerSample Size for each speech sample data (how many bytes for each sample)
* @param rh_utterance_transcription Text result of speech. (ASR result)
* @param remoteSeverInfo parameters to do inference on remote server.
* @return Status code of inference
*/
int vino_ie_pipeline_infer_speech(const short* samples,
int sampleLength,
int bytesPerSample,
std::string config_path,
std::vector<char> &rh_utterance_transcription,
struct serverParams& remoteServerInfo);
-
- parameters
| Parameter | Type | Comments |
|---|---|---|
| samples | short int | speech data, which format is PCM data. Each short int data is one PCM sample. |
| sampleLength | int | The size of speech data |
| bytesPerSample | int | the bytes number for each speech sample data. For PCM data, the value should be 2, which means each PCM sample is two bytes. |
| config_path | std::string | The configuration file for the ASR model. This configuration file is used by intel speech libraries |
| rh_utterance_transcription | std::vector char | the inference result for speech data. The data format is char. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
Samples, sampleLength, and bytesPerSample are often obtained by parsing the header of a wave file.
-
- example
std::string wave_filename = "./models/how_are_you_doing.wav";
std::string config_filename = "./models/lspeech_s5_ext/FP32/speech_lib.cfg";
short* samples = nullptr;
int sampleLength = 0;
int bytesPerSample = 0;
unsigned int size = 0;
uint8_t* wave_data = ReadBinaryFile(wave_filename.c_str(), &size);
parseWaveFile(wave_data, size, samples, sampleLength, bytesPerSample);
std::vector<char> rh_utterance_transcription(1024 * 1024);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
int res = vino_ie_pipeline_infer_speech(samples, sampleLength,
bytesPerSample, config_filename, rh_utterance_transcription, urlInfo);
-
- Notice
This ASR model only supports English, not Chinese.
common API (deprecated)
“Common” means this API is used for cases other than image and ASR. For example, the TTS case. If the input/output data of the model meet the requirements of API, then this API can be used in this case.
-
- API
/**
* @brief Do inference for common models
* @param inputData Data input for network. The data type is float.
* @param additionalInput Other inputs of network(except image input)
* @param xmls Path of IE model file(xml)
* @param rawDetectionResults Outputs of network, they are raw data.
* @param remoteSeverInfo parameters to do inference on remote server
* @return Status code of inference
*/
int vino_ie_pipeline_infer_common(std::vector<std::shared_ptr<std::vector<float>>>&
inputData,
std::vector<std::vector<float>>& additionalInput,
std::string xmls,
std::vector<std::vector<float>*>& rawDetectionResults,
struct serverParams& remoteServerInfo);
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| inputData | std::vector<std::shared_ptr<std::vector float>> | Input data for the network. Similar to the image parameter of image API. The input data is a batch of vectors. The batch vectors are expressed by std::vector<>. The vector size is batch size. Each item of vector is a share pointer, std::shared_ptr<std::vector float>, which points to one float vector. |
| additionalInput | std::vector<std::vector float> | For some networks, they have more than one input. This parameter is used for other inputs except inputData pin. The type is also std::vector<>. Vector size is the number of inputs in a network except inputData input port. For each input, the input data type is std::vector float. |
| xml | std::string | The IE model file, which includes the file path. The file must be xml format. |
| rawDetectionResults | std::vector<std::vector float > | The inference results. For some networks, they have more than one output port. This parameter is defined to std::vector<>. The vector size is the number of output ports. Each item in the vector is a pointer, which points to one output result(std::vector float ), this vector is the inference result of one output port. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
-
- example
std::string model_file = "./models/frozen_infer_1_setence.xml";
std::vector<float> rawDetectionResult;
std::vector<std::vector<float>> additionalInput;
std::vector<std::vector<float>*> rawDetectionResults;
rawDetectionResults.push_back(&rawDetectionResult);
std::vector<float> text_feature;
std::shared_ptr<std::vector<float>> encoder_frame_ptr =
std::make_shared<std::vector<float>>(text_feature);
std::vector<std::shared_ptr<std::vector<float>>> encoder_vectors;
encoder_vectors.push_back(encoder_frame_ptr);
std::vector<float> y_hat(200*400, 0.0f);
additionalInput.push_back(y_hat);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
int res = vino_ie_pipeline_infer_common(encoder_vectors, additionalInput, model_file, rawDetectionResults, urlInfo);
-
- Note
video API
This API is used to run inference for video streaming. The video API includes two APIs: one is used for initializing models, another is used for running inference.
-
- APIs
/**
* @brief Initialization before video inference
* @param modelXmlFile Path of IE model file(xml)
* @param deviceName Inference on which device: CPU, GPU or others
* @return Status code of inference
*/
int vino_ie_video_infer_init(const std::string& modelXmlFile,
const std::string& deviceName);
/**
* @brief Do inference for video frame
* @param frame Image frame input for network
* @param additionalInput Other inputs of network(except image input)
* @param modelXmlFile Path of IE model file(xml)
* @param rawDetectionResults Outputs of network, they are raw data.
* @return Status code of inference
*/
int vino_ie_video_infer_frame(const cv::Mat& frame,
std::vector<std::vector<float>>& additionalInput,
const std::string& modelXmlFile,
std::vector<std::vector<float>*>& rawDetectionResults);
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| modelXmlFile | std::string | The IE model file, which includes the file path. The file must be xml format. |
| deviceName | std::string | Inference device. This parameter selects inference devices, XPU(CPU, GPU, or others). |
| frame | cv::Mat | Input video frame. Only one frame data, not support batch. |
| rawDetectionResults | std::vector<std::vector float > | The inference results. For some networks, they have more than one output port. This parameter is defined to std::vector<>. The vector size is the number of output ports. Each item in the vector is a pointer, which points to an output data(std::vector float ), this vector is the inference result of one output port. |
| additionalInput | std::vector<std::vector float > | For some networks, they have more than one input. This parameter is used for other inputs except image input. The type is also std::vector<>. Vector size is the number of inputs in a network except the image input port. For each input, the input data type is std::vector float . |
-
- example
std::string img_file = "./models/person-detection-retail-0013.png";
std::string model_file = "./models/person-detection-retail-0013.xml";
std::vector<float> rawDetectionResult;
std::vector<std::vector<float>> additionalInput;
std::vector<std::vector<float>*> rawDetectionResults;
rawDetectionResults.push_back(&rawDetectionResult);
cv::Mat frame = cv::imread(img_file, cv::IMREAD_COLOR);
vino_ie_video_infer_init(model_file, "CPU");
int frame_num = 10;
int i = 0;
while (i++ < frame_num) {
……………..
rawDetectionResult.clear();
vino_ie_video_infer_frame(frame, additionalInput, model_file,
rawDetectionResults);
………………
}
-
- notice
- (1) No policy logic in this API. The setting of policy API has no impact on this API.
- (2) It has only one working mode, local mode. Doesn’t have proxy mode.
simulative OV lib API
This API is used to communicate with simulative OV lib. Simulative OV lib is the front-end application, while the runtime service library works as a back-end service. The front-end(the simulative OV lib) calls this API to run inference on the back-end.
This case includes two APIs, one is used for initializing models, another is used for inference.
-
- APIs
/**
* @brief Initialization before doing simulate IE inference
* @param modelXmlFile Path of IE model file(xml)
* @param batch Batch size used in this model
* @param deviceName Inference on which device: CPU, GPU or others
* @param gnaScaler Scale factor used in GNA devices
* @param IOInformation IO information of the model. Returned to the caller
* @return Status code of inference
*/
int vino_simulate_ie_init(const std::string& modelXmlFile,
uint32_t& batch, //default=1
const std::string& deviceName,
uint32_t gnaScaler,
struct mock_data& IOInformation);
/**
* @brief Do inference for simulate IE
* @param audioData The speech data ready to do inference
* @param modelXmlFile Path of IE model file(xml)
* @param rawScoreResults Outputs of network, they are raw data.
* @return Status code of inference. It’s the StatusCode of OpenVino, such as
* OK, GENERAL_ERROR, INFER_NOT_STARTED or other values.
*/
int vino_simulate_ie_infer(std::vector<float>& audioData,
const std::string& modelXmlFile,
std::vector<float>& rawScoreResults);
-
- parameters
/**
* @brief Interface data structure between simulation IE lib and real IE container
* simulation IE lib <<----- mock data interface ------>> fcgi/gRPC + real IE (OV container)
* It includes input/output information about the model.
*/
using mock_InputsDataMap = std::map<std::string, std::vector<unsigned long>>; // <name, getDims()>
using mock_OutputsDataMap = std::map<std::string, std::vector<unsigned long>>; // <name, getDims()>
struct mock_data {
mock_InputsDataMap inputBlobsInfo;
mock_OutputsDataMap outputBlobsInfo;
uint8_t layout; // NCHW = 1, NHWC = 2 ... must do mapping between uint8_t and enum type
};
Struct mock_data includes the IO information of the network. IO information is required by the simulative OV lib. It is filled by the runtime inference library, and returned to simulative OV lib.
mock_InputsDataMap is defined as a map, std::map<std::string, std::vector<unsigned long>>. It’s the input information of the network. In this map, the KEY is the input name, and the VALUE is the input dimension.
mock_OutputsDataMap Same as mock_InputsDataMap, it is also defined as a map: std::map<std::string, std::vector<unsigned long>>. It’s the output information of the network.
| Parameters | Type | Comments |
|---|---|---|
| modelXmlFile | std::string | The IE model file, which includes the file path. The file must be xml format. |
| batch | uint32_t | The batch size. |
| deviceName | std::string | This parameter selects inference devices, XPU(CPU, GPU, or GNA_AUTO). |
| gnaScaler | uint32_t | This is a specific parameter for the GNA plugin. Not used in other plugins. |
| IOInformation | struct mock_data | IO information of the network. Returned to the caller. |
| audioData | std::vector float | Speech data vector inputted for inference. |
| rawScoreResults | std::vector float | The inference results. Only support one output pin. |
-
- example
//The first init stage: get IO information
std::string model_file = "./models/wsj_dnn5b.xml";
uint32_t batch = 8;
std::string device;
struct mock_data io_information;
vino_simulate_ie_init(model_file, batch, device, 0, io_information);
//The second init stage: set inference device
device = "CPU";
vino_simulate_ie_init(model_file, batch, device, 0, io_information);
//inference
std::vector<float>& input_float ;
std::vector<float> output_float;
StatusCode status = vino_simulate_ie_infer(input_float, model_file, output_float);
-
- notice
- (1) No policy logic in this API. The setting of policy API has no impact on this API.
- (2) It has only one working mode, local mode. Doesn’t have proxy mode.
Load Openvino Model from Buffer API
This api is used for loading a Openvino model from a buffer. In some cases, the Openvino model isn’t a file in the disk, it is located in the memory buffer. For these cases, we need to call this api to initialize the Openvino model.
-
- API
/**
* @brief Initial, load model from buffer
* @param xmls a unique string to handle the inference entity
* @param model model buffer
* @param weights weights buffer
* @param batch batch size
* @param isImgInput whether input of model is image
* @return Status code
*/
int vino_ie_pipeline_init_from_buffer(std::string xmls,
const std::string &model,
const std::string &weights,
int batch,
bool isImgInput);
-
- Parameter
| Parameters | Type | Comments |
|---|---|---|
| xmls | std::string | a unique string to represent IE model |
| model | std::string | The memory buffer which includes the IE model. |
| weights | std::string | This memory buffer which includes the weight data. |
| batch | int | The batch size. |
| isImgInput | bool | Whether the input of the model is image data. |
0 Video pipeline management (construct) API
This set of APIs will help developers construct their own video pipelines and manage those pipelines in their life cycle.
This function below initializes the video pipeline environment. It should be called before calling other APIs. return value, 0 means success, non-zero means failure.
-
- API
int ccai_stream_init();
This function below creates a video pipeline. pipeline_name is a string which should be supported by a video pipeline plugin, such as “launcher.object_detection”. user_data is plugin defined, and should be supported by the plugin.
This function returns a pointer to a ccai_stream_pipeline or NULL if the pipeline cannot be created.
-
- API
struct ccai_stream_pipeline *ccai_stream_pipeline_create(const char* pipeline_name,
void *user_data);
-
- Parameter
| Parameters | Type | Comments |
|---|---|---|
| pipeline_name | const char * | pipeline namel |
| user_data | void * | plugin defined, supported by the plugin |
This function below starts a video pipeline. The pipe should be returned by ‘ccai_stream_pipeline_create’. user_data is plugin defined, and should be supported by the plugin. return value, 0 means success, non-zero means failure.
-
- API
int ccai_stream_pipeline_start(struct ccai_stream_pipeline *pipe, void *user_data);
-
- Parameter
| Parameters | Type | Comments |
|---|---|---|
| pipeline_name | const char * | pipeline namel |
| user_data | void * | plugin defined, supported by the plugin |
This function below stops a video pipeline. pipe should be returned by ‘ccai_stream_pipeline_create’. user_data is plugin defined, and should be supported by the plugin. return value, 0 means success, non-zero means failure.
-
- API
int ccai_stream_pipeline_stop(struct ccai_stream_pipeline *pipe, void *user_data);
-
- Parameter
| Parameters | Type | Comments |
|---|---|---|
| pipeline_name | const char * | pipeline namel |
| user_data | void * | plugin defined, supported by the plugin |
This function below removes a video pipeline. pipe should be returned by ‘ccai_stream_pipeline_create’. user_data is plugin defined, and should be supported by the plugin. return value, 0 means success, non-zero means failure.
-
- API
int ccai_stream_pipeline_remove(struct ccai_stream_pipeline *pipe, void *user_data);
-
- Parameter
| Parameters | Type | Comments |
|---|---|---|
| pipeline_name | const char * | pipeline namel |
| user_data | void * | plugin defined, supported by the plugin |
Live ASR API
ASR means Automatic Speech Recognition, speech-to-text. This API is implemented based on some Intel speech libraries. This API is similar to the ASR API(10.4.1.5). The difference is that this API does continuous inference and outputs the text while the previous ASR API only does one time inference.
-
- API
/**
* @brief Continuously do inference for speech (ASR). Using intel speech libraries.
* @param mode Working status of ASR. Start/inference/stop
* @param samples Speech data buffer.
* @param sampleLength Buffer size of speech data
* @param bytesPerSample Size for each speech sample data (how many bytes for each sample)
* @param rh_utterance_transcription Text result of speech. (ASR result)
* @param config_path The file path for configuration file.
* @param device The inference device.
* @return Status code of inference
*/
int vino_ie_pipeline_infer_speech(int mode, // 1 -- start 2 -- inference 0 -- stop
const short* samples,
int sampleLength,
int bytesPerSample,
std::string config_path,
std::string device,
std::vector<char> &rh_utterance_transcription);
-
- parameters
| Parameter | Type | Comments |
|---|---|---|
| mode | int | The working mode of the ASR process. 0 - stop to do inference 1 - start to do inference 2 - do inference |
| samples | short int | speech data, which format is PCM data. Each short int data is one PCM sample. |
| sampleLength | int | The size of speech data |
| bytesPerSample | int | the bytes number for each speech sample data. For PCM data, the value should be 2, which means each PCM sample is two bytes. |
| config_path | std::string | The configuration file for the ASR model. This configuration file is used by intel speech libraries |
| rh_utterance_transcription | std::vector char | the inference result for speech data. The data format is char. |
| device | std::string | The inference device: CPU or GNA |
Samples, sampleLength, and bytesPerSample are often obtained by parsing the header of a wave file.
-
- example
std::string wave_filename = "./models/how_are_you_doing.wav";
std::string config_filename = "./models/lspeech_s5_ext/FP32/speech_lib.cfg";
short* samples = nullptr;
int sampleLength = 0;
int bytesPerSample = 0;
unsigned int size = 0;
uint8_t* wave_data = ReadBinaryFile(wave_filename.c_str(), &size);
parseWaveFile(wave_data, size, samples, sampleLength, bytesPerSample);
std::vector<char> rh_utterance_transcription(1024 * 1024);
// starting live asr mode (mode==1)
int res = vino_ie_pipeline_live_asr(1, samples, sampleLength, bytesPerSample, config_filename, "CPU", rh_utterance_transcription);
// do inference (mode==2)
res = vino_ie_pipeline_live_asr(2, samples, sampleLength, bytesPerSample, config_filename, "CPU", rh_utterance_transcription);
// stopping live asr mode(mode==0)
res = vino_ie_pipeline_live_asr(0, samples, sampleLength, bytesPerSample, config_filename, "CPU", rh_utterance_transcription);
-
- Notice
This ASR model only supports English, not Chinese.
Python API
Runtime service library also provides some python APIs to upper layers. These python APIs can be called by python APPs directly.
Python API provides the same functions as C++ API. So they are mapped one-on-one to the C++ APIs.
Python is a different language from C++, so the data structures used in python APIs are also different from C++ data structures. The following table lists the mapping of data structures between two languages.
| Python | C++ |
|---|---|
| serverParams | struct serverParams |
| userCfgParams | struct userCfgParams |
| vectorChar | Std::vector char |
| vectorFloat | Std::vector float |
| vectorVecFloat | Std::vector<std::vector float > |
Image API
-
- API
infer_image(image, image_channel, additionalInput, xmls, rawDetectionResults,
remoteServerInfo)
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| image | List[List[int]] | The image data. The data format of the image is list[int], and each image is expressed in one list[]. The outer list[] means batch images. The outer list length is batch size. The inner list[] is the image data. |
| Image_channel | int | This parameter defines the channels of the input image. For example: 3 – rgb, 1 – h |
| AdditionalInput | vectorVecFloat | Other inputs except image input. The meaning is the same as C++ API |
| Xmls | str | IE model file. The meaning is the same as C++ API. |
| rawDetectionResults | vectorVecFloat | The inference results. The meaning is the same as C++ API. |
| remoteServerInfo | serverParams | Server parameter. This is used in proxy mode. The meaning is the same as C++ API. |
-
- example
import inferservice_python as rt_api
model_xml = "./models/person-detection-retail-0013.xml"
pic = list(pic)
pics = [pic] # pics should be list[list], [[],[],[]]
other_pin = rt_api.vectorVecFloat()
out1 = rt_api.vectorFloat()
out = rt_api.vectorVecFloat()
out.append(out1)
urlinfo = rt_api.serverParams()
urlinfo.url = 'https://www.baidu.com/s'
urlinfo.urlParam = 'f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg'
res = rt_api.infer_image(pics, 3, other_pin, model_xml, out, urlinfo)
-
- Notice
The usage of this API is the same as C++ image API.
ASR API
-
- API
infer_speech(samples, bytesPerSample, config_path, rh_utterance_transcription,
remoteServerInfo)
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| samples | List[int] | speech data, which format is PCM data. Each PCM sample is one short int data. |
| bytesPerSample | int | the bytes number for each speech sample data. For PCM data, the value should be 2, which means each sample data includes two bytes. |
| config_path | str | The configuration file for the ASR model. This configuration file is used by intel speech libraries |
| rh_utterance_transcription | vectorChar | the inference result for speech data. The data format is char. |
| remoteServerInfo | serverParams | Server parameter. This is used in proxy mode. The meaning is the same as C++ API. |
-
- example
import inferservice_python as rt_api
model_xml = './models/lspeech_s5_ext/FP32/speech_lib.cfg'
speech, samplewidth = parse_wavefile()
buf = np.zeros((100*100), dtype = np.int8)
utt_res = rt_api.vectorChar(buf)
urlinfo = rt_api.serverParams()
urlinfo.url = 'https://www.baidu.com/s'
urlinfo.urlParam = 'f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg'
res = rt_api.infer_speech(speech, sampwidth, model_xml, utt_res, urlinfo)
-
- Notice
The usage of this API is the same as C++ ASR API.
Common API
This API is also called TTS API. It can be used in TTS cases.It is mapped to C++ common API, vino_ie_pipeline_infer_common().
-
- API
infer_tts(inputData, additionalInput, xml, rawDetectionResults, remoteServerInfo);
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| inputData | vectorVecFloat | The input data for the network. Same as C++ API. |
| additionalInput | vectorVecFloat | Other inputs except inputData pin. Same as C++ API. |
| xml | str | The IE model file, which includes the file path. The file must be xml format. |
| rawDetectionResults | vectorVecFloat | The inference results. Same as C++ API. |
| remoteServerInfo | serverParams | Server parameter. This is used in proxy mode. Same as C++ API. |
-
- example
import inferservice_python as rt_api
model_xml = “./models/tts-encoder-decoder.xml”
input_data = rt_api.vectorVecFloat()
x_pin = rt_api.vectorFloat(tts_data)
input_data.append(x_pin)
other_pin = rt_api.vectorVecFloat()
y_pin = rt_api.vectorFloat(other_pin_data)
other_pin.append(y_pin)
out1 = rt_api.vectorFloat()
out = rt_api.vectorVecFloat()
out.append(out1)
urlinfo = rt_api.serverParams()
urlinfo.url = 'https://www.baidu.com/s'
urlinfo.urlParam = 'f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg'
res = rt_api.infer_tts(input_data, other_pin, model_xml, out, urlinfo)
-
- Notice
The usage of this API is the same as C++ common API.
Policy configuration API
-
- API
set_policy_params(configuration);
-
- parameter
| Parameters | Type | Comments |
|---|---|---|
| Configuration | userCfgParams | Same as C++ struct userCfgParams. |
-
- example
import inferservice_python as rt_api
#configuration:
cfg_info = rt_api.userCfgParams()
cfg_info.isLocalInference = True
cfg_info.inferDevice = 'CPU'
res = rt_api.set_policy_params(cfg_info)
-
- Notice
The usage of this API is the same as C++ policy configuration API.
Live ASR API
-
- API
live_asr(mode, samples, bytesPerSample, config_path, device, rh_utterance_transcription)
-
- parameters
| Parameters | Type | Comments |
|---|---|---|
| mode | int | The working mode of the ASR process. 0 - stop to do inference 1 - start to do inference 2 - do inference |
| samples | List[int] | speech data, which format is PCM data. Each PCM sample is one short int data. |
| bytesPerSample | int | the bytes number for each speech sample data. For PCM data, the value should be 2, which means each sample data includes two bytes. |
| config_path | str | The configuration file for the ASR model. This configuration file is used by intel speech libraries |
| rh_utterance_transcription | vectorChar | the inference result for speech data. The data format is char. |
| device | std::string | The inference device: CPU or GNA |
-
- example
import inferservice_python as rt_api
model_xml = './models/lspeech_s5_ext/FP32/speech_lib.cfg'
speech, samplewidth = parse_wavefile()
buf = np.zeros((100*100), dtype = np.int8)
utt_res = rt_api.vectorChar(buf)
device = “CPU”
mode = 1 ## starting inference
res = rt_api.live_asr(mode, speech, sampwidth, model_xml, device, utt_res)
mode = 2 ## doing inference
res = rt_api.live_asr(mode, speech, sampwidth, model_xml, device, utt_res)
mode = 0 ## stopping inference
res = rt_api.live_asr(mode, speech, sampwidth, model_xml, device, utt_res)
-
- Notice
The usage of this API is the same as C++ Live ASR API.
C++ APIs for Different backend Engines (Version 1)
This set of C++ APIs(version 1) are the superset of the set of C++ APIs for Openvino backend engines (version 0). The difference between two versions is that version 1 supports different inference engines, such as Openvino, Pytorch, Onnx, and Tensorflow. You can use APIs in version 1 to do the same things as APIs in version0.
C++ APIs of version 1 are “standard” c++ APIs. In the future, some of the APIs in version 0 will be obselete. I encourage you to try to use C++ APIs in version 1.
Return Value
/**
*@enum irtStatusCode
*@brief Status code of running inference
*/
enum irtStatusCode : int {
RT_REMOTE_INFER_OK = 1, //inference successfully on remote server
RT_LOCAL_INFER_OK = 0, //inference successfully on local HW
RT_INFER_ERROR = -1 //inference error
};
Some APIs have two working modes. One mode is local mode, which means doing inference on local XPU. Another is proxy mode. In proxy mode, API forwards requests to the remote server (such as QQ server or Tecent server). The remote server runs inference, and returns the result.
In local mode, the return value is
RT_LOCAL_INFER_OK (success) or RT_INFER_ERROR (failure).
In proxy mode, the return value is
RT_REMOTE_INFER_OK (success) or RT_INFER_ERROR(failure)
Inference Engines
Currently, runtime libraries support four inference engines, they are Openvino, Pytorch, Onnx and Tensorflow..
/**
*@enum irtInferenceEngine
*@brief Inference engines supported in inference runtime library.
* Currently inference engines are Openvino and Pytorch.
*/
enum irtInferenceEngine : uint8_t {
OPENVINO = 0,
PYTORCH,
ONNXRT,
TENSORFLOW
};
Image API
The usage of this API is the same as image API in version 0.
-
- API
/**
* @brief Run inference from image
* @param tensorData Buffers for input/output tensors
* @param modelFile The model file, include path
* @param backendEngine Specify the inference engine, OpenVINO or pytorch.
* @param remoteSeverInfo Parameters to do inference on remote server
* @return Status code of inference
*/
enum irtStatusCode irt_infer_from_image(struct irtImageIOBuffers& tensorData,
const std::string& modelFile,
const enum irtInferenceEngine backendEngine,
struct serverParams& remoteServerInfo);
-
- parameters
/**
* @brief Buffers for running inference from image.
* Includes pointers pointing to the input/output tensors data.
* @There are two kinds of inputs, one is image inputs, another is assistant inputs.
* The image input tensor is represents by vector<vector<vector_shared_ptr>>>,
* means [ports_number, batch, one_image_data]. It is expressed by
* <ports_number<batch<one_image_data>>>.
* The inner vector is a shared pointer pointing to a vector(one_image_data).
* The outer vector.size() means the number of image input ports.
* The middle vector means batch.
* The assistant input tensor is represent by vector<vector<float>>, means
* [ports_number, one_data_array].
* @The output tensor is represented by vector<vector_pointers>.
* The output tensor is [ports_number, one_data_arry]. It is expressed by
* <ports_number<one_data_arry>>.
* The inner vector is a pointer which points to a vector(one_data_array). This vector
* includes the return value passed back by API.
* The outer vector.size() means output ports number of the model.
*/
struct irtImageIOBuffers {
/* Pointer points to the image input data. The inner shared pointer points to CV:Mat data */
std::vector<std::vector<ptrCVImage>> *pImageInputs;
/* Pointer points to the assistant input data. */
std::vector<std::vector<float>> *pAdditionalInputs;
/* Pointer points to the output buffer. The inner pointer points to the result inferenced by runtime API */
std::vector<std::vector<float>*> *pInferenceResult;
};
| Parameter | Type | Comments |
|---|---|---|
| tensorData | irtImageIOBuffers | Buffers for input/output tensors |
| modelFile | std::string | The model file, which includes the file path. |
| backendEngine | irtInferenceEngine | Specify the inference engine, OpenVINO, Pytorch, Onnx runtime or Tensorflow. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
-
- example
std::string img_file = "./models/person-detection-retail-0013.png";
std::string model_file = "./models/person-detection-retail-0013.xml";
std::vector<float> rawDetectionResult;
std::vector<std::vector<float>> additionalInput;
std::vector<std::vector<float>*> rawDetectionResults;
rawDetectionResults.push_back(&rawDetectionResult);
std::vector<std::shared_ptr<cv::Mat>> images;
std::shared_ptr<cv::Mat> frame_ptr = std::make_shared<cv::Mat>(cv::imread(img_file, cv::IMREAD_COLOR));
images.push_back(frame_ptr);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg"; // = "test";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
std::vector<std::vector<ptrCVImage>> images_vecs;
images_vecs.push_back(images);
images.clear();
struct irtImageIOBuffers modelAndBuffers{&images_vecs, &additionalInput,
&rawDetectionResults};
enum irtStatusCode res = irt_infer_from_image(modelAndBuffers, model_file,
OPENVINO, urlInfo);
Speech API
The usage of this API is the same as ASR API in version 0.
-
- API
/**
* @brief Run inference from speech(ASR)
* @param waveData Parameters for speech data, includes data buffer and settings.
* @param configurationFile The configuration file, includes path
* @param inferenceResult Text result of speech. (ASR result)
* @param backendEngine Specify the inference engine, OpenVINO or pytorch.
* @param remoteSeverInfo Parameters to do inference on remote server
* @return Status code of inference
*/
enum irtStatusCode irt_infer_from_speech(const struct irtWaveData& waveData,
std::string configurationFile,
std::vector<char>& inferenceResult,
const enum irtInferenceEngine backendEngine,
struct serverParams& remoteServerInfo);
-
- parameter
/**
* @brief Parameters for wave data. Used by running inference for speech.
* Wave data is PCM data.
*/
struct irtWaveData {
/* Pointer points to PCM data. */
short* samples;
/* PCM data length. */
int sampleLength;
/* Size of each PCM sample. */
int bytesPerSample;
};
| Parameter | Type | Comments |
|---|---|---|
| waveData | irtWaveData | Parameters for speech data, includes speech data buffer and definitions. |
| configurationFile | std::string | The configuration file for the ASR model. Including path. |
| inferenceResult | std::vector char | Text result of inference. The data format is char. |
| backendEngine | irtInferenceEngine | Specify the inference engine, OpenVINO, Pytorch, Onnx runtime and Tensorflow. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
-
- example
std::string wave_filename = "./models/how_are_you_doing.wav";
std::string config_filename = "./models/lspeech_s5_ext/FP32/speech_lib.cfg";
short* samples = nullptr;
int sampleLength = 0;
int bytesPerSample = 0;
unsigned int size = 0;
uint8_t* wave_data = ReadBinaryFile(wave_filename.c_str(), &size);
parseWaveFile(wave_data, size, samples, sampleLength, bytesPerSample);
std::vector<char> rh_utterance_transcription(1024 * 1024);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
struct irtWaveData sampleData{samples, sampleLength, bytesPerSample};
enum irtStatusCode res = irt_infer_from_speech(sampleData, config_filename,
rh_utterance_transcription, OPENVINO, urlInfo);
Common API
The usage of this API is the same as the common API in version 0.
-
- API
/**
* @brief Run inference from common model
* @param tensorData Buffers for input/output tensors
* @param modelFile The model file, include path
* @param backendEngine Specify the inference engine, OpenVINO or pytorch.
* @param remoteSeverInfo Parameters to do inference on remote server
* @return Status code of inference
*/
enum irtStatusCode irt_infer_from_common(struct irtFloatIOBuffers& tensorData,
const std::string& modelFile,
const enum irtInferenceEngine backendEngine,
struct serverParams& remoteServerInfo);
-
- parameter
/*
* @brief Buffers for running inference from common model.
* The structure is similar with irtImageIOBuffers, except the type of shared pointer is float,
* not CV::Mat.
*/
struct irtFloatIOBuffers {
/* Pointer points to main input data. The inner shared pointer points to float data */
std::vector<std::vector<ptrFloatVector>> *pMainInputs;
/* Pointer points to the assistant input data. */
std::vector<std::vector<float>> *pAdditionalInputs;
/* Pointer points to the output buffer. The inner pointer points to the result inferenced by
runtime API */
std::vector<std::vector<float>*> *pInferenceResult;
};
| Parameter | Type | Comments |
|---|---|---|
| tensorData | irtFloatIOBuffers | Buffers for input/output tensors |
| modelFile | std::string | The model file, which includes the file path. |
| backendEngine | irtInferenceEngine | Specify the inference engine, OpenVINO, Pytorch, Onnx runtime and Tensorflow. |
| remoteServerInfo | struct serverParams | Server parameter. This is used in proxy mode. Please refer to 1.2 for detailed information. |
-
- example
std::string encoder_model_file = "./models/text-spotting-0001-recognizer-encoder.xml";
std::vector<std::vector<float>> additionalInput;
std::vector<float> rawDetectionResult;
std::vector<std::vector<float>*> rawDetectionResults;
rawDetectionResults.push_back(&rawDetectionResult);
std::string param = "f=8&rsv_bp=1&rsv_idx=1&word=picture&tn=98633779_hao_pg";
struct serverParams urlInfo{"https://www.intel.cn/index.html", param};
std::vector<float> text_features;
std::shared_ptr<std::vector<float>> encoder_frame_ptr =
std::make_shared<std::vector<float>>(text_feature);
std::vector<std::shared_ptr<std::vector<float>>> encoder_images;
encoder_images.push_back(encoder_frame_ptr);
std::vector<std::vector<ptrFloatVector>> mainInputs;
mainInputs.push_back(encoder_images);
struct irtFloatIOBuffers buffers{&mainInputs, &additionalInput, &rawDetectionResults};
enum irtStatusCode res = irt_infer_from_common(buffers, encoder_model_file, OPENVINO,
urlInfo);
How to extend video pipeline with video pipeline manager
You can follow the steps below to implement a plugin to extend the video pipeline.
construct the plugin
#include <ccai_stream_plugin.h>
#include <ccai_stream_utils.h>
#include <gst/gst.h>
static const char *pipe_name = "sample";
static const char *gst_pipeline_desc = "videotestsrc ! ximagesink";
/* 4. implement create/start/stop/remove function */
static int create_pipe(struct ccai_stream_pipeline_desc *desc, void *user_data)
{
if (desc == NULL)
return -1;
desc->private_data = gst_parse_launch(gst_pipeline_desc, NULL);
if (!desc->private_data)
return -1;
return 0;
}
static int start_pipe(struct ccai_stream_pipeline_desc *desc, void *user_data)
{
if (desc == NULL || desc->private_data == NULL)
return -1;
GstElement *gst_pipe = (GstElement *)desc->private_data;
ccai_gst_start_pipeline(gst_pipe);
return 0;
}
static int stop_pipe(struct ccai_stream_pipeline_desc *desc, void *user_data)
{
if (desc == NULL || desc->private_data == NULL)
return -1;
GstElement *gst_pipe = (GstElement *)desc->private_data;
if (gst_pipe == NULL)
return -1;
ccai_gst_stop_pipeline(gst_pipe);
return 0;
}
static int remove_pipe(struct ccai_stream_pipeline_desc *desc, void *user_data)
{
if (desc == NULL || desc->private_data == NULL)
return -1;
GstElement *gst_pipe = (GstElement *)desc->private_data;
if (gst_pipe) {
gst_object_unref(gst_pipe);
desc->private_data = NULL;
}
return 0;
}
/* 2. implement init/exit function */
static int sample_plugin_init()
{
struct ccai_stream_pipeline_desc *desc;
/* 3. new a ccai_stream_pipeline_desc */
if ((desc = g_try_new0(struct ccai_stream_pipeline_desc, 1)) == NULL)
return -1;
desc->name = pipe_name;
desc->create = create_pipe;
desc->start = start_pipe;
desc->stop = stop_pipe;
desc->remove = remove_pipe;
desc->get_gst_pipeline = NULL;
desc->private_data = NULL;
ccai_stream_add_pipeline(desc);
return 0;
}
static void sample_plugin_exit()
{
}
/* 1. define a plugin */
CCAI_STREAM_PLUGIN_DEFINE(sample, "1.0",
CCAI_STREAM_PLUGIN_PRIORITY_DEFAULT,
sample_plugin_init, sample_plugin_exit)
In the source code, you must call or implement the following functions:
- CCAI_STREAM_PLUGIN_DEFINE
Call this function to define a plugin, the video pipeline manager will load this plugin according to the information provided by this definition.
- Implement init/exit function
The video pipeline manager will call init when the plugin is loaded, and call exit when the plugin is unloaded.
-
Call ccai_stream_add_pipeline in the init function, ccai_stream_add_pipeline will register the pipeline supported by the plugin to the video pipeline manager.
-
4.Implement create/start/stop/remove function. When a client requests to start or stop a pipeline, the video pipeline manager will call those functions.
Build the plugin
gcc `pkg-config --cflags gstreamer-1.0` -g -O2 plugin_sample.c -o sample.so \
`pkg-config --libs gstreamer-1.0` -shared -lccai_stream
Install the plugin to destination
sudo cp sample.so /usr/lib/ccai_stream/plugins/
Test your plugin
sv restart lighttpd
$ curl -H "Content-Type:application/json" -X POST http://localhost:8080/cgi-bin/streaming - '{"pipeline":"sample", "method":"start"}'
$ curl -H "Content-Type:application/json" -X POST http://localhost:8080/cgi-bin/streaming - '{"pipeline":"sample", "method":"stop"}'